
Java并发编程实战
可见性、原子性和有序性问题:并发编程Bug的源头
可见性
在单核时代,所有的线程都是在一颗CPU上执行,CPU缓存与内存的数据一致性容易解决。
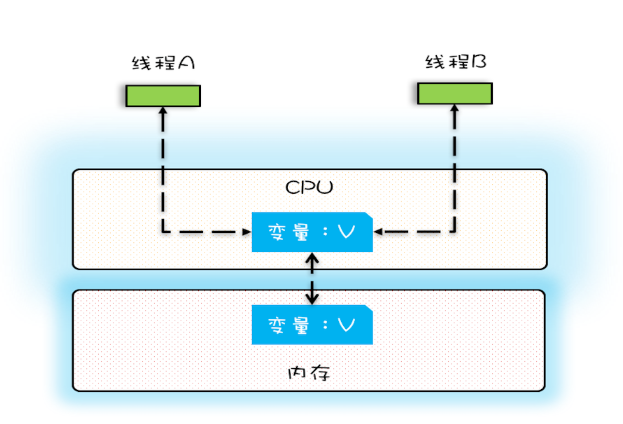
一个线程对共享变量的修改,另外一个线程能够立刻看到,我们称为可见性。
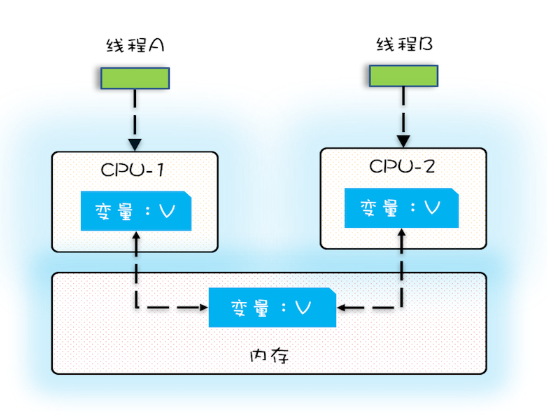
多核时代,每颗CPU都有自己的缓存,这时CPU缓存与内存的数据一致性就没那么容易解决了,当多个线程在不同的CPU上执行时,这些线程操作的是不同的CPU缓存。
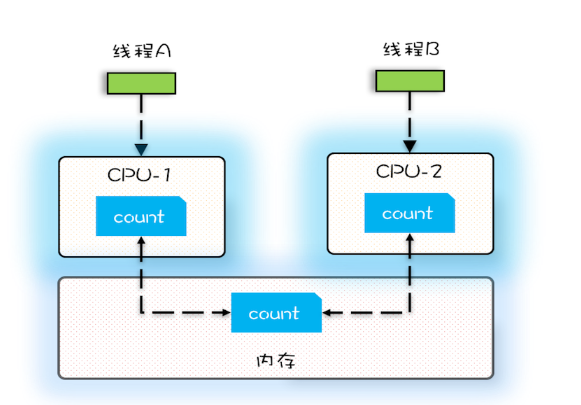
每执行一次add10K()方法,都会循环10000次count+=1操作。在calc()方法中我们创建了两个线程,每个线程调用一次add10K()方法,循环10000次count+=1操作如果改为循环1亿次,你会发现效果更明显,最终count的值接近1亿,而不是2亿。如果循环10000次,count的值接近20000,原因是两个线程不是同时启动的,有一个时差。
原子性
操作系统允许某个进程执行一小段时间,例如50毫秒,过了50毫秒操作系统就会重新选择一个进程来执行(我们称为“任务切换”),这个50毫秒称为“时间片”。
在一个时间片内,如果一个进程进行一个IO操作,例如读个文件,这个时候该进程可以把自己标记为“休眠状态”并出让CPU的使用权,待文件读进内存,操作系统会把这个休眠的进程唤醒,唤醒后的进程就有机会重新获得CPU的使用权了。
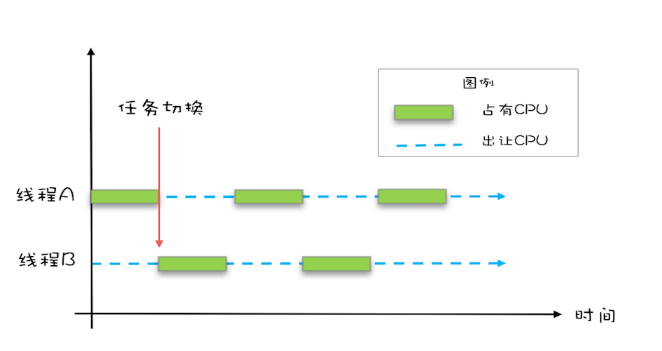
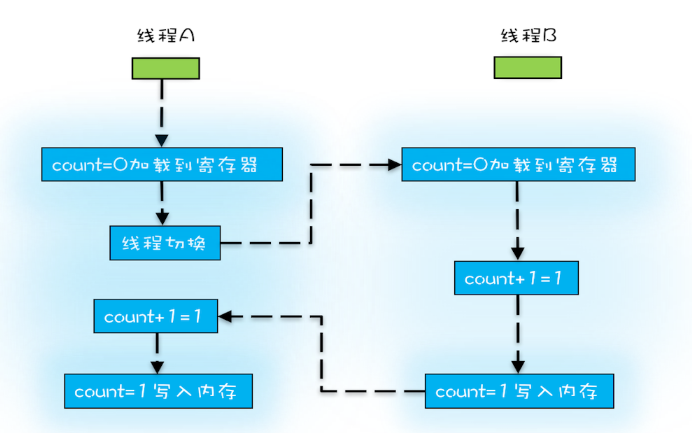
务切换的时机大多数是在时间片结束的时候,我们现在基本都使用高级语言编程,高级语言里一条语句往往需要多条CPU指令完成,例如上面代码中的count += 1,至少需要三条CPU指令。
- 指令1:首先,需要把变量count从内存加载到CPU的寄存器;
- 指令2:之后,在寄存器中执行+1操作;
- 指令3:最后,将结果写入内存(缓存机制导致可能写入的是CPU缓存而不是内存)。
操作系统做任务切换,可以发生在任何一条CPU指令执行完,是的,是CPU指令,而不是高级语言里的一条语句。对于上面的三条指令来说,我们假设count=0,如果线程A在指令1执行完后做线程切换,线程A和线程B按照下图的序列执行,那么我们会发现两个线程都执行了count+=1的操作,但是得到的结果不是我们期望的2,而是1。
有序性
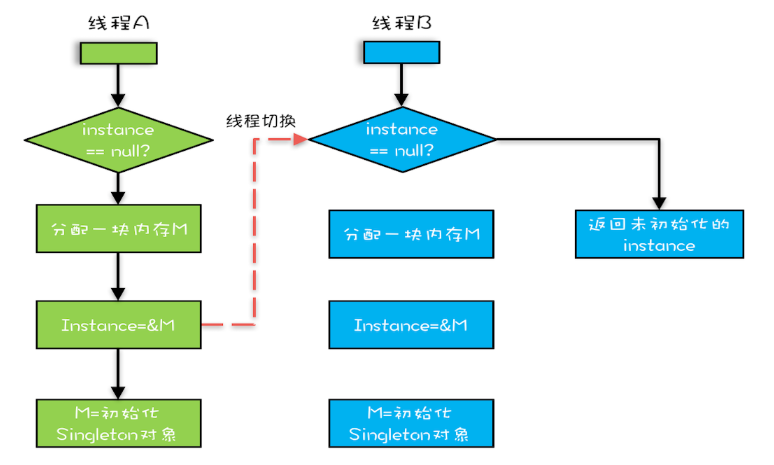
在Java领域一个经典的案例就是利用双重检查创建单例对象。
1 | public class Singleton { |
假设有两个线程A、B同时调用getInstance()方法,他们会同时发现 instance == null ,于是同时对Singleton.class加锁,此时JVM保证只有一个线程能够加锁成功(假设是线程A),另外一个线程则会处于等待状态(假设是线程B);线程A会创建一个Singleton实例,之后释放锁,锁释放后,线程B被唤醒,线程B再次尝试加锁,此时是可以加锁成功的,加锁成功后,线程B检查 instance == null 时会发现,已经创建过Singleton实例了,所以线程B不会再创建一个Singleton实例。
这看上去一切都很完美,无懈可击,但实际上这个getInstance()方法并不完美。问题出在哪里呢?出在new操作上,我们以为的new操作应该是:
- 分配一块内存M;
- 在内存M上初始化Singleton对象;
- 然后M的地址赋值给instance变量。
但是实际上优化后的执行路径却是这样的:
- 分配一块内存M;
- 将M的地址赋值给instance变量;
- 最后在内存M上初始化Singleton对象。
优化后会导致什么问题呢?我们假设线程A先执行getInstance()方法,当执行完指令2时恰好发生了线程切换,切换到了线程B上;如果此时线程B也执行getInstance()方法,那么线程B在执行第一个判断时会发现 instance != null ,所以直接返回instance,而此时的instance是没有初始化过的,如果我们这个时候访问 instance 的成员变量就可能触发空指针异常。
Java内存模型:看Java如何解决可见性和有序性问题
什么是Java内存模型?
