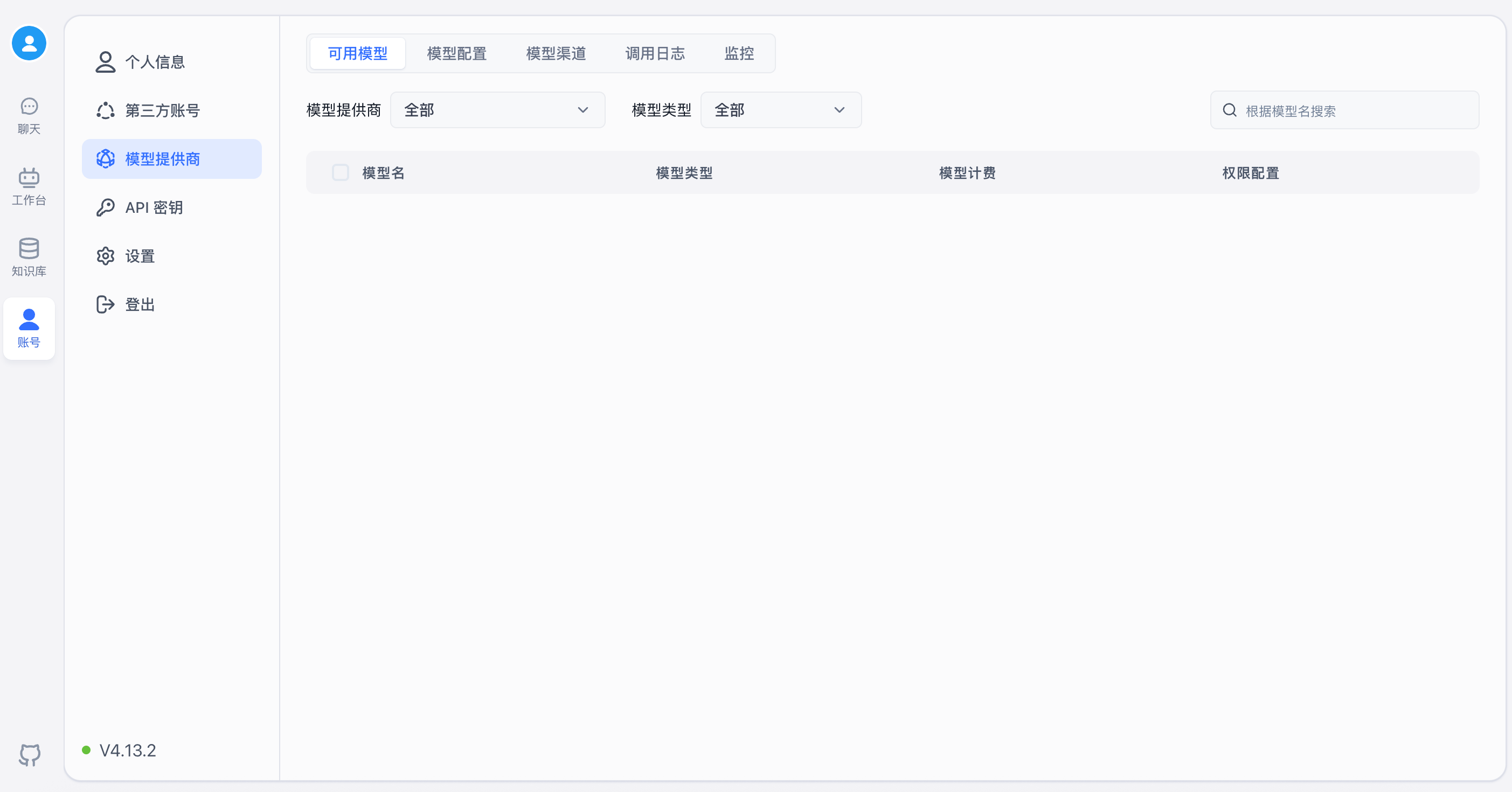
AI工具FastGPT知识库的部署
FastGPT 是一个基于 LLM 大语言模型的知识库问答系统,提供开箱即用的数据处理、模型调用等能力。同时可以通过 Flow 可视化进行工作流编排,从而实现复杂的问答场景!
