
玩转AI应用1:AI实现代码评审
背景
如今AI浪潮来临,各个公司都在继续研究如何用AI实现研发提效,除了日常的使用各种IDE插件外,还有一个领域值得我们关注:AI自动代码CodeReview领域。
AI大模型的出现,解决了机器不能理解人类的核心需求的问题,我们只需要把要求和目标告诉AI,AI就可以实现我们的效果。而代码评审的AI能力也是我们需要关注的。
在企业中已经有越来越多的人开始使用AI进行辅助编程、代码优化与提效,但是仍然有很多小伙伴的团队没有执行CodeReview,隐藏和潜在的问题没有及时发现,导致线上问题频发,也有的小伙伴处于没互联网的情况下进行工作,无法使用AI进行代码提效与CodeReview。即使用了互联网的AI工具,可能也会出现公司代码的泄露,造成信息安全合规问题,公司内代码直接调 ChatGPT等等,说不定那一天真的出现了泄露。
也有的公司也有CodeReview了,但是每天在低质量代码耗费不少时间,每天至少N个 MR 需要 CR,虽然提交时 MR 经过 单测 + Lint 过滤了一些低级错误,但还有些问题(代码合理性、经验、MR 相关业务逻辑等)需要花费大量时间,如果我们可以通过AI先执行自动化 CR,再进行人工 CR,应该可以大大提升 CR 效率!甚至对于代码安全有所管控的公司,可以部署开源大模型,实现所有代码数据不出内网,所有推理过程均在内网完成。
在没有AI代码评审CodeReview的时候,大部分团队的 Code Review 停留在文档纸面上,成员之间口口相传,并没有一个工具根据规范来严格执行,所以没有形成习惯和常态,导致隔三差五的进行代码评审。
同时人为的代码评审,存在很多弊端:
时间消耗大:代码评审是一个耗时的过程,特别对于大型项目和复杂的代码更是如此。
无档期:评审者无时间会造成研发卡点。
一致性缺乏:不同的审查者可能会有不同的编码标准和偏好,这可能导致代码审查的反馈缺乏一致性,给开发者带来混淆。
可能遗漏错误:人为审查的过程中可能会因为疲劳、疏忽或知识限制而遗漏一些错误,尤其是对于难察觉的逻辑错误和性能问题。
主观性:代码审查很容易受到审查者个人偏好和情绪的影响,有时可能会导致不必要的争议。
基于以上内容,准备开始分享一点最近研究的AI大模型进行代码CodeReview的实现分享,希望可以帮助到每个人。
实现效果分享
1、先来看第一种效果:使用AI进行CodeReview后,可以完成的效果截图1,AI对我们提交的代码进行评审:
2、再来看看第二种效果:使用AI进行CodeReview后,我们可以在Gitlab仓库中看到AI评审的结果,评审结果直接显示在Gitlab的合并请求页面:
3、AI评审完成后,可以通过飞书的机器人API发送到飞书群进行消息通知,单击消息可以看到评审结果。
飞书卡片消息截图:
看到这里,有没有小伙伴想问,明明已经有很多AI工具了,可以实现这种效果,做这个应用层面的东西有啥用呢?
本质其实就是AI在企业中的落地与AI对于开发者自身的技术成长两个方面,如果是自己用,自己玩,怎么用都会觉得没问题,一旦你想把这个东西真正的用到工作中,用到个人的成长中,就会产生很多可以探索的东西。对于个人来说,可以增长AI技能,为下一份工作打下基础,对于企业来说,提高个人创新能力和技术落地能力和技术影响力。
实现方案
我想这个问题,应该是很多人关注的,目前业界基本上的实现方案和思路都是非常相似的,没有差多少,基本上如下:
总结起来就是如下操作:
1、通过某种机制获取到Git仓库中的代码或者变化的代码进行CodeReview
2、然后把需要的Code Review的代码发送给AI大模型
3、然后把AI大模型返回的CodeReview的结果,进行输出(文件、数据库、Gitlab评论区、飞书消息等等)
再次过程中为了提升质量,有些时间方案还会结合其他技术:RAG、AST、AI Agent、IDEA插件等等。
看到这个是不是感觉思路非常清晰呢,是不是有种似曾相识的感觉,没错,这就是把大象装进冰箱的三步解决办法。
那么归纳起来对于企业级的AI代码评审的图如下所示:。
和AI大模型结合起来的实现原理如下:
私有化部署AI大模型
Ollama工具安装
本文介绍的这个部署工具就是Ollama,Ollama是一个不收费的开源工具,它提供了预装好的大模型,免除了复杂的安装和下载流程,是一个开源的人工智能(AI)和机器学习(ML)工具平台,特别设计用于简化大型语言模型(LLM)的部署和使用流程。用户可以通过Ollama在本地环境中便捷地运行各种大型语言模型。
官网如下所示:https://ollama.com/
对于大多数新手而言,Ollama是最适合上手的部署框架,而且前段时间也推出了Windows版本的安装包,使用门槛大幅降低。在官网下载并安装完成后就会自动弹出命令提示符,因为Ollama官方就有很多开源大模型的镜像文件,所以只需要输入对应的指令,它就会自动下载对应的大模型,完成后就能进入推理界面开始对话了,整个过程非常直观简单。
以下7B、13B、14B等等都是指模型的参数量,1b= 1billion = 10亿,7B = 70亿表示参数量有70亿。参数量越多,对电脑环境要求越高。
环境要求举例:
- 7B :至少8GB内存能流畅运行
- 14B :至少16GB内存能流畅运行
- 72B :至少64GB内存能流畅运行
Mac系统后下载后是一个安装包,将安装包拖进去应用程序中既可。
拉取和运行智普的GLM大大模型命令:
1 | ollama run glm4 |
拉取和运行谷歌的开源大模型:
1 | ollama run gemma2 |
拉取和运行阿里开源的通义千问大模型:
1 | ollama run qwen2 |
默认情况下,不同操作系统大模型存储的路径如下:
1 | macOS: ~/.ollama/models |
Linux平台安装Ollama时,默认安装时会创建用户ollama,再将模型文件存储到该用户的目录/usr/share/ollama/.ollama/models。但由于大模型文件往往特别大,有时需要将大模型文件存储到专门的数据盘,此时就需要修改大模型文件的存储路径。
Ollama的API接口访问
Ollama默认绑定127.0.0.1端口11434,即默认只允许本机网络访问,如果需要外部机器访问,需要通过 OLLAMA_HOST环境变量更改绑定地址,具体设置参考本篇文章后面的参考资料。ollama提供了API,允许我们通过API进行访问。ollama提供了一个API接口地址:http://localhost:11434/api/chat,我们可以在Postman中,访问这个接口进行测试。对于ollama来说,为了保持和OpenAI的统一,也提供了OpenAI的地址兼容,我们访问如下地址:http://127.0.0.1:11434/v1/chat/completions
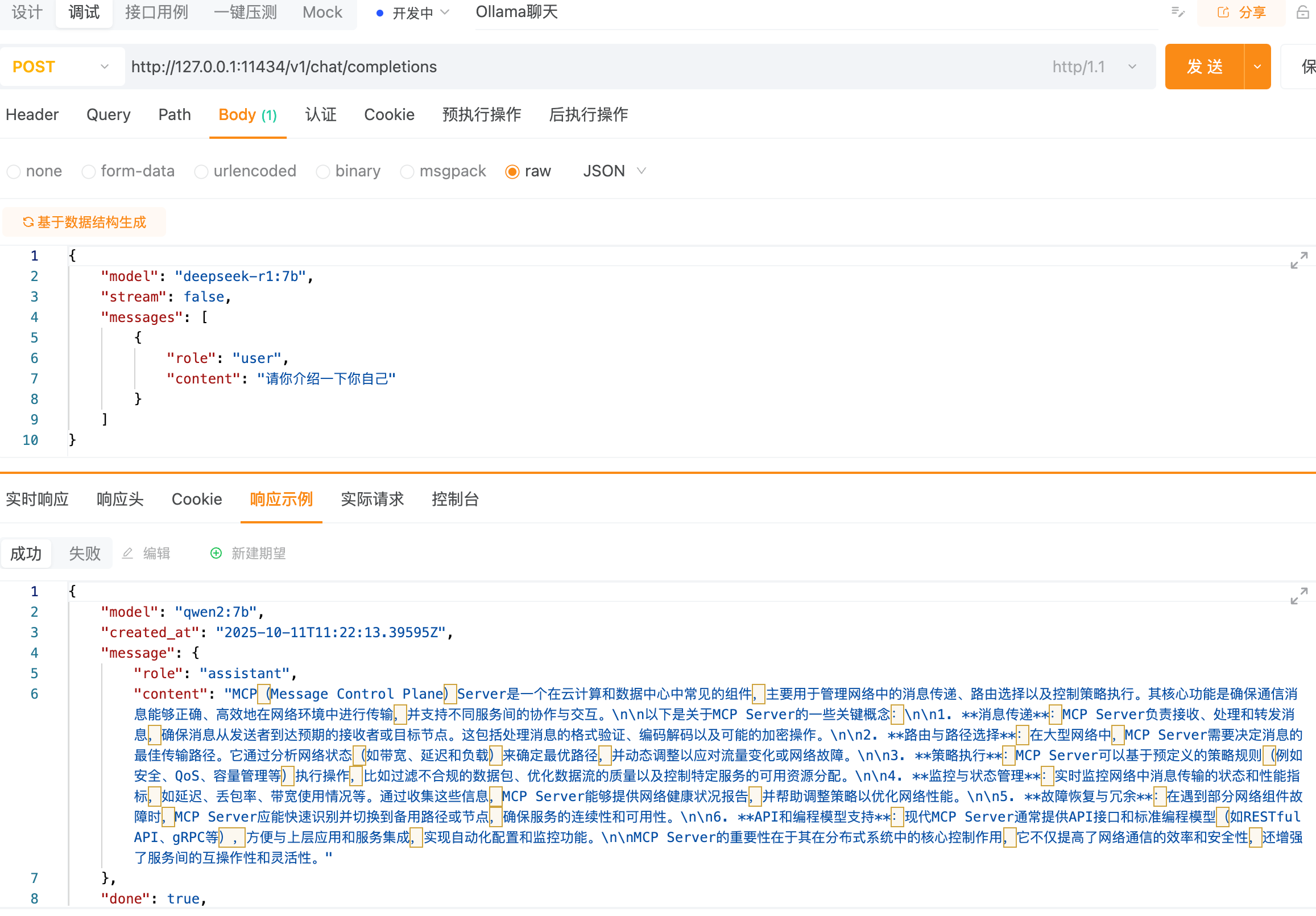
AI大模型的API接口的基本格
其实,目前AI大模型对接起来是非常简单的,本质就是构造一个HTTP同步请求或者SSE流式响应请求发送给大模型,大模型同步响应结果或者流式响应结果:
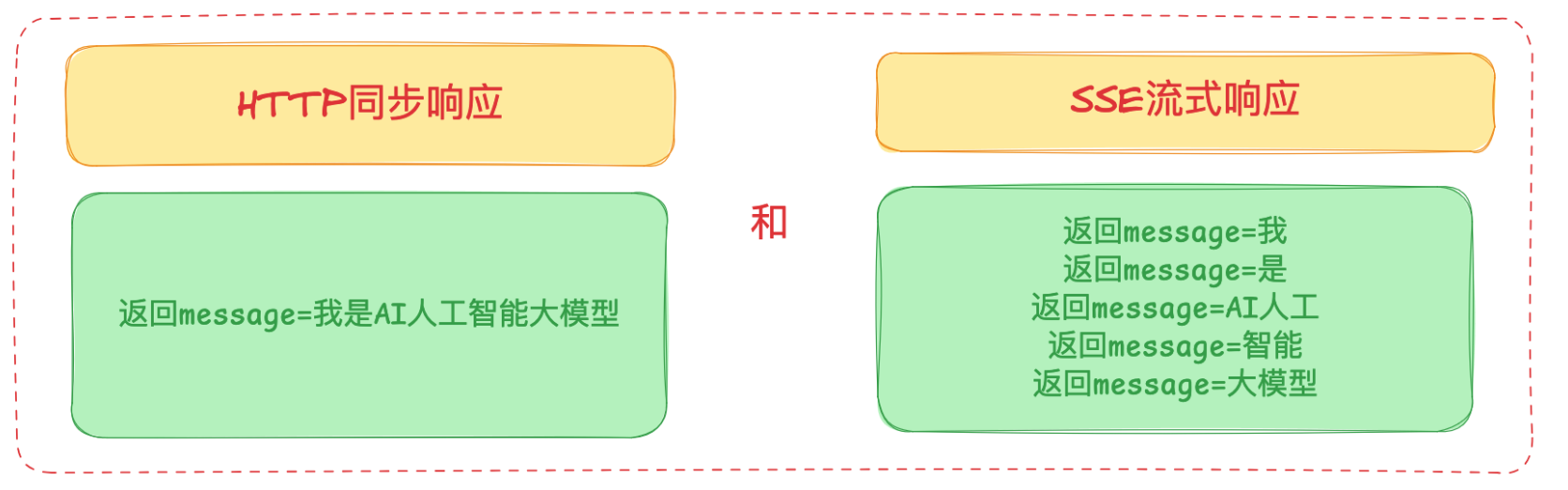
请求结构
1 | { |
首先我们对接AI大模型的时候,需要构造一个聊天消息的Message列表数组,其中我们想让它默认有一个行为的话,我们可以定义一个system类型的角色的message信息,当我们问AI一句话的时候,实际上是构造了一个user类型角色的message信息,当AI回复的时候,实际上是一条角色类型为assistant的消息数据,这几个数据成就了我们一个AI大模型的聊天消息结构。
假设存在这样一个聊天的过程:
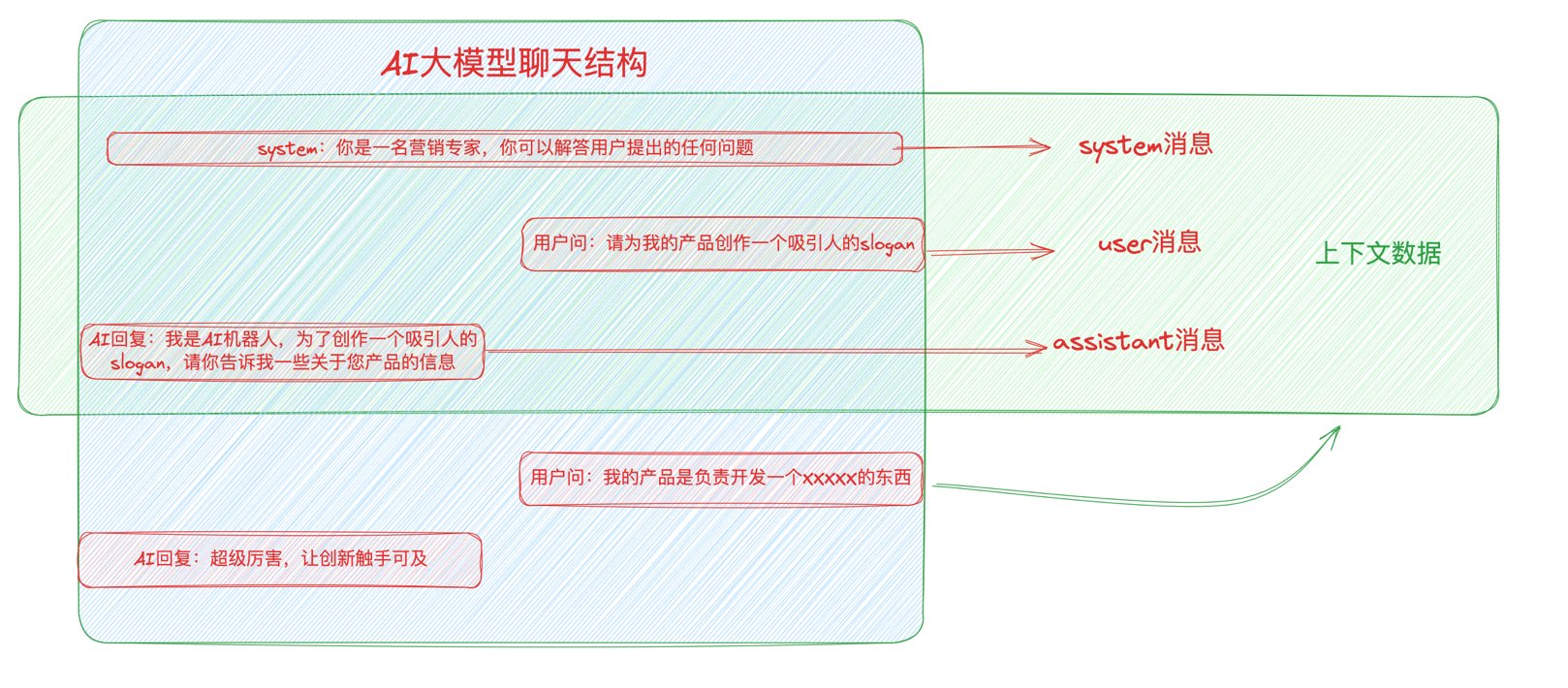
实际上与服务通信的时候,技术层面是这样的消息结构:
1 | messages=[ |
而每次和服务器通信的时候,多给他一些信息和历史数据,则是通信时候的上下文内容。
通常,我们需要在HTTP请求中声明当前请求的是具体的什么样的模型名称。
我们来看下网上对于这三个角色的总结:
system:它设定了 AI 的行为和角色和背景。常常用于开始对话,给出一个对话的大致方向,或者设置对话的语气和风格。system角色有助于通过分配特定行为给聊天助手来创建对话的上下文或范围。例如,如果您希望与ChatGPT在与体育相关的话题范围内进行对话,可以将”system”角色分配给聊天助手,并设置内容为”体育专家”。然后ChatGPT会表现得像体育专家一样回答您的问题。”system”角色指示了ChatGPT在对话消息中应该具有哪种个性。
user:就是我们输入的问题或请求。角色代表实际的最终用户,他正在向ChatGPT发送提示。在以下示例中,第一个消息对象和”system”角色并不是必需的。我们使用它来为对话分配上下文。”user”角色指示消息/提示来自最终用户或人类。
assistant:角色代表响应最终用户提示的实体。这个角色表示消息是助手(聊天模型)的响应。”assistant”角色用于在当前请求中设置模型的先前响应,以保持对话的连贯性。
这三个角色我们掌握后,在未来的AI开发中也比较中,我们可以模拟一段聊天过程给AI,让AI回复下一段的内容,从而实现AI的第一个阶段:提示词工程。
返回结构
我们日常会用到的就是这个结构中的这个数据:
当我们做AI对接大模型开发的时候,经常看到解析的返回结果中的代码是如下的样子:
这个是对接非流式接口的返回结构:
response.choices[0].message.content
如果是流式接口,我们通常会取值:
response.choices[0].delta.content
如果理解了这个结构,本质上,这个SDK的源码工程的核心内容我们就知道了,本质就是构造这样一个标准的请求数据结构。
企业级Gitlab环境安装与CI环境配置
创建本地 GitLab 部署目录
在你本地或服务器上创建 GitLab 的数据目录,用于持久化存储:
1 | mkdir -p ~/gitlab/config ~/gitlab/logs ~/gitlab/data |
编写 docker-compose.yml
在任意目录下(推荐 ~/gitlab),新建文件:
1 | version: '3.8' |
启动 GitLab 容器
在 docker-compose.yml 所在目录执行:
1 | docker compose up -d |
初次启动时间较长(约 3~10 分钟),GitLab 需要初始化数据库和服务组件。
初始化完成后,默认 root 用户的密码保存在容器内部:
1 | docker exec -it gitlab cat /etc/gitlab/initial_root_password |
复制输出的密码内容(有效期为 24 小时)。
访问 GitLab
在浏览器中打开:
1 | http://localhost:8929 |
修改配置(可选)
如果要修改端口或域名,可以直接编辑 docker-compose.yml 中的:
1 | external_url 'http://<your-ip>:<port>' |
修改后执行:
1 | docker compose restart gitlab |
修改初始账密
我们修改下当前用户的密码信息,访问当前用户的个人中心进行设置,修改新密码,当前默认生成的密码会在24小时后失效,我们需要在个人中心修改管理员的密码:
新建项目
最后我们新创建一个项目,用于测试AI代码评审,并通过Git命令下载项目到本地:
这样我们的安装和基本环境就配置完成了。
Gitlab 令牌添加
要想访问Gitlab的API,我们首先需要再Gitlab中创建一个用户的访问令牌,这个可以是当前用户个人的,也可以是项目级别的访问令牌,这里我选择了个人的访问令牌,首先找到Gitlab个人中心的个人访问令牌,选择添加新令牌:
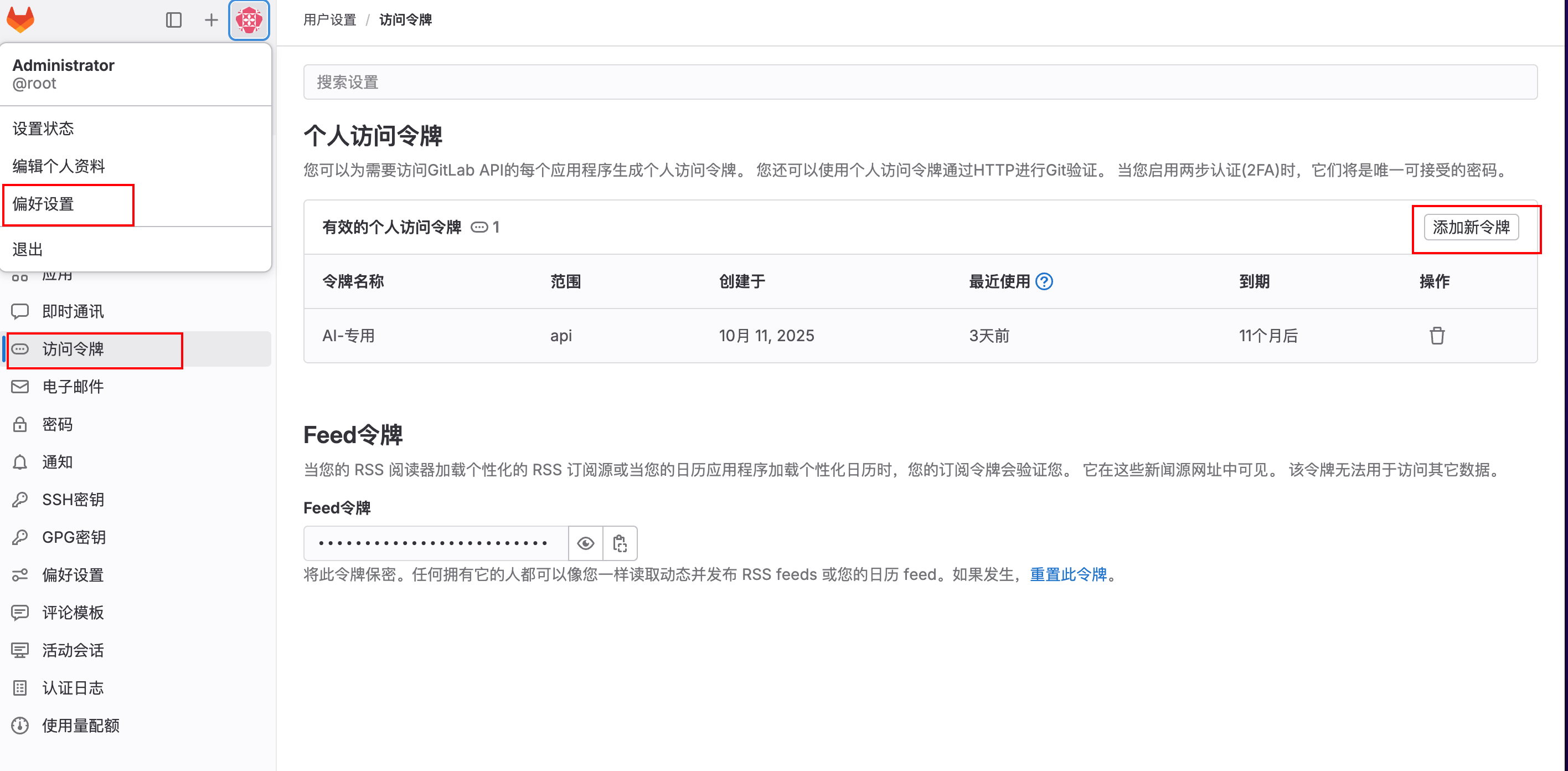