Java 内存模型(JMM)是一组规范和规则,它定义了在多线程环境下,Java 程序中的变量(包括实例字段、静态字段和构成数组对象的元素)如何被写入内存以及如何从内存中读取。它的核心目标是解决在并发编程中由于可见性、原子性和有序性问题而导致的线程不安全问题
JMM 从逻辑上划分了这两种内存:
- 主内存:所有共享变量都存储在主内存中。它是所有线程共享的区域。
- 工作内存:每个线程都有自己的工作内存,其中保存了该线程使用到的变量的主内存副本。线程对所有变量的操作(读取、赋值等)都必须在工作内存中进行,而不能直接读写主内存中的变量。
交互流程:
- 线程要读取一个共享变量时,会先从主内存复制一份到自己的工作内存。
- 然后线程就在自己的工作内存中操作这个副本。
- 操作完成后,在某个时间点再将工作内存中的副本刷新回主内存。
Happens-Before 规则
真正要表达的是:前面一个操作的结果对后续操作是可见的。
程序的顺序性规则
这条规则是指在一个线程中,按照程序顺序,前面的操作 Happens-Before 于后续的任意操作。这还是比较容易理解的,比如刚才那段示例代码,按照程序的顺序,第6行代码 “x = 42;” Happens-Before 于第7行代码 “v = true;”,这就是规则1的内容,也比较符合单线程里面的思维:程序前面对某个变量的修改一定是对后续操作可见的。
1 | class VolatileExample { |
volatile变量规则
这条规则是指对一个volatile变量的写操作, Happens-Before 于后续对这个volatile变量的读操作。
传递性
这条规则是指如果A Happens-Before B,且B Happens-Before C,那么A Happens-Before C。
我们将规则3的传递性应用到我们的例子中,会发生什么呢?可以看下面这幅图:
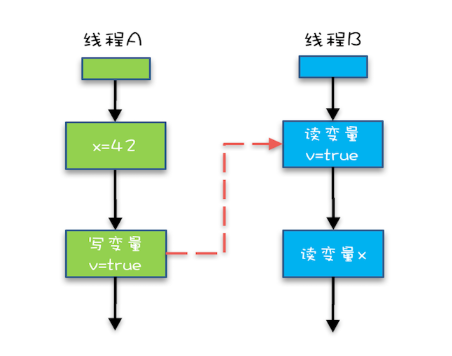
示例代码中的传递性规则
从图中,我们可以看到:
- “x=42” Happens-Before 写变量 “v=true” ,这是规则1的内容;
- 写变量“v=true” Happens-Before 读变量 “v=true”,这是规则2的内容 。
如果线程B读到了“v=true”,那么线程A设置的“x=42”对线程B是可见的。也就是说,线程B能看到 “x == 42”
管程中锁的规则
这条规则是指对一个锁的解锁 Happens-Before 于后续对这个锁的加锁。
管程是一种通用的同步原语,在Java中指的就是synchronized,synchronized是Java里对管程的实现。
管程中的锁在Java里是隐式实现的,例如下面的代码,在进入同步块之前,会自动加锁,而在代码块执行完会自动释放锁,加锁以及释放锁都是编译器帮我们实现的。
1 | synchronized (this) { //此处自动加锁 |
假设x的初始值是10,线程A执行完代码块后x的值会变成12(执行完自动释放锁),线程B进入代码块时,能够看到线程A对x的写操作,也就是线程B能够看到x==12。
线程 start() 规则
主线程A启动子线程B后,子线程B能够看到主线程在启动子线程B前的操作。
如果线程A调用线程B的 start() 方法(即在线程A中启动线程B),那么该start()操作 Happens-Before 于线程B中的任意操作。具体可参考下面示例代码。
1 | Thread B = new Thread(()->{ |
线程 join() 规则
主线程A等待子线程B完成(主线程A通过调用子线程B的join()方法实现),当子线程B完成后(主线程A中join()方法返回),主线程能够看到子线程的操作。
换句话说就是,如果在线程A中,调用线程B的 join() 并成功返回,那么线程B中的任意操作Happens-Before 于该 join() 操作的返回。
1 | Thread B = new Thread(()->{ |
synchronized
- 原子性:通过互斥锁保证代码块的原子性。
- 可见性:线程在进入
synchronized块时,会清空工作内存,从主内存重新加载共享变量。在退出synchronized块时,会把工作内存中的修改刷新到主内存。
sychronized 是一种互斥锁,一次只能允许一个线程进入被锁住的代码块。
sychronized 是 Java 的一个关键字,它能将代码块/方法锁起来。
如果 sychronized 修饰的是实例方法,对应的锁则是对象实例。
如果 sychronized 修饰的是静态方法,对应的锁则是当前类的 Class 实例。
如果 sychronized 修饰的是代码块,对应的锁则是传入 synchronized 的对象实例。
原理
通过反编译发现,编译器会生成 ACC_SYNCHRONIZED 关键字来标识。
当修饰代码块的时候,会依赖 monitorenter 和 monitorexit 指令。
无论 sychronized 修饰的是方法还是代码块,对应的锁都是一个实例对象。
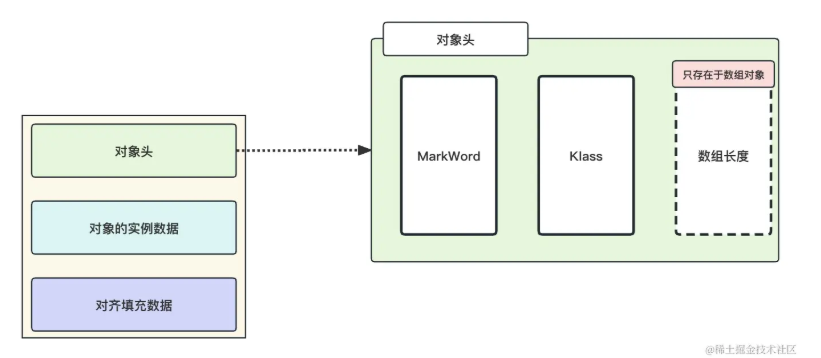
在内存中,对象一般由三部分组成,分别是对象头,对象实际数据和对齐填充。
重点在于对象头,对象头又由几部分组成,但是我们重点关注对象头 Mark Word 的信息就好。
Mark Word 会记录对象关于锁的信息。
又因为每个对象都会有一个与之对应的 monitor 对象,monitor 对象中存储着当前持有锁的线程和等待锁的线程队列。
了解 Mark Word 和 monitor 对象是理解 synchronized 原理的前提。
优化
在 JDK1.6 之前是重量级锁,线程进入同步代码块/方法时,monitor 对象会把当前进入线程的 id 进行存储,设置 Mark Word 的 monitor 对象地址,并把阻塞的线程存储到 monitor 的等待线程队列中,它加锁是依赖底层操作系统的 mutex 相关指令实现,所以会有用户态和内核态之间的切换,性能损耗十分明显。
而 JDK1.6 以后引入偏向锁和轻量级锁在 JVM 层面实现加锁逻辑,不依赖底层操作系统,就没有切换的消耗。在使用 synchronized 加锁的时候,Java 并不会直接调用操作系统内核加锁,而是根据线程的竞争情况采用不同的策略逐渐升级锁,直至调用操作系统加锁。
锁的升级包含以下几个过程:
- 调研发现,在大多数情况下,锁不仅不会存在竞争情况,而且通常会由同一个线程多次获取。在这种情况下,JVM 会将锁设置为偏向锁。偏向锁会在对象头中记录拥有偏向锁的线程的ID,并将锁标识位设置为偏向锁状态。这样,当同一个线程再次请求获取这个对象的锁时,不需要进行任何同步操作,可以直接获取到锁,提高了程序的性能。
- 另一种情况是,当线程B尝试获取偏向锁时,如果此时拥有偏向锁的线程A已经执行完毕并释放了锁,JVM 会尝试撤销偏向锁,并进行锁的竞争。如果在撤销偏向锁的过程中,没有其他线程来竞争锁,JVM 会将锁的状态设置为偏向线程B,并更新对象头中记录的线程ID为线程B的ID。在这种情况下,并不会发生锁的升级。只有当线程B尝试获取锁时,线程A还没有执行完毕,即出现了竞争情况,才会发生锁的升级,进而转为轻量级锁或重量级锁。
- 当系统线程出现多个线程竞争的情况时,synchronized 会从偏向锁升级为轻量级锁。需要注意的是,轻量级锁通常出现在竞争不激烈、任务执行时间短的情况下。当出现锁竞争时,例如线程A正在执行过程中,线程B开始尝试获取锁,此时synchronized会进行自旋等待。synchronized并不会立即升级为重量级锁,而是会尝试使用自适应自旋锁来获取锁。如果自旋一段时间后仍未获取到锁,synchronized会正式升级为重量级锁。
整体 synchronized 的锁升级过程为:偏向锁 -> 轻量级锁(自旋锁) -> 重量级锁。
- 无锁状态:锁标志位为
01,此时不存在线程执行任务。 - 偏向锁:系统会在 MarkWord 中记录一个线程 id,当该线程再次获取锁的时候,无需再申请锁,直接获取以增加效率。
- 轻量级锁:系统会将对象头中的锁标志位修正为”00”,加锁和解锁操作使用CAS指令来修改锁标志位。当出现锁竞争的情况时,JVM 会尝试进行一段短暂的自旋(也称为空闲自旋或忙等待),以等待锁的释放。这个自旋过程是为了避免线程进入阻塞状态,以提高锁竞争的效率。
- 重量级锁:JVM 会尝试调用操作系统进行加锁,同时会将锁的标记位 CAS 修正为 “10” ,表示锁已经升级为重量级锁。没有抢占到锁的线程会被加入到系统内的等待队列中等待唤醒。
我们可以近似地理解,偏向锁和轻量级锁都是系统通过 CAS 修改对象头中的锁标记位来实现的,只有重量级锁才会调用操作系统内核进行加锁或者入队操作。一个是只需要修改点东西就能实现,一个是需要入队、阻塞、唤醒、出队等诸多步骤才能实现,谁快谁慢不言而喻!
volatile
- 可见性:保证对
volatile变量的写操作会立即刷新到主内存,并且每次读操作都会从主内存重新读取,绕过工作内存。 - 有序性:通过添加内存屏障来禁止指令重排序。
- 注意:
volatile不保证原子性(例如volatile int i; i++仍然不是原子操作)。
final
只要在构造函数中正确初始化了 final 字段,并且没有“this”引用逸出,那么其他线程就能看到最终初始化后的值,无需同步。
“逸出”有点抽象,我们还是举个例子吧,在下面例子中,在构造函数里面将this赋值给了全局变量global.obj,这就是“逸出”,线程通过global.obj读取x是有可能读到0的。因此我们一定要避免“逸出”。
1 | final int x; |
如何预防死锁
并发程序一旦死锁,一般没有特别好的方法,很多时候我们只能重启应用。因此,解决死锁问题最好的办法还是规避死锁。
只有以下这四个条件都发生时才会出现死锁:
- 互斥,共享资源X和Y只能被一个线程占用;
- 占有且等待,线程T1已经取得共享资源X,在等待共享资源Y的时候,不释放共享资源X;
- 不可抢占,其他线程不能强行抢占线程T1占有的资源;
- 循环等待,线程T1等待线程T2占有的资源,线程T2等待线程T1占有的资源,就是循环等待。
反过来分析,也就是说只要我们破坏其中一个,就可以成功避免死锁的发生。
其中,互斥这个条件我们没有办法破坏,因为我们用锁为的就是互斥。不过其他三个条件都是有办法破坏掉的,到底如何做呢?
- 对于“占用且等待”这个条件,我们可以一次性申请所有的资源,这样就不存在等待了。
- 对于“不可抢占”这个条件,占用部分资源的线程进一步申请其他资源时,如果申请不到,可以主动释放它占有的资源,这样不可抢占这个条件就破坏掉了。
- 对于“循环等待”这个条件,可以靠按序申请资源来预防。所谓按序申请,是指资源是有线性顺序的,申请的时候可以先申请资源序号小的,再申请资源序号大的,这样线性化后自然就不存在循环了。
活锁
有时线程虽然没有发生阻塞,但仍然会存在执行不下去的情况,这就是所谓的“活锁”。
以类比现实世界里的例子,路人甲从左手边出门,路人乙从右手边进门,两人为了不相撞,互相谦让,路人甲让路走右手边,路人乙也让路走左手边,结果是两人又相撞了。这种情况,基本上谦让几次就解决了,因为人会交流啊。可是如果这种情况发生在编程世界了,就有可能会一直没完没了地“谦让”下去,成为没有发生阻塞但依然执行不下去的“活锁”。
解决“活锁”的方案很简单,谦让时,尝试等待一个随机的时间就可以了。
饥饿
所谓“饥饿”指的是线程因无法访问所需资源而无法执行下去的情况。
如果线程优先级“不均”,在CPU繁忙的情况下,优先级低的线程得到执行的机会很小,就可能发生线程“饥饿”;持有锁的线程,如果执行的时间过长,也可能导致“饥饿”问题。
解决“饥饿”问题的方案很简单,有三种方案:一是保证资源充足,二是公平地分配资源,三就是避免持有锁的线程长时间执行。这三个方案中,方案一和方案三的适用场景比较有限,因为很多场景下,资源的稀缺性是没办法解决的,持有锁的线程执行的时间也很难缩短。倒是方案二的适用场景相对来说更多一些。
用“等待-通知”机制优化循环等待
在破坏占用且等待条件的时候,如果不能一次性申请到所有资源,就用死循环的方式来循环等待。如果apply()操作耗时非常短,而且并发冲突量也不大时,这个方案还挺不错的,但是如果apply()操作耗时长,或者并发冲突量大的时候,循环等待这种方案就不适用了,因为在这种场景下,可能要循环上万次才能获取到锁,太消耗CPU了。
用synchronized实现等待-通知机制
在Java语言里,等待-通知机制可以有多种实现方式,比如Java语言内置的synchronized配合wait()、notify()、notifyAll()这三个方法就能轻松实现。
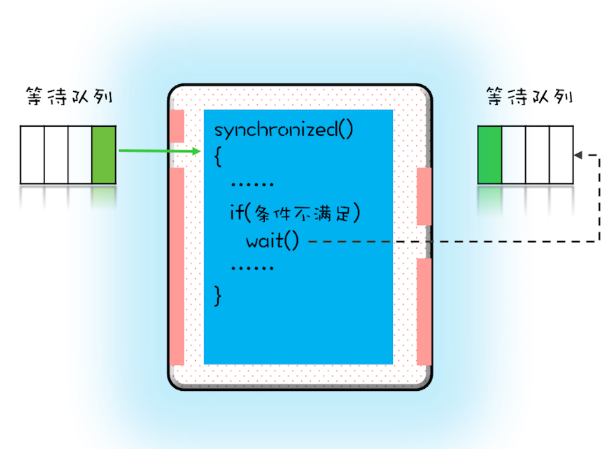
在并发程序中,当一个线程进入临界区后,由于某些条件不满足,需要进入等待状态,Java对象的wait()方法就能够满足这种需求。如上图所示,当调用wait()方法后,当前线程就会被阻塞,并且进入到右边的等待队列中,这个等待队列也是互斥锁的等待队列。 线程在进入等待队列的同时,会释放持有的互斥锁,线程释放锁后,其他线程就有机会获得锁,并进入临界区了。
那线程要求的条件满足时,该怎么通知这个等待的线程呢?很简单,就是Java对象的notify()和notifyAll()方法。我在下面这个图里为你大致描述了这个过程,当条件满足时调用notify(),会通知等待队列(互斥锁的等待队列)中的线程,告诉它条件曾经满足过。
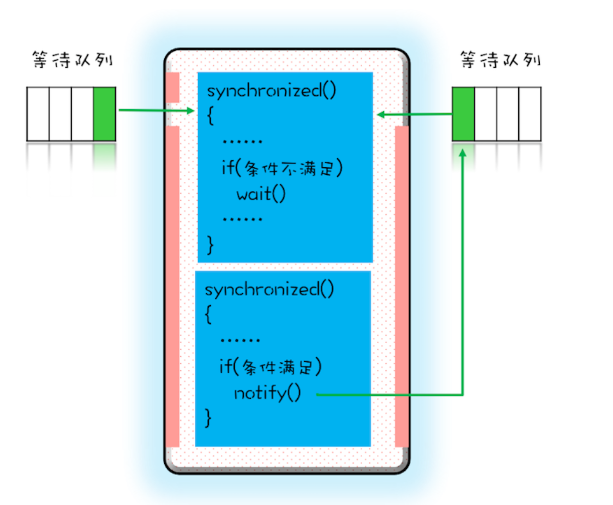
为什么说是曾经满足过呢?因为notify()只能保证在通知时间点,条件是满足的。而被通知线程的执行时间点和通知的时间点基本上不会重合,所以当线程执行的时候,很可能条件已经不满足了(保不齐有其他线程插队)。这一点你需要格外注意。
除此之外,还有一个需要注意的点,被通知的线程要想重新执行,仍然需要获取到互斥锁(因为曾经获取的锁在调用wait()时已经释放了)。
notify()是会随机地通知等待队列中的一个线程,而notifyAll()会通知等待队列中的所有线程。
假设我们有资源A、B、C、D,线程1申请到了AB,线程2申请到了CD,此时线程3申请AB,会进入等待队列(AB分配给线程1,线程3要求的条件不满足),线程4申请CD也会进入等待队列。我们再假设之后线程1归还了资源AB,如果使用notify()来通知等待队列中的线程,有可能被通知的是线程4,但线程4申请的是CD,所以此时线程4还是会继续等待,而真正该唤醒的线程3就再也没有机会被唤醒了。
创建多少线程才是合适的
在并发编程领域,提升性能本质上就是提升硬件的利用率,再具体点来说,就是提升I/O的利用率和CPU的利用率。
如果只有一个线程,执行CPU计算的时候,I/O设备空闲;执行I/O操作的时候,CPU空闲,所以CPU的利用率和I/O设备的利用率都是50%。
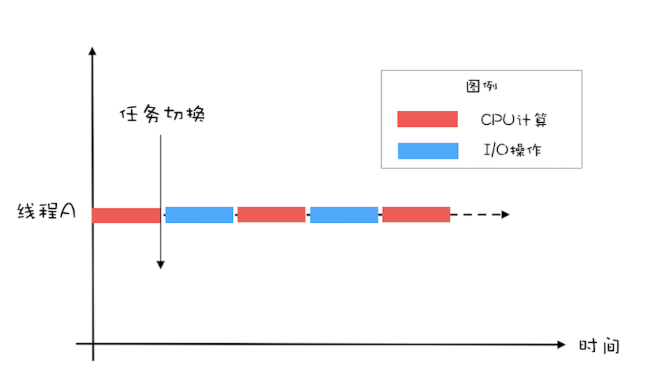
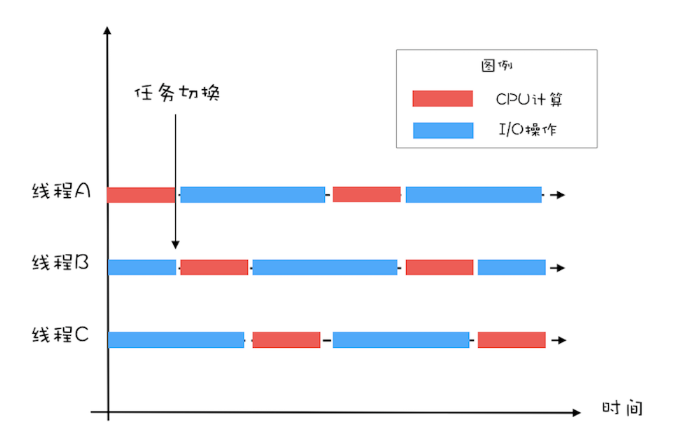
如果有两个线程,如下图所示,当线程A执行CPU计算的时候,线程B执行I/O操作;当线程A执行I/O操作的时候,线程B执行CPU计算,这样CPU的利用率和I/O设备的利用率就都达到了100%。
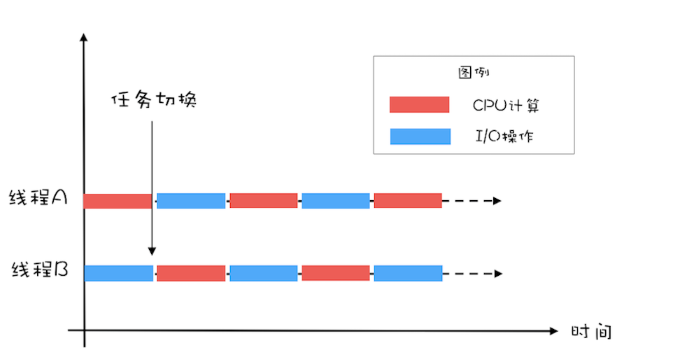
通过上面的图示,很容易看出:单位时间处理的请求数量翻了一番,也就是说吞吐量提高了1倍。
对于CPU密集型计算,多线程本质上是提升多核CPU的利用率,所以对于一个4核的CPU,每个核一个线程,理论上创建4个线程就可以了,再多创建线程也只是增加线程切换的成本。所以,对于CPU密集型的计算场景,理论上“线程的数量=CPU核数”就是最合适的。不过在工程上,线程的数量一般会设置为“CPU核数+1”,这样的话,当线程因为偶尔的内存页失效或其他原因导致阻塞时,这个额外的线程可以顶上,从而保证CPU的利用率。
对于I/O密集型的计算场景,比如前面我们的例子中,如果CPU计算和I/O操作的耗时是1:1,那么2个线程是最合适的。如果CPU计算和I/O操作的耗时是1:2,那多少个线程合适呢?是3个线程,如下图所示:CPU在A、B、C三个线程之间切换,对于线程A,当CPU从B、C切换回来时,线程A正好执行完I/O操作。这样CPU和I/O设备的利用率都达到了100%。
通过上面这个例子,我们会发现,对于I/O密集型计算场景,最佳的线程数是与程序中CPU计算和I/O操作的耗时比相关的,我们可以总结出这样一个公式:
最佳线程数=1 +(I/O耗时 / CPU耗时)
不过上面这个公式是针对单核CPU的,至于多核CPU,也很简单,只需要等比扩大就可以了,计算公式如下:
最佳线程数=CPU核数 * [ 1 +(I/O耗时 / CPU耗时)]
最佳线程数最终还是靠压测来确定的,实际工作中大家面临的系统,“I/O耗时 / CPU耗时”往往都大于1,所以基本上都是在这个初始值的基础上增加。增加的过程中,应关注线程数是如何影响吞吐量和延迟的。
实际工作中,不同的I/O模型对最佳线程数的影响非常大,例如大名鼎鼎的Nginx用的是非阻塞I/O,采用的是多进程单线程结构,Nginx本来是一个I/O密集型系统,但是最佳进程数设置的却是CPU的核数,完全参考的是CPU密集型的算法。所以,理论我们还是要活学活用。
Semaphore:快速实现一个限流器
Semaphore可以允许多个线程访问一个临界区。
比较常见的需求就是我们工作中遇到的各种池化资源,例如连接池、对象池、线程池等等。所谓对象池呢,指的是一次性创建出N个对象,之后所有的线程重复利用这N个对象,当然对象在被释放前,也是不允许其他线程使用的。
1 | class ObjPool<T, R> { |
我们用一个List来保存对象实例,用Semaphore实现限流器。关键的代码是ObjPool里面的exec()方法,这个方法里面实现了限流的功能。
在这个方法里面,我们首先调用acquire()方法(与之匹配的是在finally里面调用release()方法),假设对象池的大小是10,信号量的计数器初始化为10,那么前10个线程调用acquire()方法,都能继续执行,相当于通过了信号灯,而其他线程则会阻塞在acquire()方法上。对于通过信号灯的线程,我们为每个线程分配了一个对象 t(这个分配工作是通过pool.remove(0)实现的),分配完之后会执行一个回调函数func,而函数的参数正是前面分配的对象 t ;执行完回调函数之后,它们就会释放对象(这个释放工作是通过pool.add(t)实现的),同时调用release()方法来更新信号量的计数器。如果此时信号量里计数器的值小于等于0,那么说明有线程在等待,此时会自动唤醒等待的线程。
简言之,使用信号量,我们可以轻松地实现一个限流器。
ReadWriteLock:快速实现一个完备的缓存
用ReadWriteLock快速实现一个通用的缓存工具类。
1 | class Cache<K,V> { |
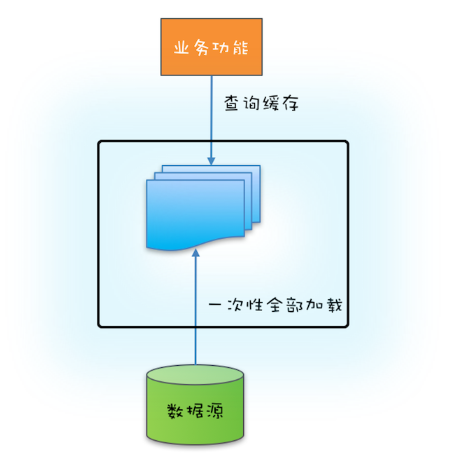
如果源头数据的数据量不大,就可以采用一次性加载的方式,这种方式最简单(可参考下图),只需在应用启动的时候把源头数据查询出来,依次调用类似上面示例代码中的put()方法就可以了。
如果源头数据量非常大,那么就需要按需加载了,按需加载也叫懒加载,指的是只有当应用查询缓存,并且数据不在缓存里的时候,才触发加载源头相关数据进缓存的操作。
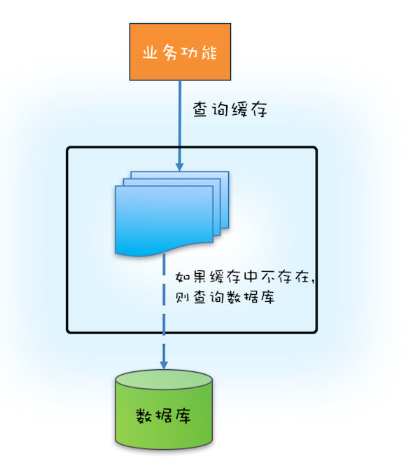
下面你可以结合文中示意图看看如何利用ReadWriteLock 来实现缓存的按需加载。
如果缓存中没有缓存目标对象,那么就需要从数据库中加载,然后写入缓存,写缓存需要用到写锁,所以在代码中的⑤处,我们调用了 w.lock() 来获取写锁。
另外,还需要注意的是,在获取写锁之后,我们并没有直接去查询数据库,而是在代码⑥⑦处,重新验证了一次缓存中是否存在,再次验证如果还是不存在,我们才去查询数据库并更新本地缓存。为什么我们要再次验证呢?
1 | class Cache<K,V> { |
原因是在高并发的场景下,有可能会有多线程竞争写锁。假设缓存是空的,没有缓存任何东西,如果此时有三个线程T1、T2和T3同时调用get()方法,并且参数key也是相同的。那么它们会同时执行到代码⑤处,但此时只有一个线程能够获得写锁,假设是线程T1,线程T1获取写锁之后查询数据库并更新缓存,最终释放写锁。此时线程T2和T3会再有一个线程能够获取写锁,假设是T2,如果不采用再次验证的方式,此时T2会再次查询数据库。T2释放写锁之后,T3也会再次查询一次数据库。而实际上线程T1已经把缓存的值设置好了,T2、T3完全没有必要再次查询数据库。所以,再次验证的方式,能够避免高并发场景下重复查询数据的问题。
读写锁的升级与降级
上面按需加载的示例代码中,在①处获取读锁,在③处释放读锁,那是否可以在②处的下面增加验证缓存并更新缓存的逻辑呢?详细的代码如下。
1 | //读缓存 |
这样看上去好像是没有问题的,先是获取读锁,然后再升级为写锁,对此还有个专业的名字,叫锁的升级。可惜ReadWriteLock并不支持这种升级。在上面的代码示例中,读锁还没有释放,此时获取写锁,会导致写锁永久等待,最终导致相关线程都被阻塞,永远也没有机会被唤醒。锁的升级是不允许的,这个你一定要注意。
不过,虽然锁的升级是不允许的,但是锁的降级却是允许的。以下代码来源自ReentrantReadWriteLock的官方示例,略做了改动。你会发现在代码①处,获取读锁的时候线程还是持有写锁的,这种锁的降级是支持的。
1 | class CachedData { |
StampedLock:读多写少性能最佳锁
StampedLock支持的三种锁模式
StampedLock支持三种模式,分别是:写锁、悲观读锁和乐观读。其中,写锁、悲观读锁的语义和ReadWriteLock的写锁、读锁的语义非常类似,允许多个线程同时获取悲观读锁,但是只允许一个线程获取写锁,写锁和悲观读锁是互斥的。不同的是:StampedLock里的写锁和悲观读锁加锁成功之后,都会返回一个stamp;然后解锁的时候,需要传入这个stamp。相关的示例代码如下。
1 | final StampedLock sl = new StampedLock(); |
StampedLock的性能之所以比ReadWriteLock还要好,其关键是StampedLock支持乐观读的方式。ReadWriteLock支持多个线程同时读,但是当多个线程同时读的时候,所有的写操作会被阻塞;而StampedLock提供的乐观读,是允许一个线程获取写锁的,也就是说不是所有的写操作都被阻塞。
乐观读这个操作是无锁的,所以相比较ReadWriteLock的读锁,乐观读的性能更好一些。
1 | class Point { |
如果执行乐观读操作的期间,存在写操作,会把乐观读升级为悲观读锁。这个做法挺合理的,否则你就需要在一个循环里反复执行乐观读,直到执行乐观读操作的期间没有写操作(只有这样才能保证x和y的正确性和一致性),而循环读会浪费大量的CPU。
StampedLock在命名上并没有增加Reentrant,StampedLock不支持重入。
还有一点需要特别注意,那就是:如果线程阻塞在StampedLock的readLock()或者writeLock()上时,此时调用该阻塞线程的interrupt()方法,会导致CPU飙升。
1 | inal StampedLock lock |
所以,使用StampedLock一定不要调用中断操作,如果需要支持中断功能,一定使用可中断的悲观读锁readLockInterruptibly()和写锁writeLockInterruptibly()。
CountDownLatch和CyclicBarrier:如何让多线程步调一致
CountDownLatch和CyclicBarrier都是线程同步的工具类。
CountDownLatch允许一个或多个线程一直等待,直到这些线程完成它们的操作。
而CyclicBarrier是允许一组线程之间互相等待,它往往是当线程到达某状态后,暂停下来等待其他线程,等到所有线程均到达后,才继续执行。
可以发现这两者等待的主体是不一样的。
CountDownLatch调用await()通常是主线程/调用线程,而CyclicBarrier调用await()是在任务线程调用的。
所以,CyclicBarrier中的阻塞的是任务的线程,而主线程是不受影响的。
这两个类都是基于AQS实现的。
当我们构建CountDownLatch对象时,传入的值其实就会赋值给AQS的关键变量state
执行countDown方法时,其实就是利用CAS将state减1。
执行await方法时,其实就是判断state是否为0,不为0则加入到队列中,将该线程阻塞掉(除了头节点)。
因为头节点会一直自旋等待state为0,当state为0时,头节点把剩余的在队列中阻塞的节点也一并唤醒。
而CyclicBarrier是直接借助ReentranLock加上Condition等待唤醒功能,进而实现的。
在构建CyclicBarrier时,传入的值会赋值给CyclicBarrier内部维护的count变量,也会赋值给parties变量(这是可以复用的关键)。
每次调用await时,会将count-1,操作count值是直接使用ReentrantLock来保证线程安全性。
如果count不为0,则添加condition队列中,
如果count等于0,则把节点从condition队列添加至AQS的队列中进行全部唤醒,并且将parties的值重新赋值为count的值(实现复用)。
并发容器
List
List里面只有一个实现类就是CopyOnWriteArrayList。CopyOnWrite,顾名思义就是写的时候会将共享变量新复制一份出来,这样做的好处是读操作完全无锁。
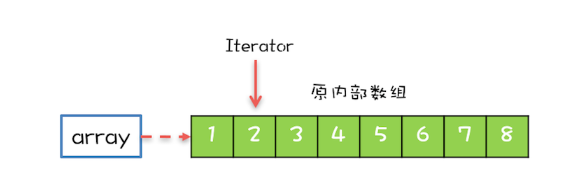
CopyOnWriteArrayList内部维护了一个数组,成员变量array就指向这个内部数组,所有的读操作都是基于array进行的,如下图所示,迭代器Iterator遍历的就是array数组。
如果在遍历array的同时,还有一个写操作,例如增加元素,CopyOnWriteArrayList是如何处理的呢?CopyOnWriteArrayList会将array复制一份,然后在新复制处理的数组上执行增加元素的操作,执行完之后再将array指向这个新的数组。通过下图你可以看到,读写是可以并行的,遍历操作一直都是基于原array执行,而写操作则是基于新array进行。
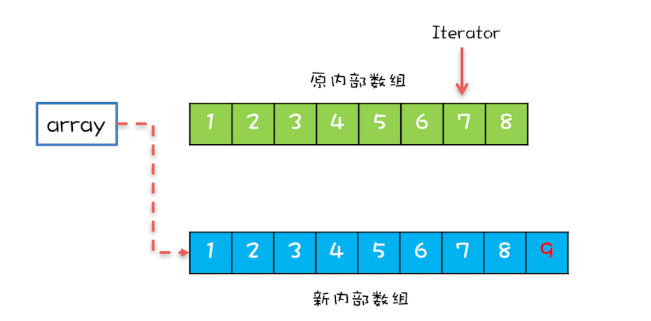
使用CopyOnWriteArrayList需要注意的“坑”主要有两个方面。一个是应用场景,CopyOnWriteArrayList仅适用于写操作非常少的场景,而且能够容忍读写的短暂不一致。例如上面的例子中,写入的新元素并不能立刻被遍历到。另一个需要注意的是,CopyOnWriteArrayList迭代器是只读的,不支持增删改。因为迭代器遍历的仅仅是一个快照,而对快照进行增删改是没有意义的。
Map
Map接口的两个实现是ConcurrentHashMap和ConcurrentSkipListMap,它们从应用的角度来看,主要区别在于ConcurrentHashMap的key是无序的,而ConcurrentSkipListMap的key是有序的。所以如果你需要保证key的顺序,就只能使用ConcurrentSkipListMap。
使用ConcurrentHashMap和ConcurrentSkipListMap需要注意的地方是,它们的key和value都不能为空,否则会抛出NullPointerException这个运行时异常。
ConcurrentHashMap 为什么 key 和 value 不能为 null?
key 和 value 不能为 null 主要是为了避免二义性。null 是一个特殊的值,表示没有对象或没有引用。如果你用null作为键,那么你就无法区分这个键是否存在于ConcurrentHashMap中,还是根本没有这个键。同样,如果你用null作为值,那么你就无法区分这个值是否是真正存储在ConcurrentHashMap中的,还是因为找不到对应的键而返回的。
拿 get 方法取值来说,返回的结果为 null 存在两种情况: - 值没有在集合中 ; - 值本身就是 null。 这也就是二义性的由来。 具体可以参考 [ConcurrentHashMap 源码分析]( ConcurrentHashMap 源码分析 | JavaGuide(Java面试 学习指南) ) 。
多线程环境下,存在一个线程操作该ConcurrentHashMap时,其他的线程将该ConcurrentHashMap修改的情况,所以无法通过 containsKey(key)来判断否存在这个键值对,也就没办法解决二义性问题了。 与此形成对比的是,HashMap 可以存储 null 的 key 和 value,但 null 作为键只能有一个,null 作为值可以有多个。如果传入null作为参数,就会返回hash值为0的位置的值。单线程环境下,不存在一个线程操作该HashMap时,其他的线程将该HashMap修改的情况,所以可以通过contains(key)来做判断是否存在这个键值对,从而做相应的处理,也就不存在二义性问题。
为什么源码不设计成可以判断是否存在null值的key?
正如上面所述,如果允许key为null,那么就会带来很多不必要的麻烦和开销。比如,你需要用额外的数据结构或者标志位来记录哪些key是null的,而且在多线程环境下,还要保证对这些额外的数据结构或者标志位的操作也是线程安全的。而且,key为null的意义也不大,因为它并不能表示任何有用的信息。 如果你确实需要在 ConcurrentHashMap 中使用 null 的话,可以使用一个特殊的静态空对象来代替 null。 java public static final Object NULL = new Object();
containsKey方法后被修改,导致不可重复读,算线程不安全吗?
ConcurrentHashMap 是线程安全的,但它不能保证所有的复合操作都是原子性的。如果需要保证复合操作的原子性,就要使用额外的同步或协调机制。这并不违反线程安全的定义,而是属于不同层次的一致性要求。 containsKey() 和 get() 方法都是单独的操作,它们之间没有同步保证。因此,如果在调用 containsKey() 后,另一个线程修改或删除了相应的键值对,那么 get() 方法可能会返回 null 或者过期的值。这确实是不可重复读的情况,但这并不违反线程安全的定义。 为什么不提供类似for update的方法呢? Java 8中,ConcurrentHashMap增加了一些原子更新操作的方法,如compute、computeIfAbsent、computeIfPresent、merge等等。这些方法都可以接受一个函数作为参数,根据给定的key和value来计算一个新的value,并且将其更新到map中。
ConcurrentSkipListMap里面的SkipList本身就是一种数据结构,中文一般都翻译为“跳表”。跳表插入、删除、查询操作平均的时间复杂度是 O(log n),理论上和并发线程数没有关系,所以在并发度非常高的情况下,若你对ConcurrentHashMap的性能还不满意,可以尝试一下ConcurrentSkipListMap。
Set
Set接口的两个实现是CopyOnWriteArraySet和ConcurrentSkipListSet,使用场景可以参考前面讲述的CopyOnWriteArrayList和ConcurrentSkipListMap,它们的原理都是一样的,这里就不再赘述了。
Queue
Java并发包里面Queue这类并发容器是最复杂的,你可以从以下两个维度来分类。
一个维度是阻塞与非阻塞,所谓阻塞指的是当队列已满时,入队操作阻塞;当队列已空时,出队操作阻塞。
另一个维度是单端与双端,单端指的是只能队尾入队,队首出队;而双端指的是队首队尾皆可入队出队。Java并发包里阻塞队列都用Blocking关键字标识,单端队列使用Queue标识,双端队列使用Deque标识。
这两个维度组合后,可以将Queue细分为四大类,分别是:
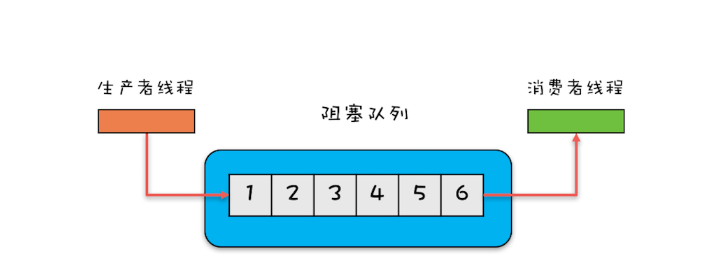
1.单端阻塞队列:其实现有ArrayBlockingQueue、LinkedBlockingQueue、SynchronousQueue、LinkedTransferQueue、PriorityBlockingQueue和DelayQueue。
内部一般会持有一个队列,这个队列可以是数组(其实现是ArrayBlockingQueue)也可以是链表(其实现是LinkedBlockingQueue);甚至还可以不持有队列(其实现是SynchronousQueue),此时生产者线程的入队操作必须等待消费者线程的出队操作。
而LinkedTransferQueue融合LinkedBlockingQueue和SynchronousQueue的功能,性能比LinkedBlockingQueue更好;
PriorityBlockingQueue支持按照优先级出队;
DelayQueue支持延时出队。
2.双端阻塞队列:其实现是LinkedBlockingDeque。
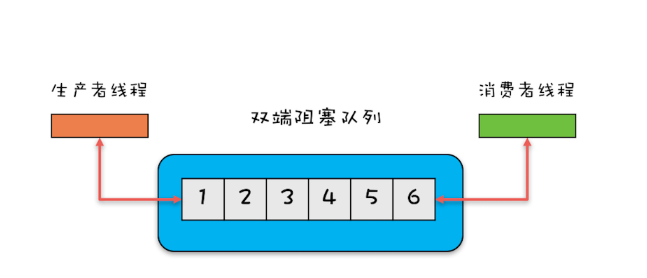
3.单端非阻塞队列:其实现是ConcurrentLinkedQueue。
4.双端非阻塞队列:其实现是ConcurrentLinkedDeque。
使用队列时,需要格外注意队列是否支持有界(所谓有界指的是内部的队列是否有容量限制)。实际工作中,一般都不建议使用无界的队列,因为数据量大了之后很容易导致OOM。
上面我们提到的这些Queue中,只有ArrayBlockingQueue和LinkedBlockingQueue是支持有界的,所以在使用其他无界队列时,一定要充分考虑是否存在导致OOM的隐患。
无锁方案实现原理
CAS
只有当目前count的值和期望值expect相等时,才会将count更新为newValue。
1 | class SimulatedCAS{ |
使用CAS来解决并发问题,一般都会伴随着自旋,而所谓自旋,其实就是循环尝试。
1 | class SimulatedCAS{ |
但是在CAS方案中,有一个问题可能会常被你忽略,那就是ABA的问题。
前面我们提到“如果cas(count,newValue)返回的值不等于count,意味着线程在执行完代码①处之后,执行代码②处之前,count的值被其他线程更新过”,那如果cas(count,newValue)返回的值等于count,是否就能够认为count的值没有被其他线程更新过呢?显然不是的,假设count原本是A,线程T1在执行完代码①处之后,执行代码②处之前,有可能count被线程T2更新成了B,之后又被T3更新回了A,这样线程T1虽然看到的一直是A,但是其实已经被其他线程更新过了,这就是ABA问题。
解决ABA问题的最简单粗暴的方式就是加个版本号,每更新过一次就+1,这样即使更新回了原值,也会被记录下来。
我们所熟知的原子类AtomicLong的底层就是CAS实现的,在Java 1.8版本中,getAndIncrement()方法会转调unsafe.getAndAddLong()方法。
1 | final long getAndIncrement() { |
unsafe.getAndAddLong()方法的源码如下,该方法首先会在内存中读取共享变量的值,之后循环调用compareAndSwapLong()方法来尝试设置共享变量的值,直到成功为止。compareAndSwapLong()是一个native方法,只有当内存中共享变量的值等于expected时,才会将共享变量的值更新为x,并且返回true;否则返回fasle。compareAndSwapLong的语义和CAS指令的语义的差别仅仅是返回值不同而已。
1 | public final long getAndAddLong( |
Java提供的原子类里面CAS一般被实现为compareAndSet(),compareAndSet()的语义和CAS指令的语义的差别仅仅是返回值不同而已,compareAndSet()里面如果更新成功,则会返回true,否则返回false。
AQS:保证并发安全的终极奥秘
AQS 是 Java 并发包的核心,它的理念和设计思想贯穿于 Java 中许多并发工具和框架,如 ReentrantLock、Semaphore、CountDownLatch 等。
AQS 在 ReentrantLock 的应用
我们来使用一张图来描述 ReentrantLock 对于 AQS 的应用:
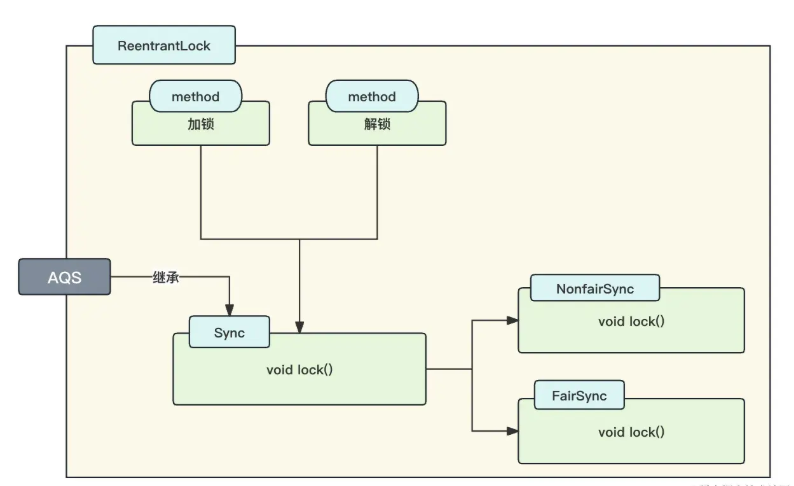
我们分析下上图,在 ReetrantLock 中存在加锁和解锁两个方法,这两个方法是借助 Sync 这个内部类来完成的。Sync 这个内部类实现了 AQS 抽象类,并实现了公平锁和非公平锁两种加锁方式!
公平锁的 FairSync#tryAcquire
1 | protected final boolean tryAcquire(int acquires) { |
上面代码的注释能够印证出我们前面所学的,公平锁、可重入锁、CAS 的特性。
- 首先进行加锁的时候,因为公平锁的原因,会先判断等待队列中是否存在任务。如果存在,就不能去加锁,需要去排队!如果没有排队的任务,那么就开始使用 CAS 进行加锁,此时可能会出现其他线程也在加锁,如果其他线程加锁成功,那么此时 CAS 就会返回 false。
- 假设上面的加锁条件全部满足,就能够加锁成功,它会将 state 变为 1,将当前线程设置到一个变量中去,并且为了保证重入锁的特性,将当前线程保存到变量中,表示这个线程持有这把锁。
- 如果上面的加锁条件不满足,不会第一时间就返回加锁失败,因为 ReentrantLock 是可重入锁,所以在加锁失败后,会判断当前持有锁的线程和所需要加锁的线程是不是一个,如果是一个就附和可重入锁的特性,那么就把加锁数量 +1,同时返回加锁成功。
- 如果全部都不满足,则直接返回 false,加锁失败。
我们使用一个图来理解这个流程:
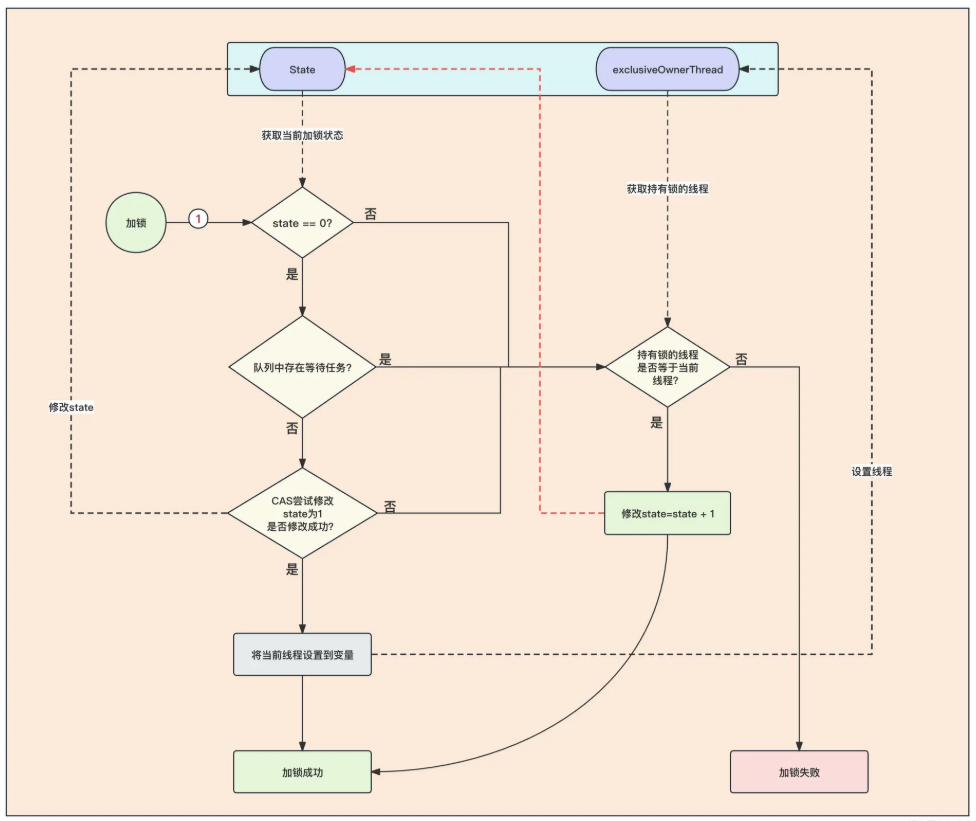
线程加锁失败后,会开始进行入队操作,也就是 addWaiter 方法。AQS 的队列与传统队列不同,AQS 的队列是一个双向链表,排队的线程都是用 next 指向下一个节点任务。head 节点可能为空,因为当第一个任务入队的时候,会初始化 head 节点,head 节点内线程数据为空,但是 head 节点的 next 会指向第一个等待线程。
1 | private Node addWaiter(Node mode) { |
以下是整个AQS的执行流程及加锁逻辑:
简单来说,加锁无非就是通过 CAS 去改变 State 的值,等于 0 且能改变成功就加锁成功,如果改变失败,就入队后阻塞。
解锁流程:
- 解锁就是对 state 进行减一操作(重入次数 -1),当 state = 0 的时候,就将持有锁的线程设置为 null,且返回解锁的结果。
- 因为
ReentrantLock是可重入锁,一个线程多次获取锁,state 的数量会大于 1,当解锁的时候,必须当前线程解锁次数 = 加锁次数才能解锁成功,否则解锁失败。 - 无论是解锁成功与否,都必须将当前 state 的数量使用 CAS 更新为最新的。
解锁成功后,会调用 head 节点后的等到任务的 unPark 解锁线程,使得阻塞的线程重新开始循环获取锁的操作,直到获取锁成功。
- 公平锁当发现 state = 0 也就是没有任务占有锁的情况下,会判断队列中是存在等待任务,如果存在就会加锁失败,然后执行入队操作。
- 而非公平锁发现 state = 0 也就是没有任务占有锁的情况下,会直接进行 CAS 加锁,只要 CAS 加锁成功了,就会直接返回加锁成功而不会进行入队操作
AQS 在 CountDownLatch 的应用
与 ReentrantLock 相同的是,我们同样可以在 CountDownLatch 中寻找到 AQS 的实现类 Sync。没错,CountDownLatch 的实现也是基于 AQS 来做的。
在初始化 CountDownLatch 的时候,我们传递了 10,然后开启了 10 个线程执行任务,每一个线程执行完毕之后都会调用 countDownLatch.countDown(); 来进行递减操作。我们在主线程调用 countDownLatch.await(); 来等待 CountDownLatch 变为 0 后,它会解除阻塞继续向下执行!
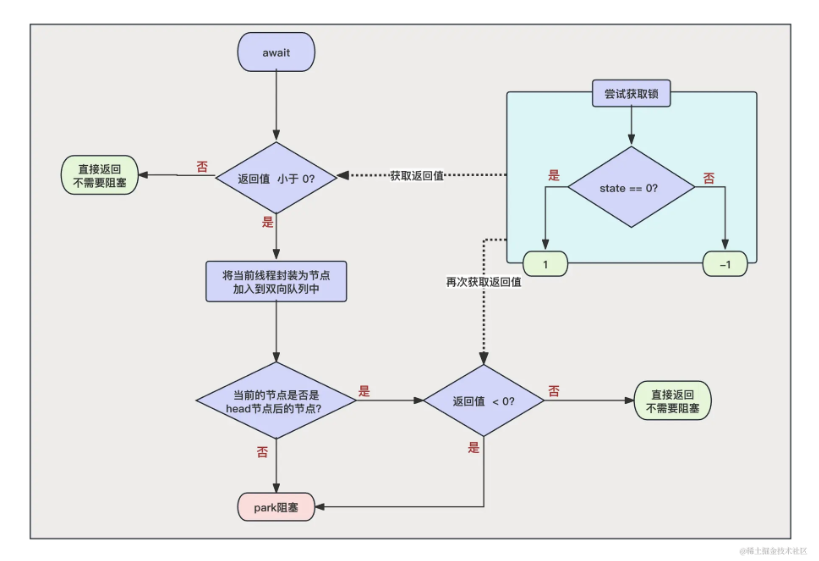
当 state 的值不为 0 的时候,证明 CountDown 还没有释放完毕,此时应该阻塞,先将当前节点加入到等待队列,然后同 ReentrantLock 一样,在阻塞之前也会先判断自己是不是 head 的下一个节点,如果是的话会再次尝试判断一下 state 是不是等于 0 了,如果此时等于 0 了,就不用阻塞了,可以直接返回。
此时如果 state 依旧不为 0,则开始与 ReentrantLock 一样调用 park 进行阻塞等待唤醒。
事实上,await 阻塞的逻辑十分简单。我们总结来说,就是当程序调用 await 方法的时候,会判断 state 的值是不是 0,如果不是 0 就阻塞,是 0 就直接返回。
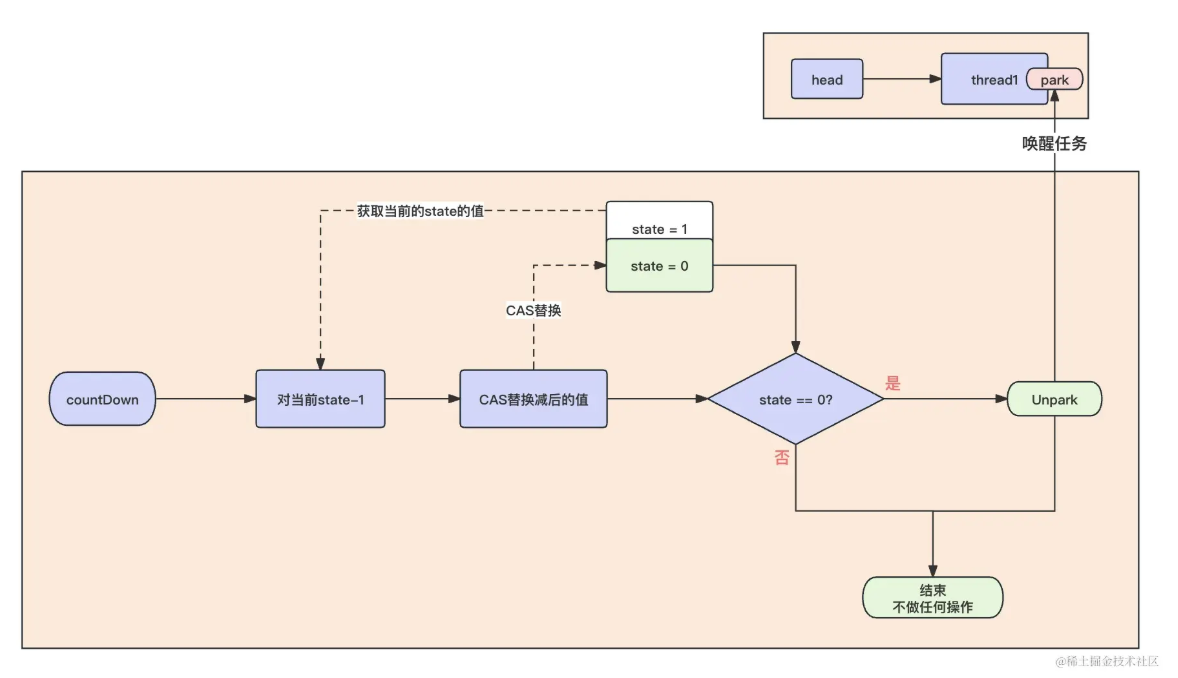
countDown 方法主要就是对 AQS 中 State 的值进行 -1 操作,当 State 的值为 0 的时候,就开始唤醒等待队列中的任务。
AQS 在 ReentrantReadWriteLock 的应用
AQS 中 state 主要是为了记录加锁的次数或者计数次数,但是在 ReentrantReadWriteLock 中存在读锁(共享锁)和写锁(独占锁)两种,那么此时只有一个 state 肯定是无法满足的,因为 state 是一个 int 值,我们知道 int 在 Java 占 32 位字节,所以我们考虑将 32 位分为高 16 位和低 16 位,如下图所示:

读锁
共享锁的加锁逻辑就是先判断是不是存在写锁,存在写锁就直接加锁失败入队,不存在就加锁成功并修改 state 的高 16 位数据,并在每一个线程维护一个计数器,来计算每一个线程加锁的次数。
共享锁的解锁比较简单,解锁过程简单来说无非就是将累加器中的累加次数 -1,同时将 state 中的高 16 位 -1(state - 65536),然后再通知等待队列中的任务进行解除阻塞。
写锁
首先,它是一个独占锁,所以我们需要先判断 state 的低 16 位是不是已经存在独占锁了,如果已经存在独占锁了,那么我们就需要判断是不是重入锁!如果 state 中已经存在独占锁了,而且也不是重入锁,那么直接加锁失败,将任务放到任务队列中就可以了。
了解了写锁的加锁步骤之后,解锁步骤能猜出来:
- 将 state - 1;
- 判断当前 state 的写锁数量,如果为 0 的话证明重入锁释放完毕,直接将加锁线程置空,并解锁成功。
Executor与线程池:如何创建正确的线程池
ThreadPoolExecutor
ThreadPoolExecutor的构造函数非常复杂,如下面代码所示,这个最完备的构造函数有7个参数。
1 | ThreadPoolExecutor( |
下面我们一一介绍这些参数的意义,你可以把线程池类比为一个项目组,而线程就是项目组的成员。
corePoolSize:表示线程池保有的最小线程数。有些项目很闲,但是也不能把人都撤了,至少要留corePoolSize个人坚守阵地。
maximumPoolSize:表示线程池创建的最大线程数。当项目很忙时,就需要加人,但是也不能无限制地加,最多就加到maximumPoolSize个人。当项目闲下来时,就要撤人了,最多能撤到corePoolSize个人。
keepAliveTime & unit:上面提到项目根据忙闲来增减人员,那在编程世界里,如何定义忙和闲呢?很简单,一个线程如果在一段时间内,都没有执行任务,说明很闲,keepAliveTime 和 unit 就是用来定义这个“一段时间”的参数。也就是说,如果一个线程空闲了
keepAliveTime & unit这么久,而且线程池的线程数大于 corePoolSize ,那么这个空闲的线程就要被回收了。workQueue:工作队列,和上面示例代码的工作队列同义。
threadFactory:通过这个参数你可以自定义如何创建线程,例如你可以给线程指定一个有意义的名字。
RejectedExecutionHandler:通过这个参数你可以自定义任务的拒绝策略。如果线程池中所有的线程都在忙碌,并且工作队列也满了(前提是工作队列是有界队列),那么此时提交任务,线程池就会拒绝接收。至于拒绝的策略,你可以通过handler这个参数来指定。ThreadPoolExecutor已经提供了以下4种策略。
CallerRunsPolicy:提交任务的线程自己去执行该任务。
- AbortPolicy:默认的拒绝策略,会throws RejectedExecutionException。
DiscardPolicy:直接丢弃任务,没有任何异常抛出。
- DiscardOldestPolicy:丢弃最老的任务,其实就是把最早进入工作队列的任务丢弃,然后把新任务加入到工作队列。
线程池处理任务流程
当我们向线程池中提交了大量的任务后,提交的任务会经历以下的历程:
- 任务开始提交后,当线程池中的线程数小于 corePoolSize 的时候,那么线程池会立即创建一个新的线程去执行这个任务,因此这个任务会被立即运行。
- 随着任务数量的提升,当线程池中的线程数大于等于 corePoolSize 且小于 maximumPoolSize 的时候,线程池会将这些任务暂时存放在 workQueue 中等待核心线程运行完毕后,来消费这些等待的任务。
- 随着任务数量还在不停地上涨,任务队列(workQueue)也放不下了,任务已经被放满,此时会开始继续新建线程去消费任务队列的任务,直到当前线程池中存活的线程数量等于 maximumPoolSize 为止。
- 此时,如果系统还在不停地提交任务,workQueue 被放满了,线程池中存活的线程数量也等于 maximumPoolSize 了,那么线程池会认为它执行不了这么多任务。为了避免出现不可预测的问题,那么超出线程池极限的这部分任务,会被线程池调用拒绝策略(Handler)来拒绝执行。
- 终于,一波任务高峰过去了,系统终于不再提交新的任务,此时 maximumPoolSize 个线程会赶紧将手头的任务执行完毕,然后开始协助消费 workQueue 中等待的任务,直至将等待队列中的任务消费完毕。此时 maximumPoolSize 个线程开始没活干了,就开始闲着,当空闲时间超过了 keepAliveTime 与 unit 所规定的空闲时间,线程池就开始回收这些空闲的线程,直至线程池中存活的线程数量等于 corePoolSize 为止。
使用线程池要注意些什么
不建议使用Executors的最重要的原因是:Executors提供的很多方法默认使用的都是无界的LinkedBlockingQueue,高负载情境下,无界队列很容易导致OOM,而OOM会导致所有请求都无法处理,这是致命问题。所以强烈建议使用有界队列。
使用有界队列,当任务过多时,线程池会触发执行拒绝策略,线程池默认的拒绝策略会throw RejectedExecutionException 这是个运行时异常,对于运行时异常编译器并不强制catch它,所以开发人员很容易忽略。因此默认拒绝策略要慎重使用。如果线程池处理的任务非常重要,建议自定义自己的拒绝策略;并且在实际工作中,自定义的拒绝策略往往和降级策略配合使用。
使用线程池,还要注意异常处理的问题,例如通过ThreadPoolExecutor对象的execute()方法提交任务时,如果任务在执行的过程中出现运行时异常,会导致执行任务的线程终止;不过,最致命的是任务虽然异常了,但是你却获取不到任何通知,这会让你误以为任务都执行得很正常。虽然线程池提供了很多用于异常处理的方法,但是最稳妥和简单的方案还是捕获所有异常并按需处理,你可以参考下面的示例代码。
1 | try { |
ThreadLocal:线程本地存储模式
Java的实现里面也有一个Map,叫做ThreadLocalMap,不过持有ThreadLocalMap的不是ThreadLocal,而是Thread。Thread这个类内部有一个私有属性threadLocals,其类型就是ThreadLocalMap,ThreadLocalMap的Key是ThreadLocal。
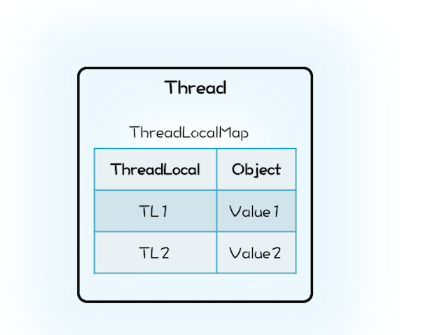
1 | class Thread { |
在Java的实现方案里面,ThreadLocal仅仅是一个代理工具类,内部并不持有任何与线程相关的数据,所有和线程相关的数据都存储在Thread里面,这样的设计容易理解。而从数据的亲缘性上来讲,ThreadLocalMap属于Thread也更加合理。
当然还有一个更加深层次的原因,那就是不容易产生内存泄露。
Java的实现中Thread持有ThreadLocalMap,而且ThreadLocalMap里对ThreadLocal的引用还是弱引用(WeakReference),所以只要Thread对象可以被回收,那么ThreadLocalMap就能被回收。
ThreadLocal与内存泄露
在线程池中使用ThreadLocal为什么可能导致内存泄露呢?
原因就出在线程池中线程的存活时间太长,往往都是和程序同生共死的,这就意味着Thread持有的ThreadLocalMap一直都不会被回收,再加上ThreadLocalMap中的Entry对ThreadLocal是弱引用(WeakReference),所以只要ThreadLocal结束了自己的生命周期是可以被回收掉的。但是Entry中的Value却是被Entry强引用的,所以即便Value的生命周期结束了,Value也是无法被回收的,从而导致内存泄露。
既然JVM不能做到自动释放对Value的强引用,那我们手动释放就可以了。
1 | ExecutorService es; |
高性能限流器Guava RateLimiter
Guava是Google开源的Java类库,提供了一个工具类RateLimiter。我们先来看看RateLimiter的使用,让你对限流有个感官的印象。假设我们有一个线程池,它每秒只能处理两个任务,如果提交的任务过快,可能导致系统不稳定,这个时候就需要用到限流。
1 | //限流器流速:2个请求/秒 |
输出结果:
…
500
499
499
500
499
经典限流算法:令牌桶算法
Guava采用的是令牌桶算法,其核心是要想通过限流器,必须拿到令牌。也就是说,只要我们能够限制发放令牌的速率,那么就能控制流速了。令牌桶算法的详细描述如下:
- 令牌以固定的速率添加到令牌桶中,假设限流的速率是 r/秒,则令牌每 1/r 秒会添加一个;
- 假设令牌桶的容量是 b ,如果令牌桶已满,则新的令牌会被丢弃;
- 请求能够通过限流器的前提是令牌桶中有令牌。
这个算法中,限流的速率 r 还是比较容易理解的,但令牌桶的容量 b 该怎么理解呢?b 其实是burst的简写,意义是限流器允许的最大突发流量。比如b=10,而且令牌桶中的令牌已满,此时限流器允许10个请求同时通过限流器,当然只是突发流量而已,这10个请求会带走10个令牌,所以后续的流量只能按照速率 r 通过限流器。
令牌桶这个算法,如何用Java实现呢?
很可能你的直觉会告诉你生产者-消费者模式:一个生产者线程定时向阻塞队列中添加令牌,而试图通过限流器的线程则作为消费者线程,只有从阻塞队列中获取到令牌,才允许通过限流器。
可实际情况却是使用限流的场景大部分都是高并发场景,而且系统压力已经临近极限了,此时这个实现就有问题了。问题就出在定时器上,在高并发场景下,当系统压力已经临近极限的时候,定时器的精度误差会非常大,同时定时器本身会创建调度线程,也会对系统的性能产生影响。
Guava如何实现令牌桶算法
Guava实现令牌桶算法,用了一个很简单的办法,其关键是记录并动态计算下一令牌发放的时间。
假设令牌桶的容量为 b=1,限流速率 r = 1个请求/秒,如下图所示,如果当前令牌桶中没有令牌,下一个令牌的发放时间是在第3秒,而在第2秒的时候有一个线程T1请求令牌,此时该如何处理呢?
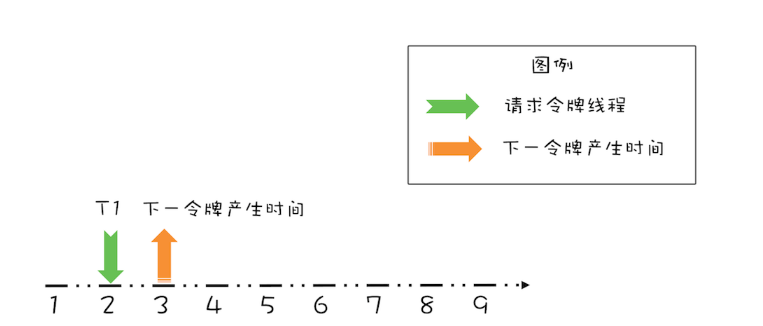
对于这个请求令牌的线程而言,很显然需要等待1秒,因为1秒以后(第3秒)它就能拿到令牌了。此时需要注意的是,下一个令牌发放的时间也要增加1秒,为什么呢?因为第3秒发放的令牌已经被线程T1预占了。处理之后如下图所示。
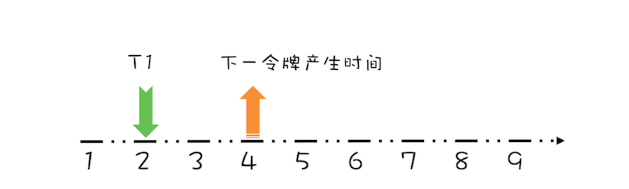
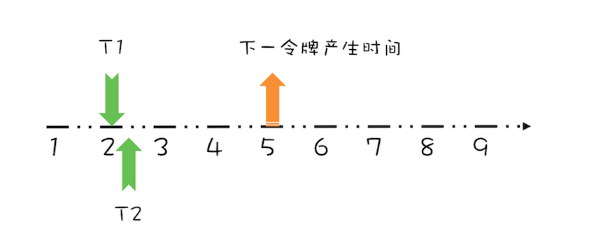
假设T1在预占了第3秒的令牌之后,马上又有一个线程T2请求令牌,如下图所示。
很显然,由于下一个令牌产生的时间是第4秒,所以线程T2要等待两秒的时间,才能获取到令牌,同时由于T2预占了第4秒的令牌,所以下一令牌产生时间还要增加1秒,完全处理之后,如下图所示。
上面线程T1、T2都是在下一令牌产生时间之前请求令牌,如果线程在下一令牌产生时间之后请求令牌会如何呢?假设在线程T1请求令牌之后的5秒,也就是第7秒,线程T3请求令牌,如下图所示。
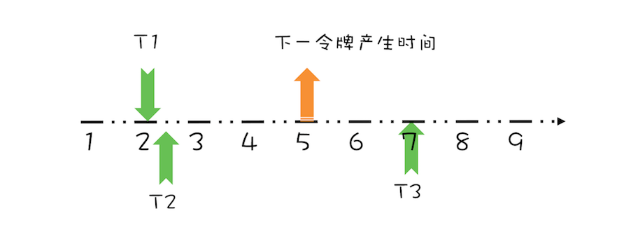
由于在第5秒已经产生了一个令牌,所以此时线程T3可以直接拿到令牌,而无需等待。在第7秒,实际上限流器能够产生3个令牌,第5、6、7秒各产生一个令牌。由于我们假设令牌桶的容量是1,所以第6、7秒产生的令牌就丢弃了,其实等价地你也可以认为是保留的第7秒的令牌,丢弃的第5、6秒的令牌,也就是说第7秒的令牌被线程T3占有了,于是下一令牌的的产生时间应该是第8秒,如下图所示。
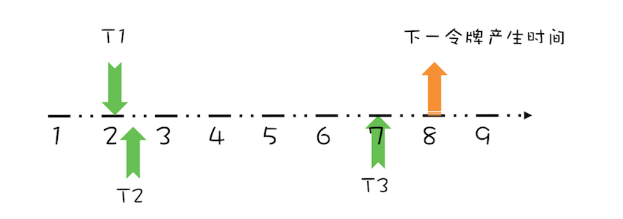
通过上面简要地分析,你会发现,我们只需要记录一个下一令牌产生的时间,并动态更新它,就能够轻松完成限流功能。
关键是reserve()方法,这个方法会为请求令牌的线程预分配令牌,同时返回该线程能够获取令牌的时间。其实现逻辑就是上面提到的:如果线程请求令牌的时间在下一令牌产生时间之后,那么该线程立刻就能够获取令牌;反之,如果请求时间在下一令牌产生时间之前,那么该线程是在下一令牌产生的时间获取令牌。由于此时下一令牌已经被该线程预占,所以下一令牌产生的时间需要加上1秒。
1 | class SimpleLimiter { |
如果令牌桶的容量大于1,又该如何处理呢?按照令牌桶算法,令牌要首先从令牌桶中出,所以我们需要按需计算令牌桶中的数量,当有线程请求令牌时,先从令牌桶中出。具体的代码实现如下所示。
我们增加了一个resync()方法,在这个方法中,如果线程请求令牌的时间在下一令牌产生时间之后,会重新计算令牌桶中的令牌数,新产生的令牌的计算公式是:(now-next)/interval,你可对照上面的示意图来理解。reserve()方法中,则增加了先从令牌桶中出令牌的逻辑,不过需要注意的是,如果令牌是从令牌桶中出的,那么next就无需增加一个 interval 了。
1 | class SimpleLimiter { |