官方文档如下所示:
https://doc.tryfastgpt.ai/docs/intro/
FastGPT的能力如下:
1. 专属 AI 客服(很多公司目前都在用)
通过导入文档或已有问答对进行训练,让 AI 模型能根据你的文档以交互式对话方式回答问题。
2. 简单易用的可视化界面
FastGPT 采用直观的可视化界面设计,为各种应用场景提供了丰富实用的功能。通过简洁易懂的操作步骤,可以轻松完成 AI 客服的创建和训练流程。
3. 自动数据预处理
提供手动输入、直接分段、LLM。自动处理和 CSV 等多种数据导入途径,其中“直接分段”支持通过 PDF、WORD、Markdown 和 CSV
文档内容作为上下文。FastGPT 会自动对文本数据进行预处理、向量化和 QA 分割,节省手动训练时间,提升效能。
4. 工作流编排
基于 Flow 模块的工作流编排,可以帮助你设计更加复杂的问答流程。例如查询数据库、查询库存、预约实验室等。
5. 强大的 API 集成
FastGPT 对外的 API 接口对齐了 OpenAI 官方接口,可以直接接入现有的 GPT 应用,也可以轻松集成到企业微信、公众号、飞书等平台。
FastGPT的特点如下:
独特的 QA 结构
针对客服问答场景设计的 QA 结构,提高在大量数据场景中的问答准确性。
可视化工作流
通过 Flow 模块展示了从问题输入到模型输出的完整流程,便于调试和设计复杂流程。
无限扩展
基于 API 进行扩展,无需修改 FastGPT 源码,也可快速接入现有的程序中。
便于调试
提供搜索测试、引用修改、完整对话预览等多种调试途径。
支持多种模型