然后我们添加一下个人的令牌,设置下有效期与权限,这里的权限我们选择一个【api】,输入完成后,单击下发的确认按钮,如图:
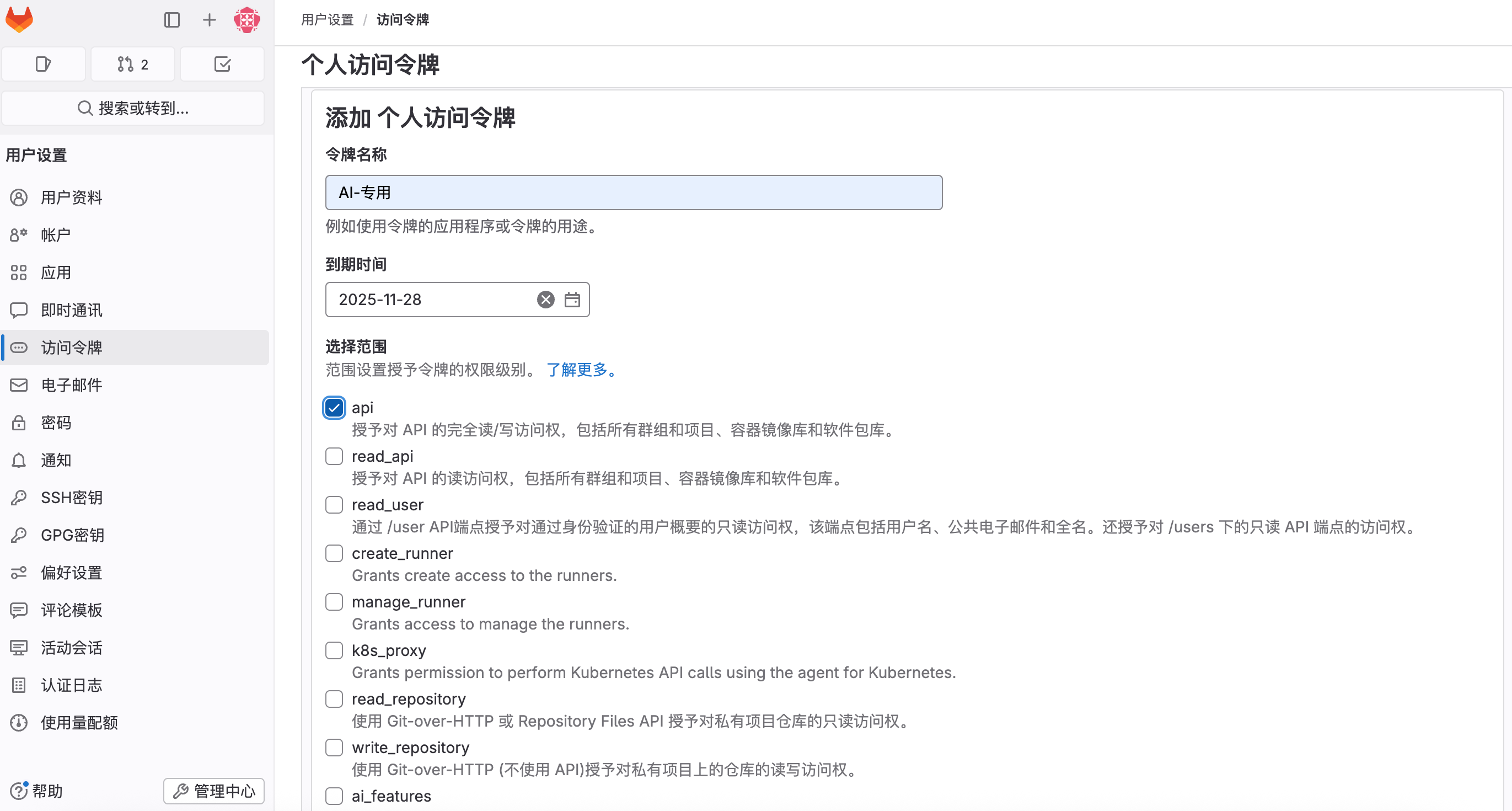
添加成功后,我们把当前这个个人的令牌的记录保存起来,然后就可以作为访问Gitlab API的凭证信息,如图:

Gitlab API测试
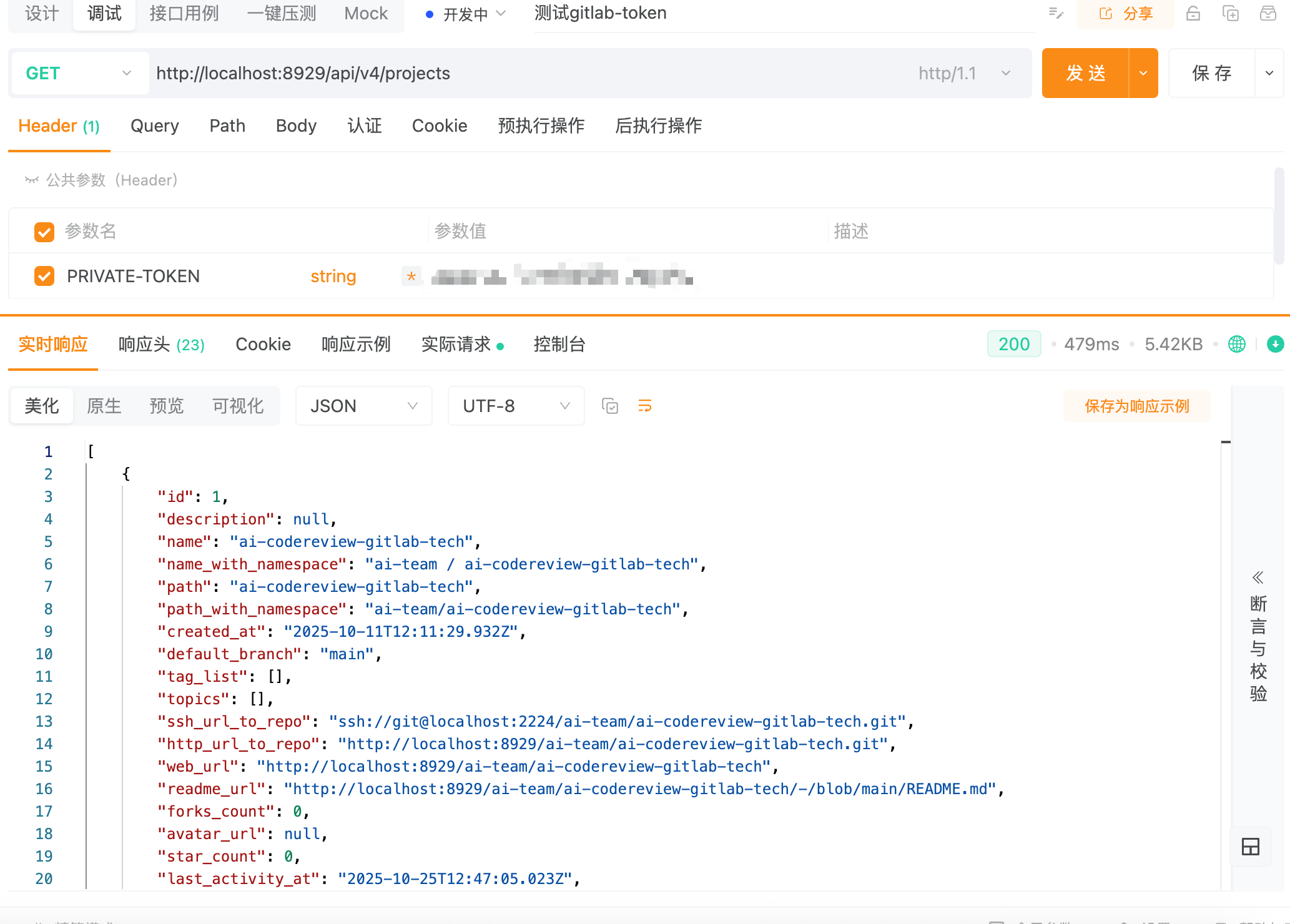
有了这个令牌后,我们可以做个测试,看看是否能够访问成功,找到Gitlab API的官方描述文档(https://docs.gitlab.com/ee/api/rest/)
知道了这个东西后,我们可以在Postman工具或者curl命令中对这个请求进行模拟访问,如果有存在成功状态的返回结果则可以代表通过API请求是通的,可以获取当前的项目信息,这里我就不详细展开说明了,因此我们也就学习到了第一个API:请求Gitlab的项目信息API:https://gitlab.example.com/api/v4/projects
导入项目
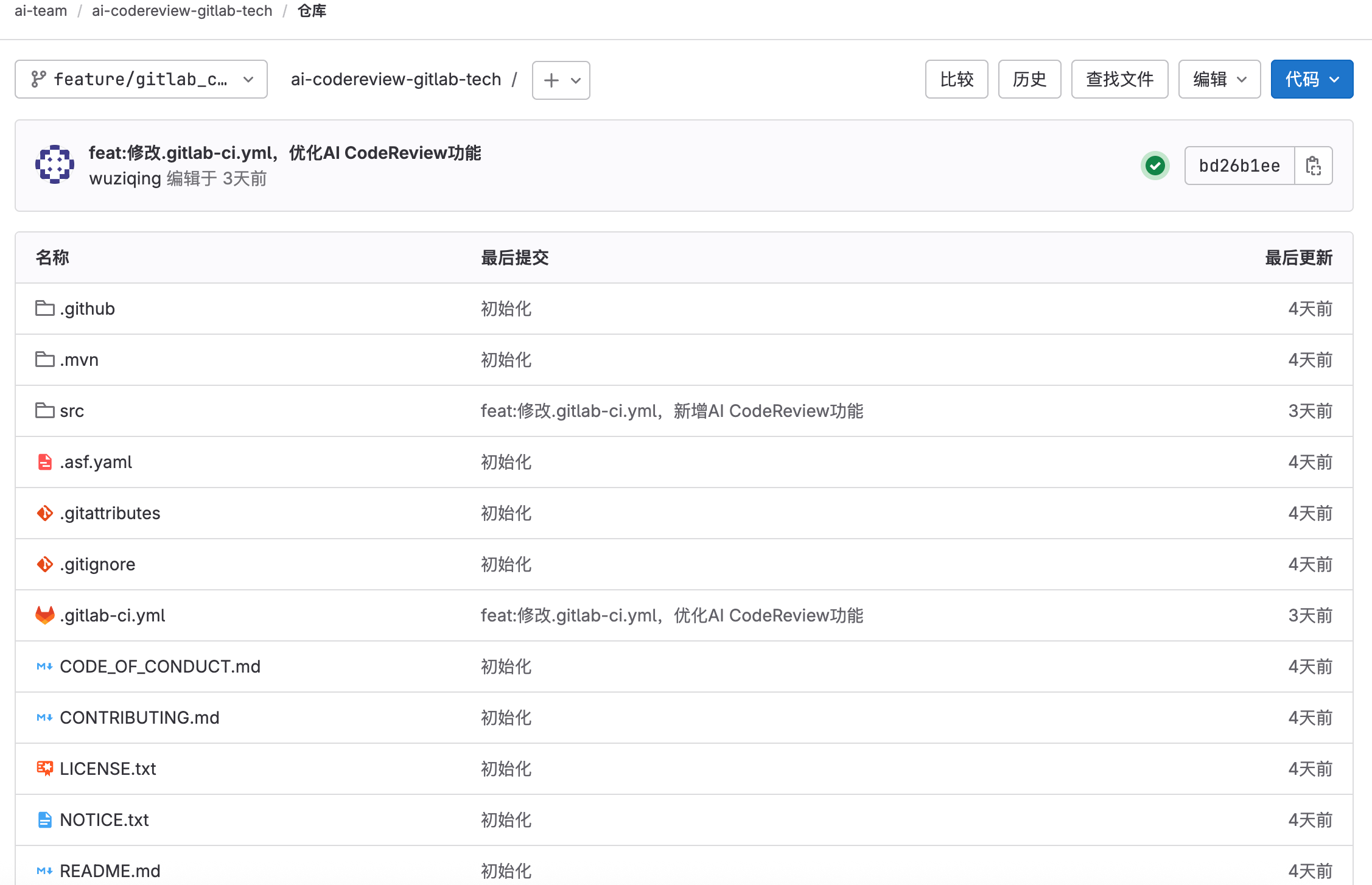
接下来我们从网上导入任意的项目到Gitlab,然后并创建MR信息,这里我选择的是Apache Commons项目作为测试的项目:
https://gitee.com/apache/commons-lang/tree/master
我们将这个项目的代码,上传到自己搭建的Gitlab环境中,同时新建一个特性分支:feature/gitlab_ci_demo,用于作为我们合并代码开发的原始需求分支:
这样我们有了一个基础的测试项目。
部署项目Runner
进入项目的 CI/CD 设置页面
- 打开你的 GitLab 项目;
- 左侧菜单选择:Settings → CI/CD
- 展开 Runners 这一项(可能需要点击 “Expand”)。
找到 “New project runner” 按钮
在 “Runners activated for this project” 区域中,
找到按钮:
🧩 “New project runner”
(有时显示为 “Register a new runner”)
点击它。
选择 Runner 托管方式
GitLab CE 默认提供两种安装方式:
- Option 1: Run untagged job (默认)
- Option 2: Use Docker executor
- Option 3: Run shell executor
常用是 Docker executor,也是最推荐的。
复制注册命令
GitLab 会生成一条注册命令,类似下面这样👇:
1 | sudo gitlab-runner register \ |
在 Runner 服务器上执行注册命令
你可以在任何装有 Docker 的 Linux / macOS 主机执行,也可以本机注册 Runner。
确保安装了 gitlab-runner:
1 | brew install gitlab-runner |
启动 Runner 服务
查看现有 GitLab 容器的网络
1 | docker inspect gitlab | grep -A 3 Networks |
假设输出显示你的 GitLab 容器在 gitlab_default 网络中,例如:

1 | "Networks": { |
记下网络名字,比如这里是 gitlab_default。
假设我们用宿主机目录 ~/gitlab-runner/config 保存 Runner 配置:
1 | mkdir -p ~/gitlab-runner/config |
–network gitlab_default,这样 Runner 可以访问 GitLab 容器。
输入GitLab上的注册命令后,会在控制台显示
1 | Enter the GitLab instance URL (for example, https://gitlab.com/): |
输入:http://localhost:8929 即可
控制台又会显示
1 | Enter a name for the runner. This is stored only in the local config.toml file: |
这里里可以填写一个描述性名称,用于你本地识别这个 Runner。
例如:ai_code_review
控制台紧接着显示
1 | Enter an executor: custom, shell, ssh, parallels, docker, docker+machine, kubernetes, docker-autoscaler, virtualbox, docker-windows, instance: |
Executor 指 Runner 如何执行 CI job。
- 常用选项:
- shell → 直接在 Runner 容器或宿主机执行命令
- docker → 在 Docker 容器中执行 job(推荐,尤其是 macOS + Docker Desktop)
- 其他的(kubernetes、docker+machine 等)一般不需要
如果希望 job 在 docker 内运行,输入 docker
如果选择 docker 作为 executor,会继续提示:
1 | Please enter the default Docker image (e.g. ruby:2.6): |
这里填写 CI job 默认使用的 Docker 镜像,例如:
1 | alpine:latest |
以后 .gitlab-ci.yml 可以覆盖这个默认镜像。
返回 GitLab 页面验证
回到你的项目 →
Settings → CI/CD → Runners,
刷新页面,你会看到刚注册的 Runner 显示为:
1 | Active: true |
这就说明 Runner 已注册成功。
基于Gitlab API与CI的AI代码审查实现
设置CI文件与变量
为这个项目根目录添加下当前feature这个特性的分支的Gitlab CI文件,.gitlab-ci.yml 内容如下:
1 | stages: |
在这个脚本中包含了2个内置的Gitlab CI的变量占位符,也有2个非内置的变量占位符,在Gitlab的官方文档中,可以知道内置了一些环境变量,我们可以根据自己的需求进行使用,这样就可以在运行时拿到一些真实的数据,个人是非常建议大家阅读下这些变量的,可以帮助我们在CI文件运行的时候,可以获得更多的上下文信息:
https://docs.gitlab.com/17.1/ee/ci/variables/predefined_variables.html
在我们当前的CI文件中,我们需要在当前项目的Gitlab CI配置中增加上2个我们自己自定义的变量信息:
GITLAB_TOKEN(代表访问的令牌)
GITLAB_API(代表Gitlab的地址)
AI_CODE_REVIEW_API(代表调用AI大模型的接口)
找到当前项目的CI的变量设置的界面:
先添加第一个变量信息,GITLAB_TOKEN,也就是我们的TOKEN:
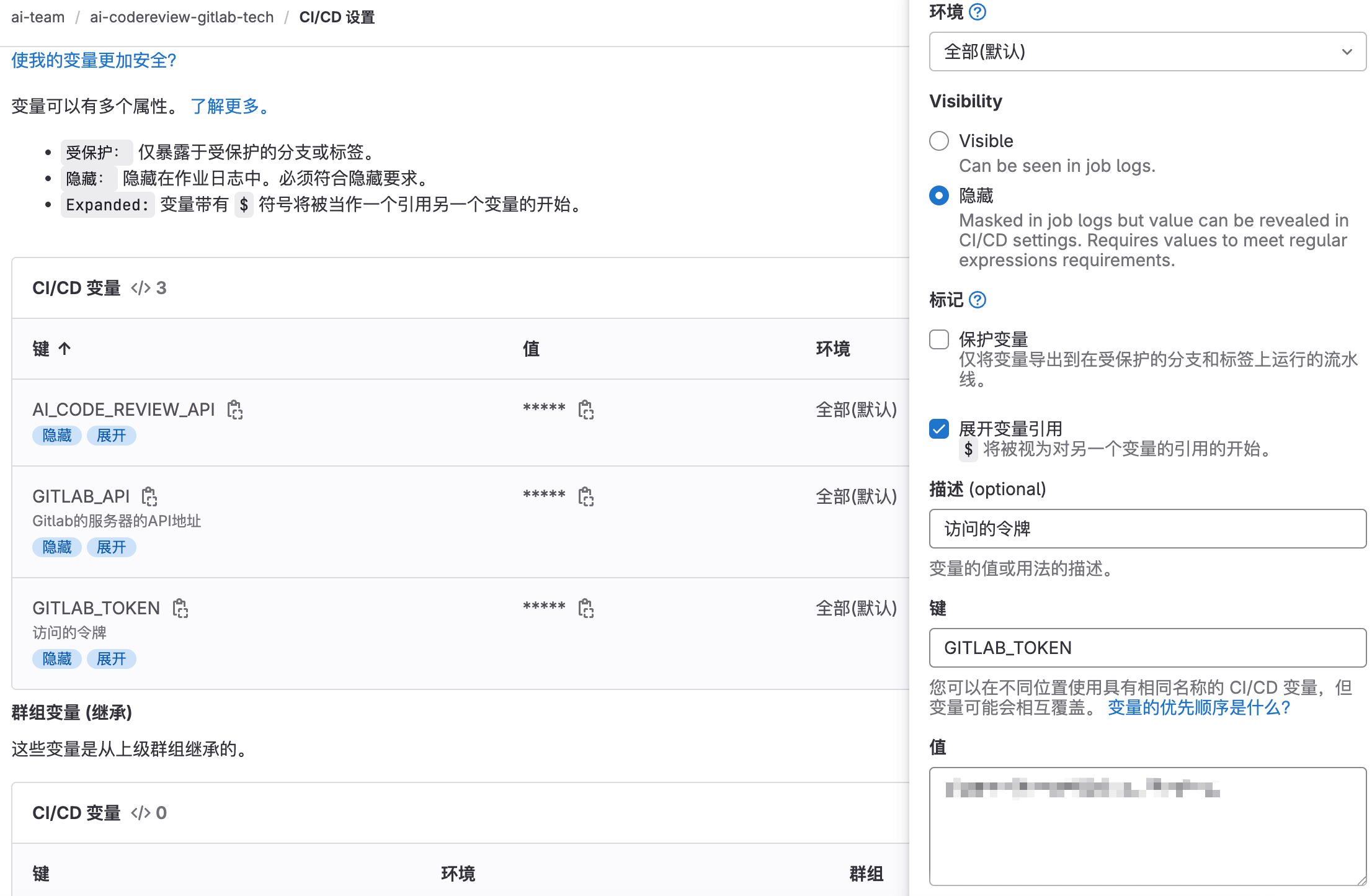
添加第二个变量,GITLAB_API,这里设置的是Gitlab的服务器的API地址:
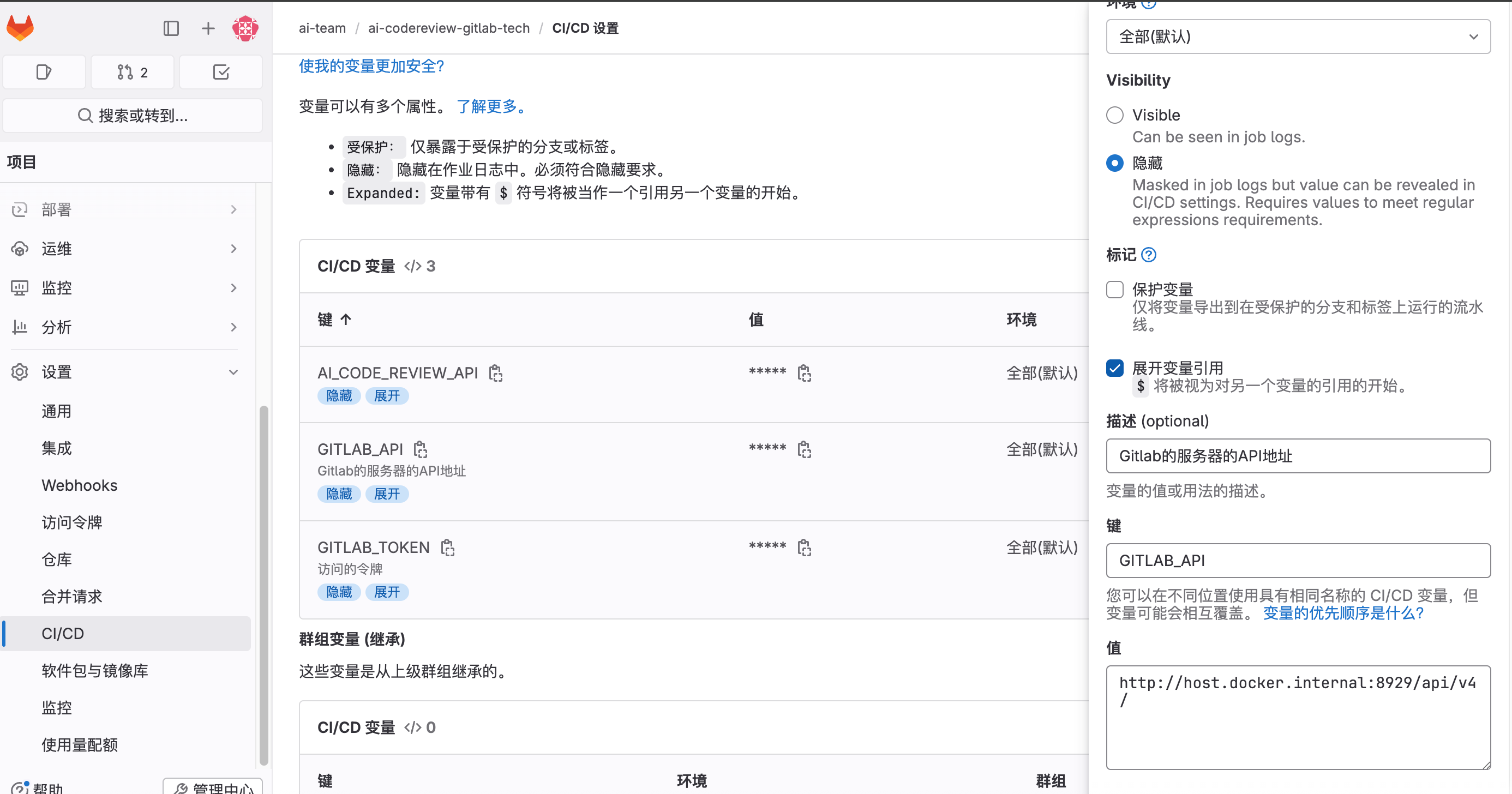
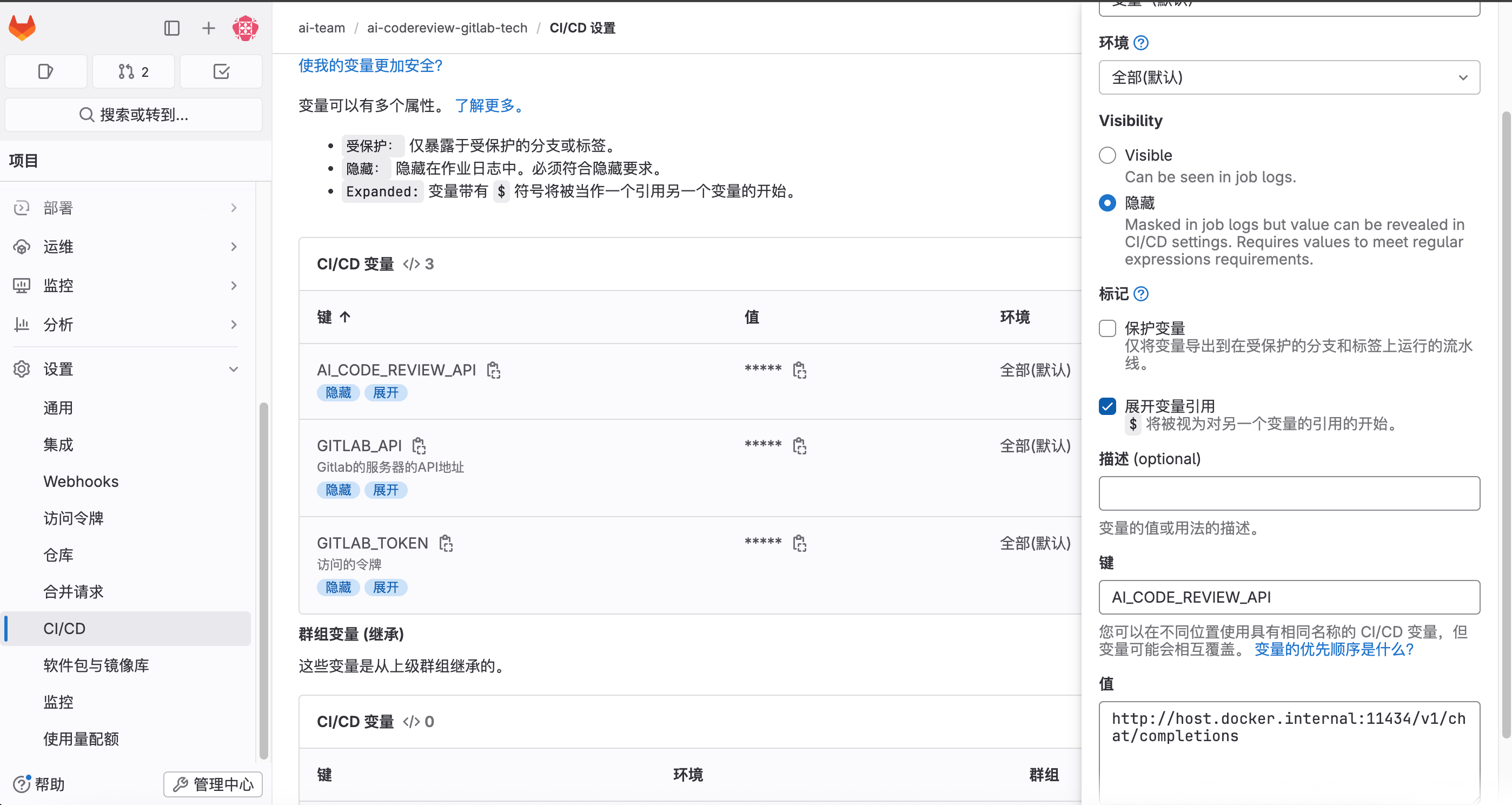
添加第三个变量,AI_CODE_REVIEW_API,调用AI大模型的接口,这里填的是 ollama 的地址:
在 commit 的时候需要检查下文件的格式是否是 utf-8,以保证上传到 gitlab 不会出现中文乱码问题。
创建Merge Request申请
这样合并前的代码分支我们准备好了,我们可以继续基于当前分支在创建一个分支,用于作为目标的待合并的分支,创建分支为:target
新建合并请求如下:
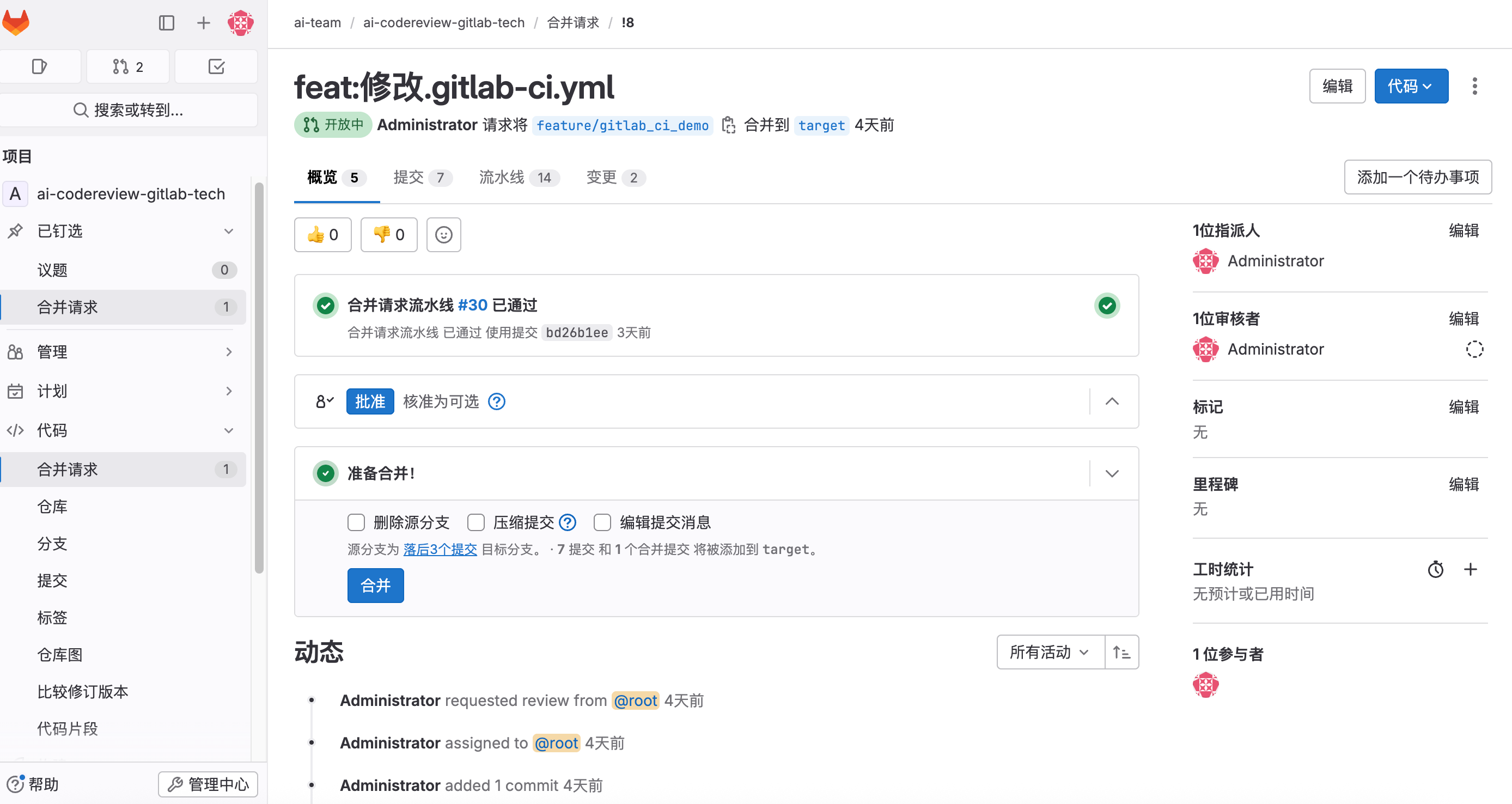
点进流水线,当提前创建好MR请求后,每一次的原始分支的改动,都可以自动触发CI流水线的执行,我们看下执行日志:
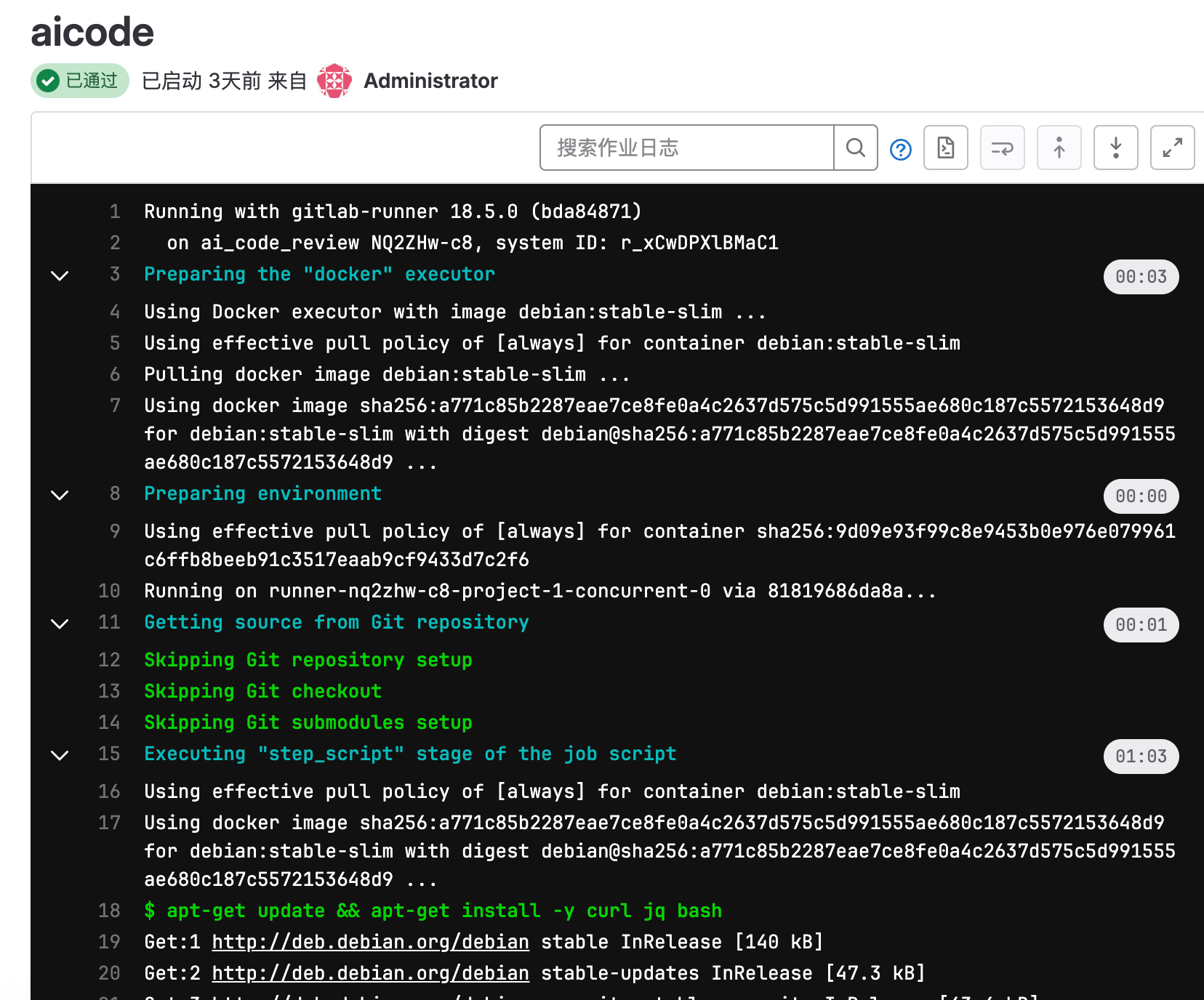
继续看日志,可以知道AI返回了评审的结果:
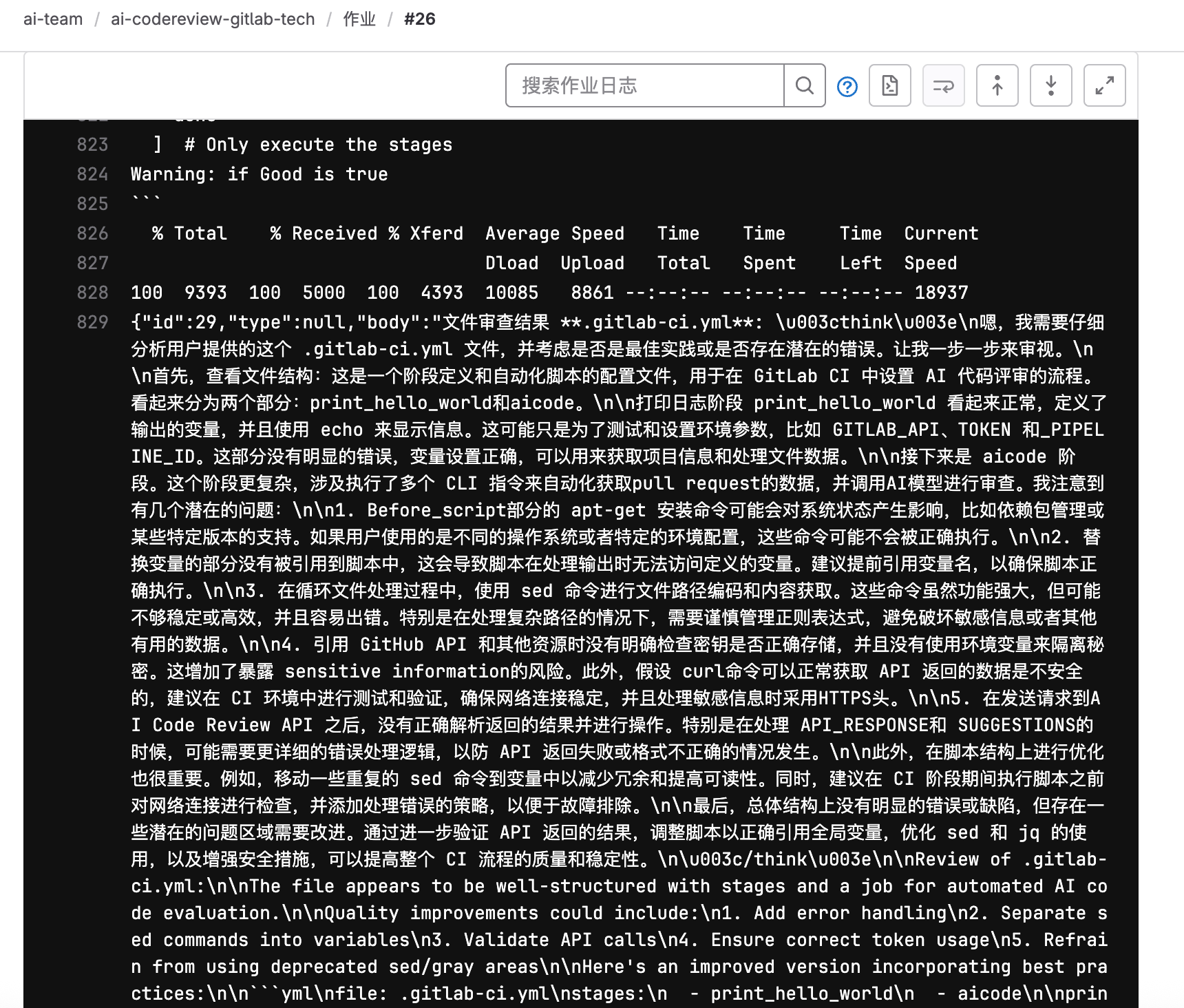
然后,我们在切换回Gitlab中的Merge Request的界面,可以看到在概览中已经有AI的评论结果了:
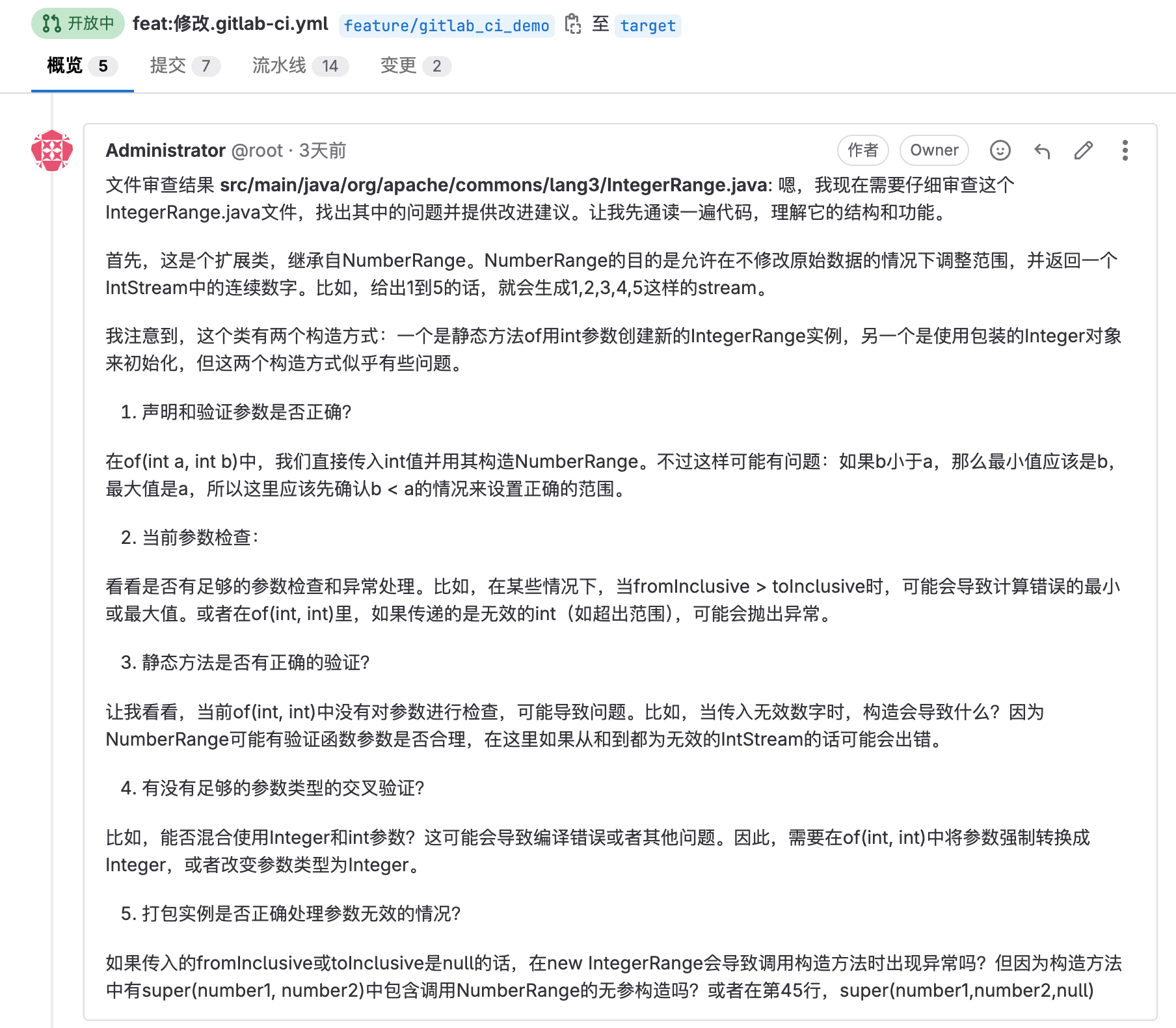
这样就实现了基于Gitlab API、Gitlab CI的AI代码审查。
总结
本节内容中的最核心的配置就是这个CI配置文件,这个CI中用到了几个Gitlab API的地址:
1 | GET $GITLAB_API/projects/$CI_PROJECT_ID/pipelines/$CI_PIPELINE_ID |
含义和解释如下:
获取当前流水线的提交的标识(SHA):
1 | GET $GITLAB_API/projects/$CI_PROJECT_ID/pipelines/$CI_PIPELINE_ID |
获取当前提交关联的Merge Request标识(MR ID):
1 | GET $GITLAB_API/projects/$CI_PROJECT_ID/repository/commits/$COMMIT_SHA/merge_requests |
获取Merge Request的变更文件列表:
1 | GET $GITLAB_API/projects/$CI_PROJECT_ID/merge_requests/$MR_ID/changes |
获取变更文件的内容:
1 | GET $GITLAB_API/projects/$CI_PROJECT_ID/repository/files/$ENCODED_FILE_PATH/raw?ref=$COMMIT_SHA |
将AI审查结果作为Merge Request的注释写回去:
1 | POST $GITLAB_API/projects/$CI_PROJECT_ID/merge_requests/$MR_ID/notes |
我们再看下当前的CI配置文件的业务流程图:
Gitlab CI的内容分离
其实在Gitlab CI的玩法中,支持在CI文件中,通过include操作来引入一个其他位置的文件,可以是当前仓库下的文件,也可以是HTTP的文件地址。
既然可以用HTTP文件地址,那就好办了,我们在某一台支持HTTP访问的服务器上(nginx代理即可),存储一个Gitlab CI的文件,如下:
http://ip:port/gitlabci/gitlab-ci-ai-codereviw.yml
话不多说,开干。
macOS 上新建一个目录,比如:
1 | mkdir -p ~/gitlab/gitlabci |
把公共ci文件挪到 ~/gitlab/gitlabci 目录下。
在同一个目录下新建一个简单的 docker-compose.yml:
1 | version: '3.8' |
启动 nginx 服务:
1 | docker-compose up -d |
然后在浏览器中打开:
1 | http://localhost:8088/gitlabci/gitlab-ci-ai-codereview.yml |
为了解决gitlab不能访问本地地址的问题,需要固定一个域名。
安装 Cloudflare Tunnel
1 | brew install cloudflared |
启动 tunnel:
1 | cloudflared tunnel --url http://localhost:8088 |
这样会得到地址:
1 | INF Starting tunnel tunnelID=<随机ID> |
GitLab CI 配置就可以写:
1 | include: |
然后在Gitlab的CI流水线文件中,增加如下配置:
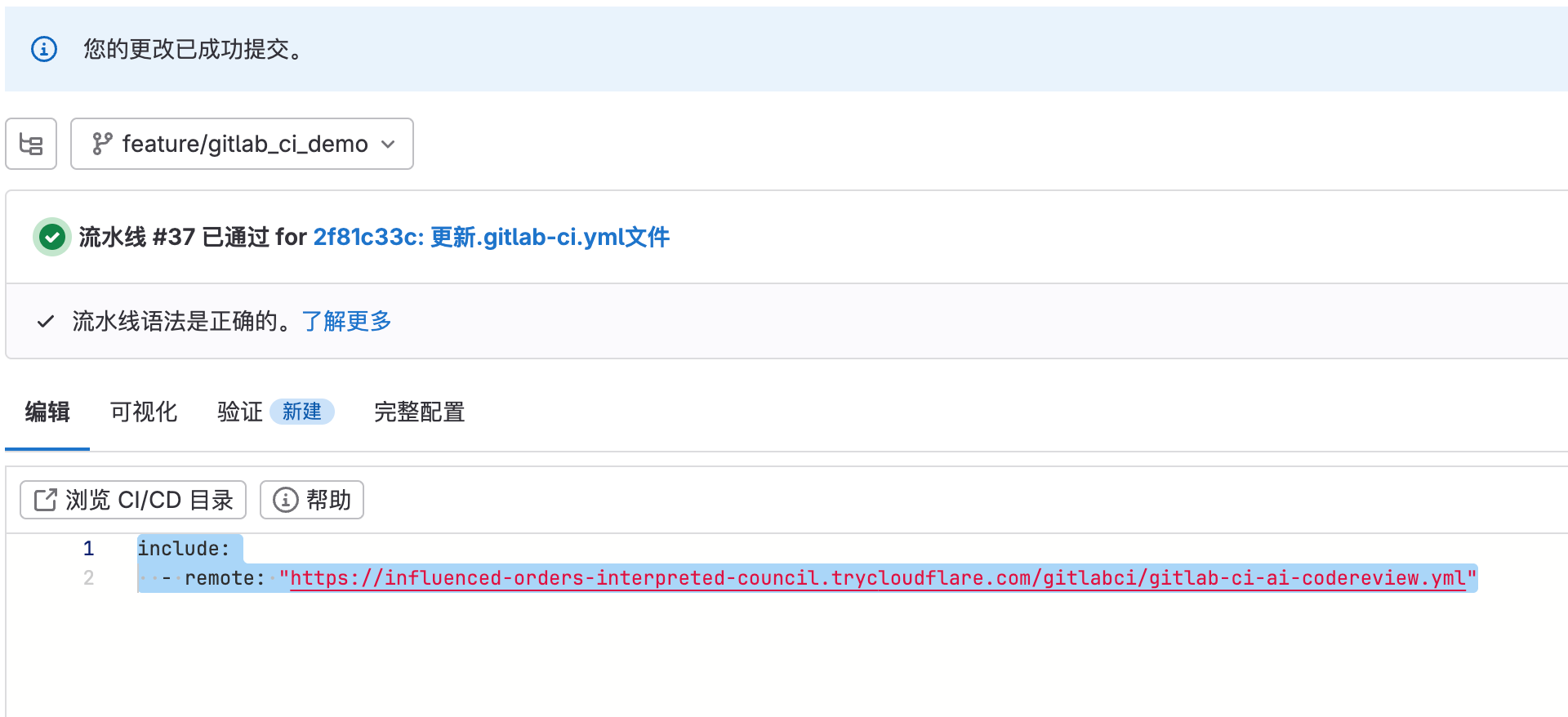
这样我们就将一个CI配置文件放到了一台公共的服务器上,这样我们以后在改动文件的内容,也不会对版本库的文件版本的历史做改动了。
执行后的日志记录如下所示:
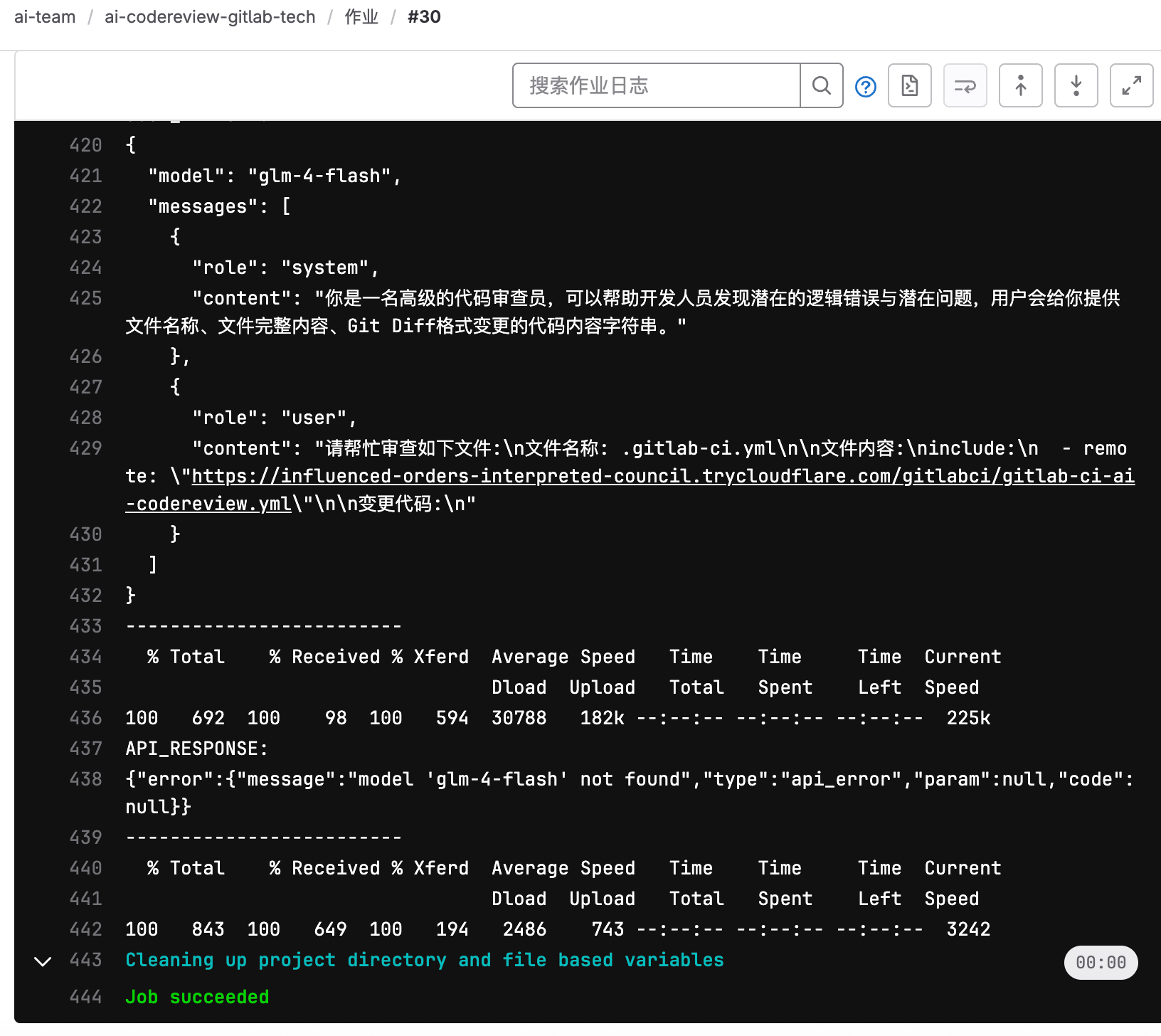
通过日志可以看到,把文件单独放在一个地方,然后通过include的方式来引用,这个应用地址可以是HTTP地址,也可以是代码仓库中的存储的多个文件地址。
在 GitLab CI/CD 配置中,include 关键字用于将外部的 CI 配置文件包含到当前的 .gitlab-ci.yml 文件中。这对于组织和复用 CI 配置非常有用,特别是在你想要共享或重用 CI/CD 配置时。
include 可以用于导入以下几种类型的外部配置:
项目文件(Local files):
可以引用同一项目中的其他文件。
include:
- local: ‘path/to/file.yml’
- 远程文件(Remote files):
允许你从外部 URL 导入 CI 配置。
1 | include: |
- 项目模板(Project templates):
可以引用 GitLab 提供的模板文件。
1 | include: |
文件(File from other projects):
可以从同一 GitLab 实例中的其他项目中引入 CI 配置文件。
1
2
3include:
- project: 'group/project'
file: 'path/to/file.yml'
使用场景
- 分离配置:将不同阶段或不同类型的任务分离到多个文件中,可以使 .gitlab-ci.yml 更加简洁。
- 共享配置:在多个项目之间共享通用的 CI 配置,减少重复配置。
- 分层结构:你可以构建一个基础的 CI 配置文件,然后在不同项目中根据需求进一步定制。
示例
假设你有一个项目,其中有多个 CI 配置文件,并且你希望在主配置文件中包含这些文件:
1 | # .gitlab-ci.yml |
在这个例子中,common-pipeline.yml、external-config.yml 和 shared-config.yml 中定义的任何 job 或者配置都会被合并到主配置文件中。
注意事项
- 顺序:GitLab 会按照你在 include 中定义的顺序来加载文件,并将它们合并到主配置文件中。
- 合并:如果有重复的 job 名称,后面的定义会覆盖前面的定义。
include 让 GitLab CI/CD 配置更具模块化和灵活性,特别适合复杂的项目或需要在多个项目中共享配置的场景。
2.2、Gitlab的.gitlab的文件夹的说明
当一个项目的CI/CD变大之后,会出现很多的逻辑和功能,而Gitlab的最佳实践就是,把内容发放到不同小文件中,它提供了.gitlab文件夹的玩法,感兴趣的可以来继续自己尝试下。
.gitlab 目录在 GitLab 项目中通常用于存放与 GitLab 特性相关的配置文件。虽然这个目录不是强制要求的,但是将特定的 GitLab 配置文件组织在 .gitlab 目录下有助于项目的清晰管理和结构化。以下是 .gitlab 目录的作用、含义和使用场景的详细解释。
.gitlab 目录的作用与含义
- 组织配置文件:.gitlab 目录通常包含与 GitLab 集成相关的配置文件。将这些文件放在一个专门的目录中,可以让项目的根目录更加整洁,避免与其他项目文件混淆。
- 集中管理:集中管理 GitLab 相关的配置文件,使得项目配置更为直观和易于维护。开发团队可以更快地找到并修改与 GitLab 相关的配置。
.gitlab 目录中的常见文件与使用场景
- .gitlab-ci.yml:
作用:这是 GitLab CI/CD 配置文件的默认位置,用于定义项目的持续集成和持续部署(CI/CD)流水线。
使用场景:每当你 push 代码到 GitLab 仓库时,GitLab 会根据这个文件中的定义自动执行构建、测试和部署任务。
例子:
1
2
3
4
5
6
7
8
9stages:
- build
- test
- deploy
build-job:
stage: build
script:
- echo "Building the project..."
- .gitlab/issue_templates:
作用:用于存放自定义的 issue 模板。当你在 GitLab 中创建一个新 issue 时,可以选择使用这些模板。
使用场景:在团队中标准化 issue 报告流程,确保所有必要的信息被填写。
例子:bug.md 模板文件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20markdown
复制代码
### Bug 描述
描述问题的具体情况。
### 重现步骤
1. 第一步
2. 第二步
3. ...
### 预期结果
应该出现的结果。
### 实际结果
实际出现的结果。
- .gitlab/merge_request_templates:
作用:用于存放自定义的合并请求模板。当你在 GitLab 中创建一个新的合并请求(Merge Request,MR)时,可以选择使用这些模板。
使用场景:标准化代码审查流程,确保所有合并请求都包含必要的背景信息、测试说明等。
例子:feature_request.md 模板文件
1 | ### 功能描述 |
- .gitlab/auto_devops.yml:
作用:用于自定义 GitLab 的 Auto DevOps 配置。Auto DevOps 是 GitLab 提供的一种自动化的 CI/CD 功能,它可以自动检测项目类型并自动执行构建、测试、部署等任务。
使用场景:如果你想定制 Auto DevOps 行为,可以在 .gitlab 目录中添加这个文件来覆盖默认设置。
- .gitlab/ci:
作用:可以用于存放共享的 CI 配置文件,方便在 .gitlab-ci.yml 中通过 include 关键字引用。
使用场景:如果你的 CI 配置非常复杂,或者你希望将一些配置抽取出来以便复用,可以将这些配置文件放在这个目录中。
使用 .gitlab 目录的好处
清晰的项目结构:将所有 GitLab 相关的文件集中在一个目录下,可以避免项目根目录过于杂乱,尤其是大型项目。
方便管理:当你需要对 GitLab 的配置进行调整时,可以快速找到相关文件。
团队协作:通过模板标准化 issue 和 merge request 的流程,提高团队的协作效率。
Gitlab提交API的评审实现与企微消息通知
有了这个地址后,我们可以先进行测试,用任意方式向 webhook 地址发起一个 HTTP POST 请求。
1 | curl -X POST -H "Content-Type: application/json" \ |
示例命令说明:
- 请求方式:POST
- 请求头:Content-Type: application/json
- 请求体:{“msg_type”:”text”,”content”:{“text”:”request example”}}
- webhook 地址:https://open.feishu.cn/open-apis/bot/v2/hook/**** 为示例值,你在实际调用时需要替换为自定义机器人真实的 webhook 地址。
接下来我们可以把地址添加到CI/CD的环境变量中,后续使用 $WEBHOOK。
因此我们可以在CI中,增加如下操作:
1 | # 发送通知消息进行评审 |
这段脚本中的WEB_URL是一个地址,用于告诉用户收到消息后去哪里查看,然后我们通过CURL发送了一个没有加密地址的请求,然后$WEBHOOK这个就是在Gitlab CI菜单中设置的一个动态变量,我们可以把地址维护在Gitlab的变量中,从而避免信息泄露。