支持 GPT、Claude、文心一言等多种 LLM 模型,未来也将支持自定义的向量模型。
然后再看看FastGPT的部署图:
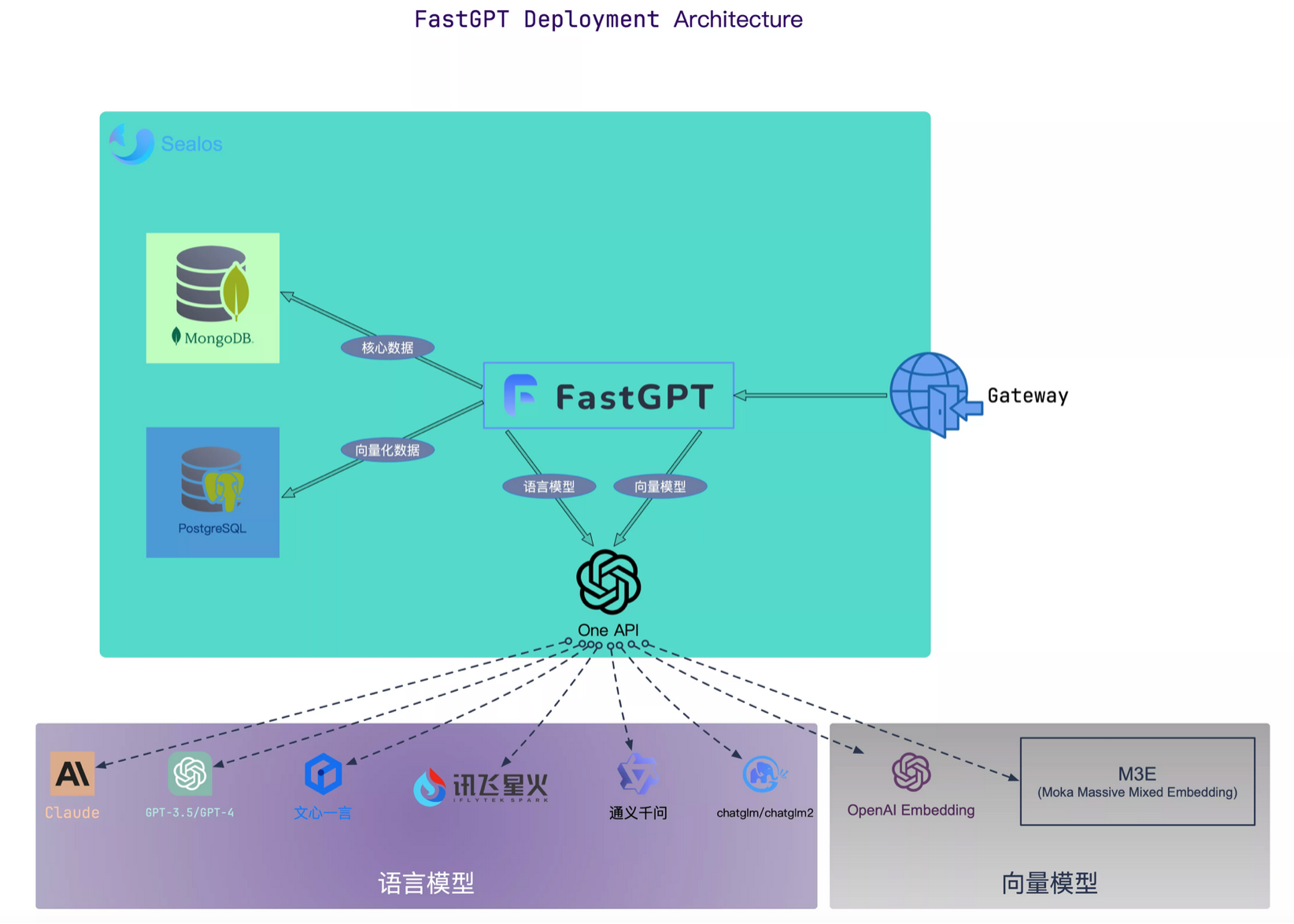
这个图中可以清晰的看到,FastGPT使用MongoDB数据库和PostgreSQL数据库作为依赖的存储,同时基于OneAPI实现大模型的统一对接。
各个组件的含义如下:
MongoDB:用于存储除了向量外的各类数据
PostgreSQL/Milvus:存储向量数据
OneAPI: 聚合各类 AI API,支持多模型调用 (任何模型问题,先自行通过 OneAPI 测试校验)
在安装之前,我们需要准备好Docker和Docker Compose的环境,然后参考官方部署文档进行安装:
https://doc.tryfastgpt.ai/docs/development/docker/
安装的第一步就是下载config.json文件和docker-compose.yml文件,这里参考官方文档的下载方式即可。下载完成后我们放到同一个目录中。
下载命令如下:
1 | mkdir fastgpt |
然后参考官方文档安装和启动依赖镜像
1 | # 启动容器 |
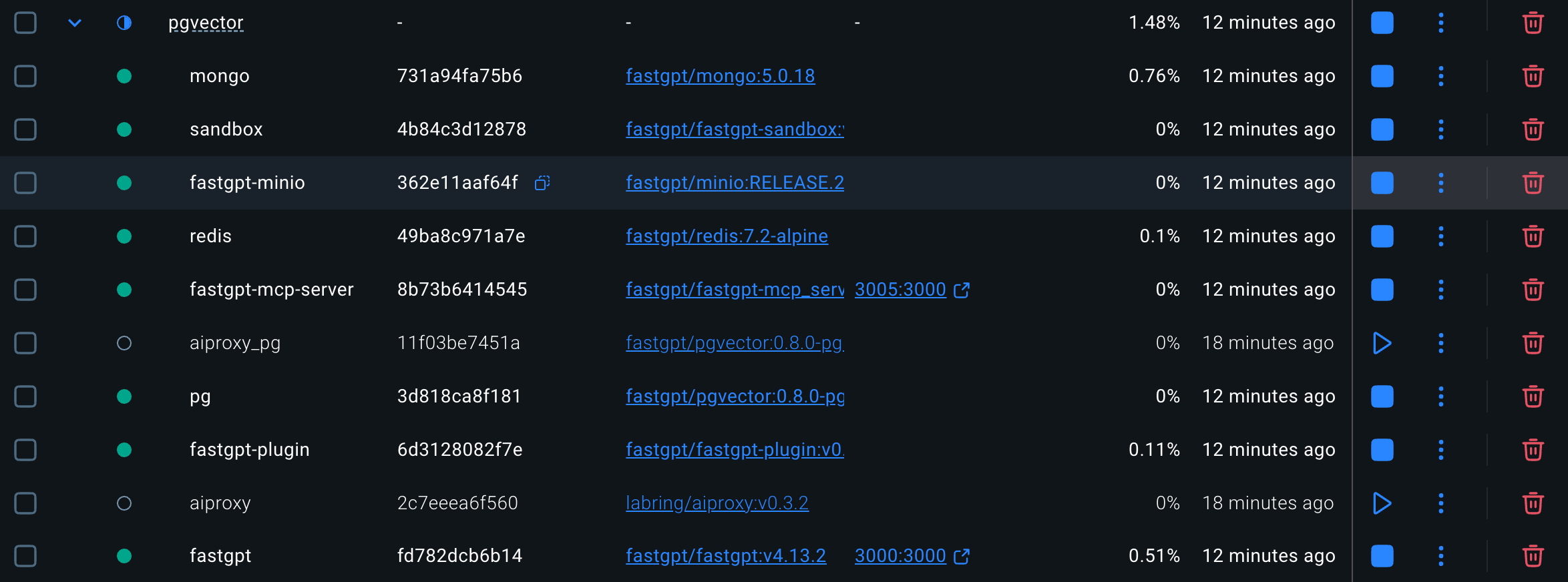
操作完成后,可以看到它会出现如下一些需要的容器实例,这里我用的是Mac版本的Docker:
然后我们访问下FastGPT,浏览器输入:http://localhost:3000,看到主界面如下所示:
首次运行,会自动初始化 root 用户,密码为 1234,我们进行登录,登录后的主界面如下所示: