
kubernetes
基本概念
虽然容器技术开启了云原生时代,但它也只走出了一小步,再继续前进就无能为力了,因为这已经不再是隔离一两个进程的普通问题,而是要隔离数不清的进程,还有它们之间互相通信、互相协作的超级问题,困难程度可以说是指数级别的上升。
这些容器之上的管理、调度工作,就是这些年最流行的词汇:“容器编排”(Container Orchestration)。
面对单机上的几个容器,“人肉”编排调度还可以应付,但如果规模上到几百台服务器、成千上万的容器,处理它们之间的复杂联系就必须要依靠计算机了,而目前计算机用来调度管理的“事实标准”,就是:Kubernetes。
Kubernetes就是一个生产级别的容器编排平台和集群管理系统,不仅能够创建、调度容器,还能够监控、管理服务器。
基本架构
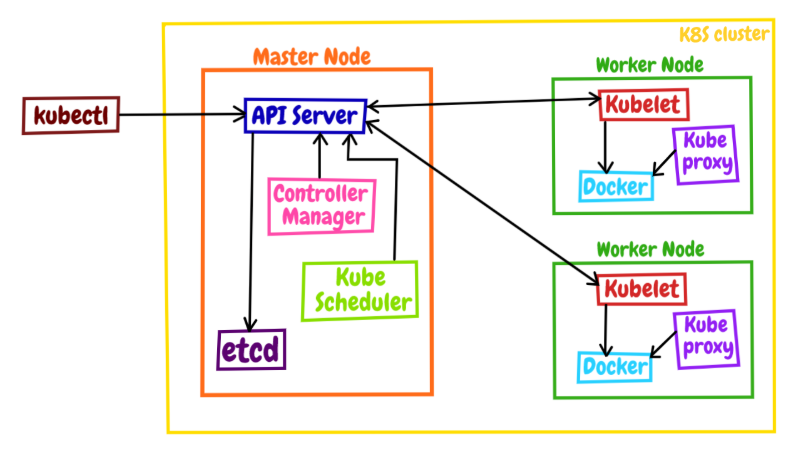
Kubernetes采用了现今流行的“控制面/数据面”(Control Plane / Data Plane)架构,集群里的计算机被称为“节点”(Node),可以是实机也可以是虚机,少量的节点用作控制面来执行集群的管理维护工作,其他的大部分节点都被划归数据面,用来跑业务应用。
控制面的节点在Kubernetes里叫做Master Node,一般简称为Master,它是整个集群里最重要的部分,可以说是Kubernetes的大脑和心脏。
数据面的节点叫做Worker Node,一般就简称为Worker或者Node,相当于Kubernetes的手和脚,在Master的指挥下干活。
Node的数量非常多,构成了一个资源池,Kubernetes就在这个池里分配资源,调度应用。因为资源被“池化”了,所以管理也就变得比较简单,可以在集群中任意添加或者删除节点。
在这张架构图里,我们还可以看到有一个kubectl,它就是Kubernetes的客户端工具,用来操作Kubernetes,但它位于集群之外,理论上不属于集群。
你可以使用命令 kubectl get node 来查看Kubernetes的节点状态:
1 | kubectl get node |

Master Node
Master里有4个组件,分别是apiserver、etcd、scheduler、controller-manager。
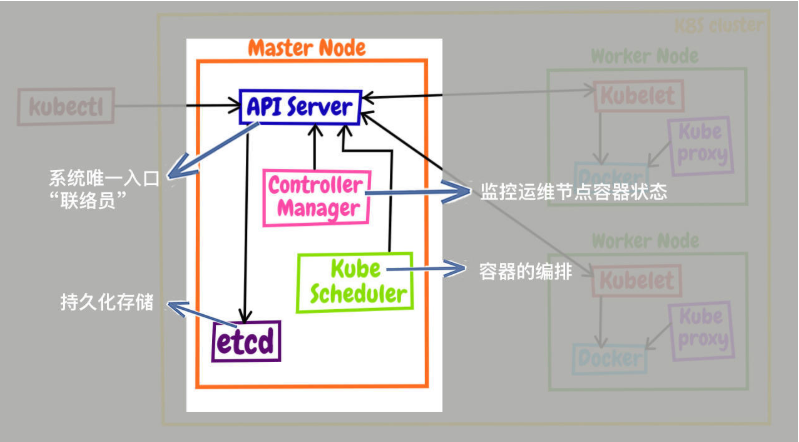
apiserver是Master节点——同时也是整个Kubernetes系统的唯一入口,它对外公开了一系列的RESTful API,并且加上了验证、授权等功能,所有其他组件都只能和它直接通信,可以说是Kubernetes里的联络员。
etcd是一个高可用的分布式Key-Value数据库,用来持久化存储系统里的各种资源对象和状态,相当于Kubernetes里的配置管理员。注意它只与apiserver有直接联系,也就是说任何其他组件想要读写etcd里的数据都必须经过apiserver。
scheduler负责容器的编排工作,检查节点的资源状态,把Pod调度到最适合的节点上运行,相当于部署人员。因为节点状态和Pod信息都存储在etcd里,所以scheduler必须通过apiserver才能获得。
controller-manager负责维护容器和节点等资源的状态,实现故障检测、服务迁移、应用伸缩等功能,相当于监控运维人员。同样地,它也必须通过apiserver获得存储在etcd里的信息,才能够实现对资源的各种操作。
这4个组件也都被容器化了,运行在集群的Pod里,我们可以用kubectl来查看它们的状态,使用命令:
1 | kubectl get pod -n kube-system |
Worker Node
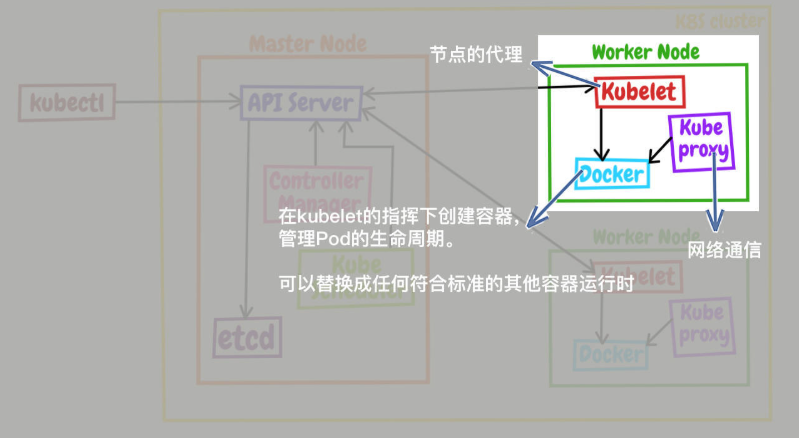
kubelet是Node的代理,负责管理Node相关的绝大部分操作,Node上只有它能够与apiserver通信,实现状态报告、命令下发、启停容器等功能,相当于是Node上的一个“小管家”。
kube-proxy的作用有点特别,它是Node的网络代理,只负责管理容器的网络通信,简单来说就是为Pod转发TCP/UDP数据包,相当于是专职的“小邮差”。
第三个组件container-runtime我们就比较熟悉了,它是容器和镜像的实际使用者,在kubelet的指挥下创建容器,管理Pod的生命周期,是真正干活的“苦力”。
工作流程
现在,我们再把Node里的组件和Master里的组件放在一起来看,就能够明白Kubernetes的大致工作流程了:
- 每个Node上的kubelet会定期向apiserver上报节点状态,apiserver再存到etcd里。
- 每个Node上的kube-proxy实现了TCP/UDP反向代理,让容器对外提供稳定的服务。
- scheduler通过apiserver得到当前的节点状态,调度Pod,然后apiserver下发命令给某个Node的kubelet,kubelet调用container-runtime启动容器。
- controller-manager也通过apiserver得到实时的节点状态,监控可能的异常情况,再使用相应的手段去调节恢复。
安装配置
Docker Desktop 自带了 Kubernetes 支持,可以通过 Docker Desktop 的应用程序界面开启 Kubernetes 集群。
而且Docker Desktop 启动 Kubernetes 后,会自动配置 kubectl 命令行工具,便于我们日常学习,减少安装成本。
Kuboard
Kuboard 是一款免费的 Kubernetes 管理工具,旨在帮助用户快速在 Kubernetes 上落地微服务。它提供了丰富的功能,包括但不限于 Kubernetes 基本管理功能、节点管理、名称空间管理、存储类/存储卷管理、控制器管理、Service/Ingress 管理、ConfigMap/Secret 管理、CustomerResourceDefinition 管理、问题诊断、容器日志及终端、认证与授权、CI/CD集成等。
拉取镜像:
1 | docker pull eipwork/kuboard:v3 |
运行命令(挂载的路径需要更改):
1 | docker run -d --name=kuboard -p 8089:80/tcp -p 10081:10081/tcp -e KUBOARD_ENDPOINT="http://192.168.3.220:8089" -e KUBOARD_AGENT_SERVER_TCP_PORT="10081" -v F:\docker\wsl\DockerDesktopWSL\mount\k8s eipwork/kuboard:v3 |
访问 Kuboard:
账号:admin
密码:Kuboard123
登录进去后,添加 Kubernetes 集群到 Kuboard

按照以下步骤执行:

导入Kuboard
1 | curl.exe -k 'http://192.168.3.220:8089/kuboard-api/cluster/Ashley-k8s/kind/KubernetesCluster/Ashley-k8s/resource/installAgentToKubernetes?token=wfzV3KBKl48kGMr6lO6CQ2lIrDGdNj5j' -o kuboard-agent.yaml |
导入之前先要执行以下两个命令
获取当前 Kubernetes 集群中的所有 Pod
1 | PS C:\Users\jr10003509> kubectl get pods |
显示当前 Kubernetes 配置中所有上下文
1 | PS C:\Users\jr10003509> kubectl config get-contexts |
切换 kubectl 操作的上下文到名为 docker-desktop 的上下文
1 | PS C:\Users\jr10003509> kubectl config use-context docker-desktop |
获取(列出)当前 Kubernetes 集群中的所有节点(Node)的信息
1 | PS C:\Users\jr10003509> kubectl get nodes |
将本地文件 .\kuboard-agent.yaml 中定义的 Kubernetes 资源对象应用到 Kubernetes 集群中。
1 | PS C:\Users\jr10003509> kubectl apply -f ./kuboard-agent.yaml |
导入成功!
API对象
Pod
Pod是对容器的“打包”,里面的容器是一个整体,总是能够一起调度、一起运行,绝不会出现分离的情况,而且Pod属于Kubernetes,可以在不触碰下层容器的情况下任意定制修改。
Kubernetes让Pod去编排处理容器,然后把Pod作为应用调度部署的最小单位,Pod也因此成为了Kubernetes世界里的“原子”(当然这个“原子”内部是有结构的,不是铁板一块),基于Pod就可以构建出更多更复杂的业务形态了。
Job/CronJob
Kubernetes里有两大类业务。一类是像Nginx这样长时间运行的“在线业务”,另一类是像busybox这样短时间运行的“离线业务”。
“在线业务”类型的应用有很多,比如Nginx、Node.js、MySQL、Redis等等,一旦运行起来基本上不会停,也就是永远在线。
而“离线业务”类型的应用也并不少见,它们一般不直接服务于外部用户,只对内部用户有意义,比如日志分析、数据建模、视频转码等等,虽然计算量很大,但只会运行一段时间。“离线业务”的特点是必定会退出,不会无期限地运行下去,所以它的调度策略也就与“在线业务”存在很大的不同,需要考虑运行超时、状态检查、失败重试、获取计算结果等管理事项。
而这些业务特性与容器管理没有必然的联系,如果由Pod来实现就会承担不必要的义务,违反了“单一职责”,所以我们应该把这部分功能分离到另外一个对象上实现,让这个对象去控制Pod的运行,完成附加的工作。
“离线业务”也可以分为两种。一种是“临时任务”,跑完就完事了,下次有需求了说一声再重新安排;另一种是“定时任务”,可以按时按点周期运行,不需要过多干预。
对应到Kubernetes里,“临时任务”就是API对象Job,“定时任务”就是API对象CronJob,使用这两个对象你就能够在Kubernetes里调度管理任意的离线业务了。
可以看到,Job对象里应用了组合模式,template 字段定义了一个“应用模板”,里面嵌入了一个Pod,这样Job就可以从这个模板来创建出Pod。而这个Pod因为受Job的管理控制,不直接和apiserver打交道,也就没必要重复apiVersion等“头字段”,只需要定义好关键的 spec,描述清楚容器相关的信息就可以了,可以说是一个“无头”的Pod对象。

而定时任务”的CronJob对象也很好理解了,使用schedule指定了执行周期,又组合了Job而生成的新对象。
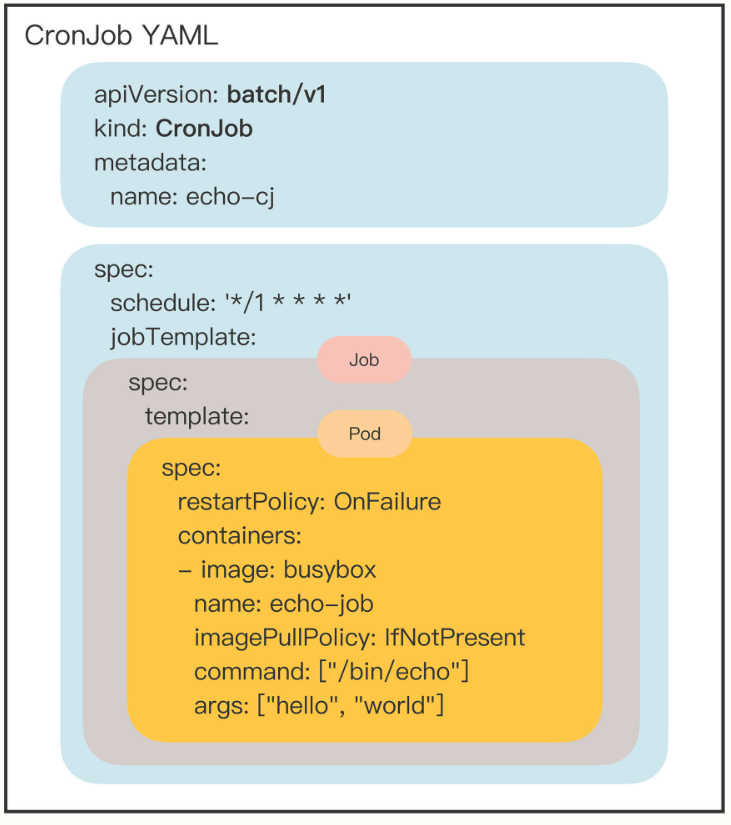
CronJob使用定时规则控制Job,Job使用并发数量控制Pod,Pod再定义参数控制容器,容器再隔离控制进程,进程最终实现业务功能,层层递进的形式有点像设计模式里的Decorator(装饰模式),链条里的每个环节都各司其职,在Kubernetes的统一指挥下完成任务。
Deployment:让应用永不宕机
在线业务远不是单纯启动一个Pod这么简单,还有多实例、高可用、版本更新等许多复杂的操作。比如最简单的多实例需求,为了提高系统的服务能力,应对突发的流量和压力,我们需要创建多个应用的副本,还要即时监控它们的状态。如果还是只使用Pod,那就会又走回手工管理的老路,没有利用好Kubernetes自动化运维的优势。
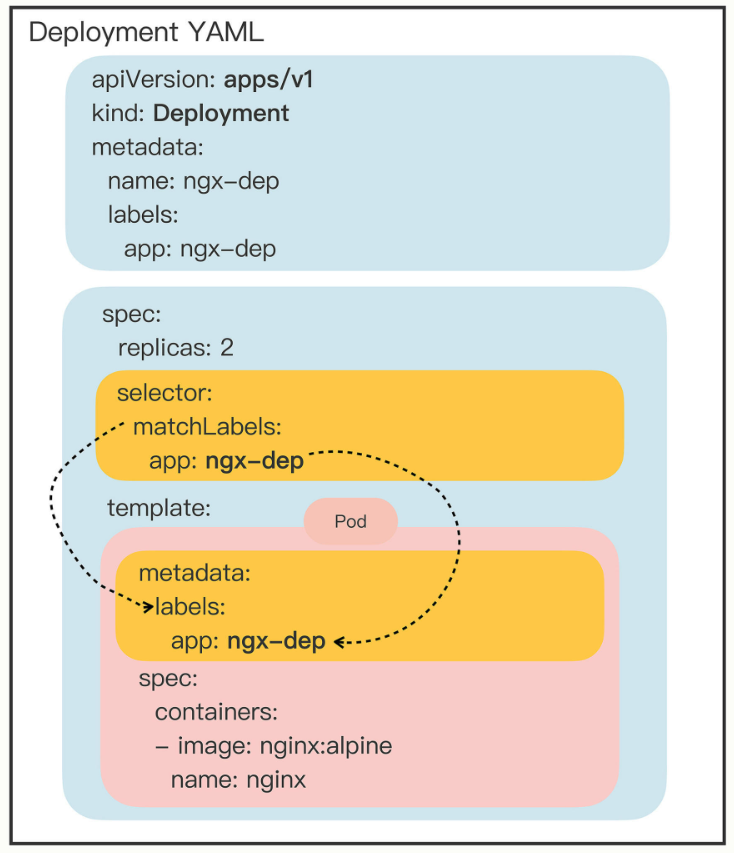
Deployment,就是用来管理Pod,实现在线业务应用的新API对象。
replicas 字段。它的含义比较简单明了,就是“副本数量”的意思,也就是说,指定要在Kubernetes集群里运行多少个Pod实例。
接下来Kubernetes还会持续地监控Pod的运行状态,万一有Pod发生意外消失了,数量不满足“期望状态”,它就会通过apiserver、scheduler等核心组件去选择新的节点,创建出新的Pod,直至数量与“期望状态”一致。
selector,它的作用是“筛选”出要被Deployment管理的Pod对象,下属字段“matchLabels”定义了Pod对象应该携带的label,它必须和“template”里Pod定义的“labels”完全相同,否则Deployment就会找不到要控制的Pod对象,apiserver也会告诉你YAML格式校验错误无法创建。
Kubernetes采用的是这种“贴标签”的方式,通过在API对象的“metadata”元信息里加各种标签(labels),我们就可以使用类似关系数据库里查询语句的方式,筛选出具有特定标识的那些对象。通过标签这种设计,Kubernetes就解除了Deployment和模板里Pod的强绑定,把组合关系变成了“弱引用”。
在Deployment部署成功之后,你还可以随时调整Pod的数量,实现所谓的“应用伸缩”。这项工作在Kubernetes出现之前对于运维来说是一件很困难的事情,而现在由于有了Deployment就变得轻而易举了。
DaemonSet:节点的守护者
Deployment并不关心这些Pod会在集群的哪些节点上运行,在它看来,Pod的运行环境与功能是无关的,只要Pod的数量足够,应用程序应该会正常工作。
这个假设对于大多数业务来说是没问题的,比如Nginx、WordPress、MySQL,它们不需要知道集群、节点的细节信息,只要配置好环境变量和存储卷,在哪里“跑”都是一样的。
但是有一些业务比较特殊,它们不是完全独立于系统运行的,而是与主机存在“绑定”关系,必须要依附于节点才能产生价值,比如说:
- 网络应用(如kube-proxy),必须每个节点都运行一个Pod,否则节点就无法加入Kubernetes网络。
- 监控应用(如Prometheus),必须每个节点都有一个Pod用来监控节点的状态,实时上报信息。
- 日志应用(如Fluentd),必须在每个节点上运行一个Pod,才能够搜集容器运行时产生的日志数据。
- 安全应用,同样的,每个节点都要有一个Pod来执行安全审计、入侵检查、漏洞扫描等工作。
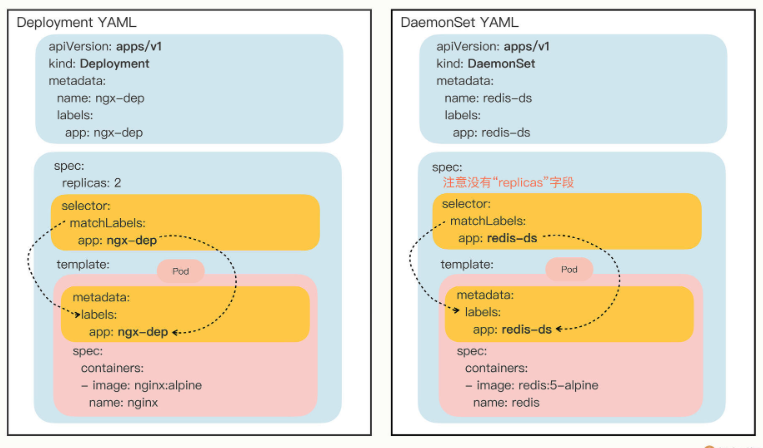
所以,Kubernetes就定义了新的API对象DaemonSet,它在形式上和Deployment类似,都是管理控制Pod,但管理调度策略却不同。DaemonSet的目标是在集群的每个节点上运行且仅运行一个Pod,就好像是为节点配上一只“看门狗”,忠实地“守护”着节点,这就是DaemonSet名字的由来。
DaemonSet仅仅是在Pod的部署调度策略上和Deployment不同,其他的都是相同的,某种程度上我们也可以把DaemonSet看做是Deployment的一个特例。
我还是把YAML描述文件画了一张图,好让你看清楚与Deployment的差异:
配置管理
首先你要知道,应用程序有很多类别的配置信息,但从数据安全的角度来看可以分成两类:
- 一类是明文配置,也就是不保密,可以任意查询修改,比如服务端口、运行参数、文件路径等等。
- 另一类则是机密配置,由于涉及敏感信息需要保密,不能随便查看,比如密码、密钥、证书等等。
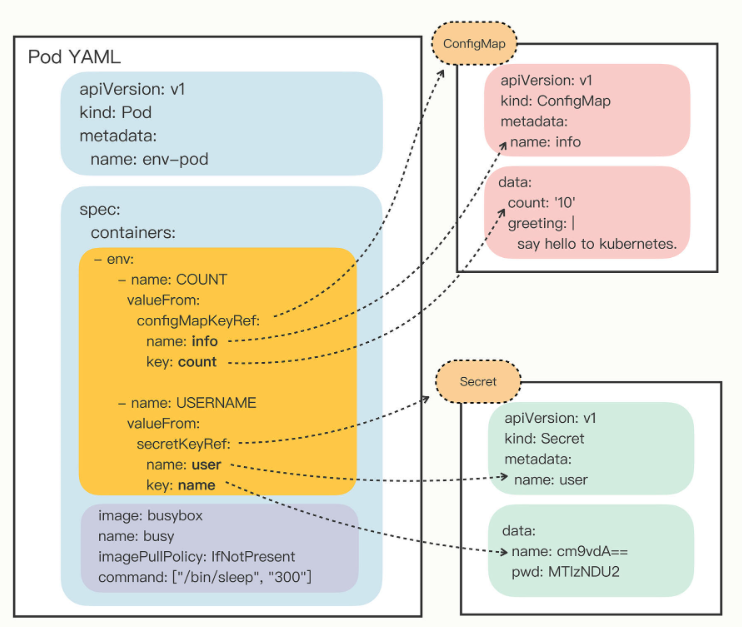
这两类配置信息本质上都是字符串,只是由于安全性的原因,在存放和使用方面有些差异,所以Kubernetes也就定义了两个API对象,ConfigMap用来保存明文配置,Secret用来保存秘密配置。
因为ConfigMap和Secret只是一些存储在etcd里的字符串,所以如果想要在运行时产生效果,就必须要以某种方式“注入”到Pod里,让应用去读取。在这方面的处理上Kubernetes和Docker是一样的,也是两种途径:环境变量和加载文件。
环境变量注入
从这张图你就应该能够比较清楚地看出Pod与ConfigMap、Secret的“松耦合”关系,它们不是直接嵌套包含,而是使用“KeyRef”字段间接引用对象,这样,同一段配置信息就可以在不同的对象之间共享。
文件加载注入
Kubernetes为Pod定义了一个“Volume”的概念,可以翻译成是“存储卷”。如果把Pod理解成是一个虚拟机,那么Volume就相当于是虚拟机里的磁盘。
我们可以为Pod“挂载(mount)”多个Volume,里面存放供Pod访问的数据,这种方式有点类似 docker run -v,虽然用法复杂了一些,但功能也相应强大一些。
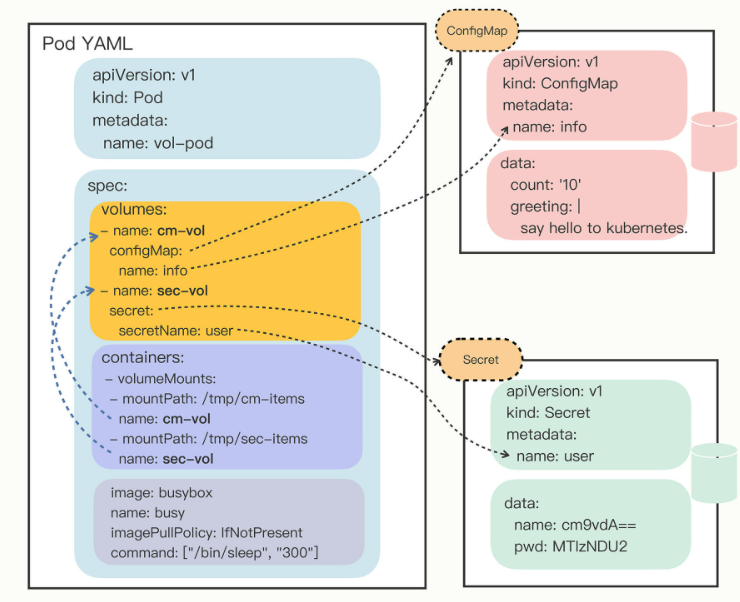
挂载Volume的方式和环境变量又不太相同。环境变量是直接引用了ConfigMap/Secret,而Volume又多加了一个环节,需要先用Volume引用ConfigMap/Secret,然后在容器里挂载Volume。
这种方式的好处在于:以Volume的概念统一抽象了所有的存储,不仅现在支持ConfigMap/Secret,以后还能够支持临时卷、持久卷、动态卷、快照卷等许多形式的存储,扩展性非常好。
因为这种形式上的差异,以Volume的方式来使用ConfigMap/Secret,就和环境变量不太一样。环境变量用法简单,更适合存放简短的字符串,而Volume更适合存放大数据量的配置文件,在Pod里加载成文件后让应用直接读取使用。
Service:微服务架构的应对之道
在Kubernetes集群里Pod的生命周期是比较“短暂”的,虽然Deployment和DaemonSet可以维持Pod总体数量的稳定,但在运行过程中,难免会有Pod销毁又重建,这就会导致Pod集合处于动态的变化之中。
这种“动态稳定”对于现在流行的微服务架构来说是非常致命的,试想一下,后台Pod的IP地址老是变来变去,客户端该怎么访问呢?如果不处理好这个问题,Deployment和DaemonSet把Pod管理得再完善也是没有价值的。
其实,这个问题也并不是什么难事,业内早就有解决方案来针对这样“不稳定”的后端服务,那就是“负载均衡”,典型的应用有LVS、Nginx等等。它们在前端与后端之间加入了一个“中间层”,屏蔽后端的变化,为前端提供一个稳定的服务。
但LVS、Nginx毕竟不是云原生技术,所以Kubernetes就按照这个思路,定义了新的API对象:Service。
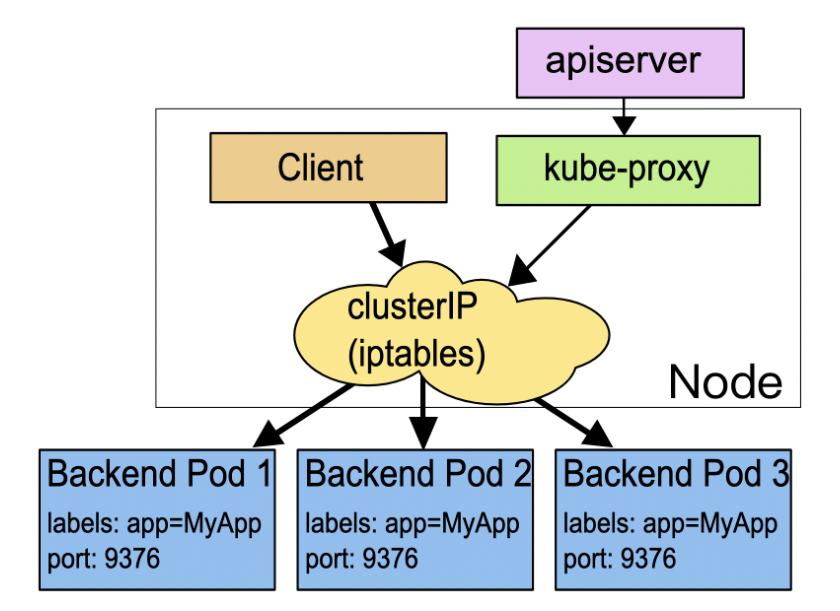
Kubernetes会给Service分配一个静态IP地址,然后它再去自动管理、维护后面动态变化的Pod集合,当客户端访问Service,它就根据某种策略,把流量转发给后面的某个Pod。
selector 和Deployment/DaemonSet里的作用是一样的,用来过滤出要代理的那些Pod。因为我们指定要代理Deployment,所以Kubernetes就为我们自动填上了ngx-dep的标签,会选择这个Deployment对象部署的所有Pod。
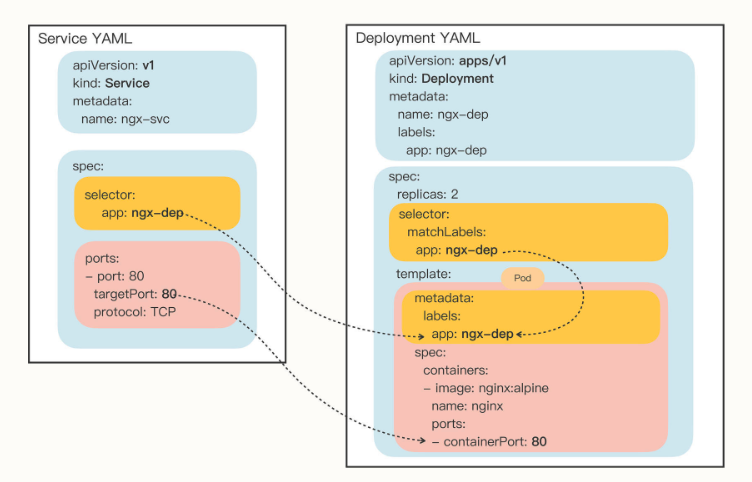
Pod被Deployment对象管理,删除后会自动重建,而Service又会通过controller-manager实时监控Pod的变化情况,所以就会立即更新它代理的IP地址。
namespace
Kubernetes有一个默认的名字空间,叫“default”,如果不显式指定,API对象都会在这个“default”名字空间里。而其他的名字空间都有各自的用途,比如“kube-system”就包含了apiserver、etcd等核心组件的Pod。
通常我们会使用namespce区分线上环境。
Service对象的域名完全形式是“对象.名字空间.svc.cluster.local”,但很多时候也可以省略后面的部分,直接写“对象.名字空间”甚至“对象名”就足够了,默认会使用对象所在的名字空间(比如这里就是default)。
我们不再关心Service对象的IP地址,只需要知道它的名字,就可以用DNS的方式去访问后端服务。
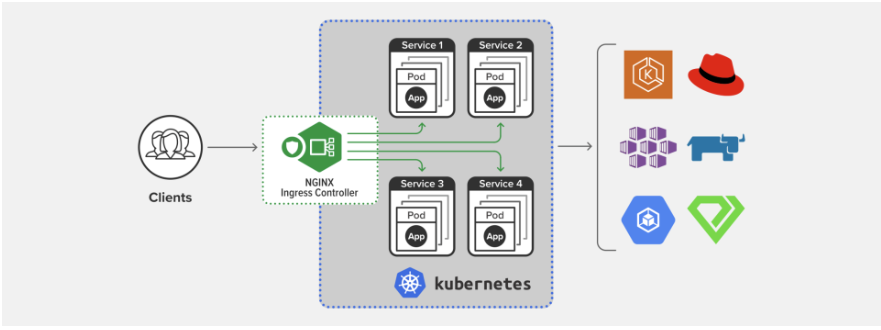
Ingress:集群进出流量的总管
Ingress的意思是集群内外边界上的入口,它作为流量的总入口,统管集群的进出口数据,“扇入”“扇出”流量(也就是我们常说的“南北向”),让外部用户能够安全、顺畅、便捷地访问内部服务。
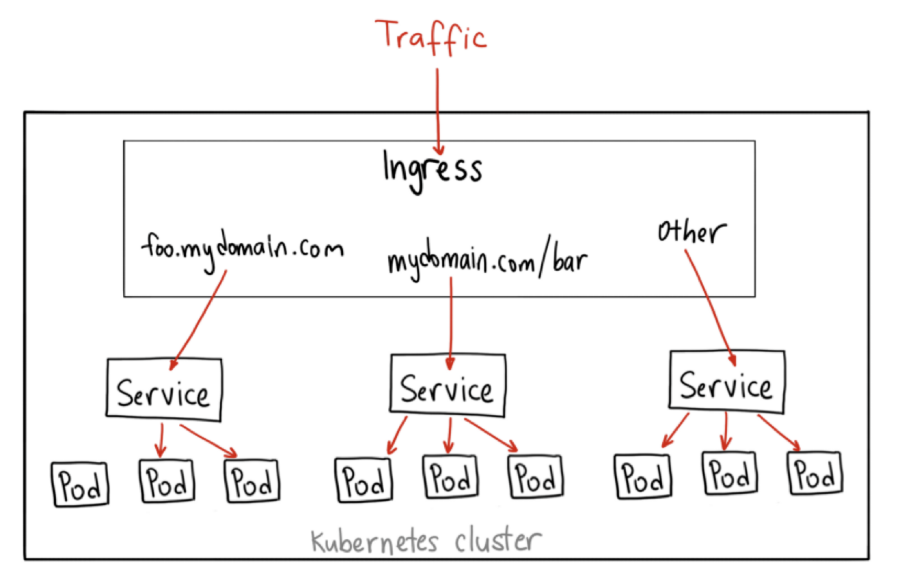
再对比一下Service我们就能更透彻地理解Ingress。
Ingress可以说是在七层上另一种形式的Service,它同样会代理一些后端的Pod,也有一些路由规则来定义流量应该如何分配、转发,只不过这些规则都使用的是HTTP/HTTPS协议。
你应该知道,Service本身是没有服务能力的,它只是一些iptables规则,真正配置、应用这些规则的实际上是节点里的kube-proxy组件。如果没有kube-proxy,Service定义得再完善也没有用。
同样的,Ingress也只是一些HTTP路由规则的集合,相当于一份静态的描述文件,真正要把这些规则在集群里实施运行,还需要有另外一个东西,这就是 Ingress Controller,它的作用就相当于Service的kube-proxy,能够读取、应用Ingress规则,处理、调度流量。
理来说,Kubernetes应该把Ingress Controller内置实现,作为基础设施的一部分,就像kube-proxy一样。
不过Ingress Controller要做的事情太多,与上层业务联系太密切,所以Kubernetes把Ingress Controller的实现交给了社区,任何人都可以开发Ingress Controller,只要遵守Ingress规则就好。
这就造成了Ingress Controller“百花齐放”的盛况。
由于Ingress Controller把守了集群流量的关键入口,掌握了它就拥有了控制集群应用的“话语权”,所以众多公司纷纷入场,精心打造自己的Ingress Controller,意图在Kubernetes流量进出管理这个领域占有一席之地。
这些实现中最著名的,就是老牌的反向代理和负载均衡软件Nginx了。从Ingress Controller的描述上我们也可以看到,HTTP层面的流量管理、安全控制等功能其实就是经典的反向代理,而Nginx则是其中稳定性最好、性能最高的产品,所以它也理所当然成为了Kubernetes里应用得最广泛的Ingress Controller。
根据Docker Hub上的统计,Nginx公司的开发实现是下载量最多的Ingress Controller,所以我将以它为例,讲解Ingress和Ingress Controller的用法。
IngressClass
那么到现在,有了Ingress和Ingress Controller,我们是不是就可以完美地管理集群的进出流量了呢?
最初Kubernetes也是这么想的,一个集群里有一个Ingress Controller,再给它配上许多不同的Ingress规则,应该就可以解决请求的路由和分发问题了。
但随着Ingress在实践中的大量应用,很多用户发现这种用法会带来一些问题,比如:
- 由于某些原因,项目组需要引入不同的Ingress Controller,但Kubernetes不允许这样做;
- Ingress规则太多,都交给一个Ingress Controller处理会让它不堪重负;
- 多个Ingress对象没有很好的逻辑分组方式,管理和维护成本很高;
- 集群里有不同的租户,他们对Ingress的需求差异很大甚至有冲突,无法部署在同一个Ingress Controller上。
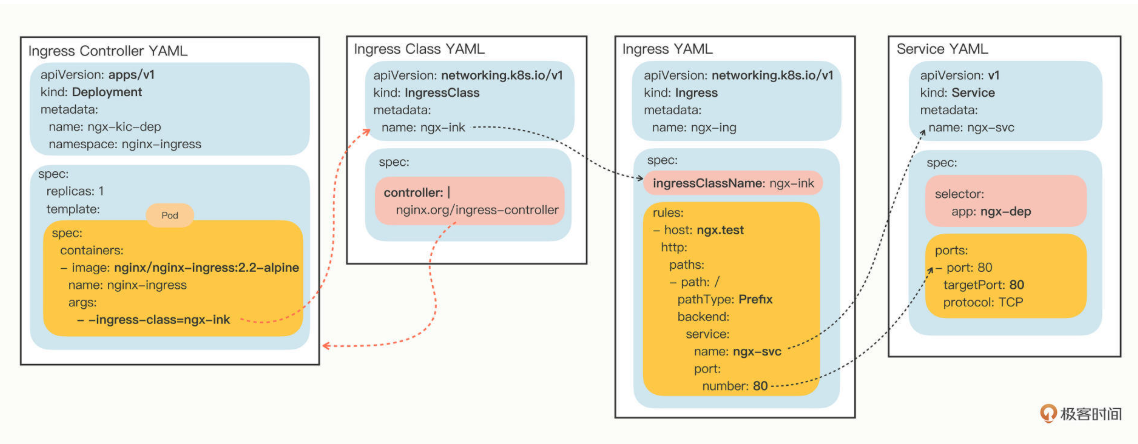
所以,Kubernetes就又提出了一个 Ingress Class 的概念,让它插在Ingress和Ingress Controller中间,作为流量规则和控制器的协调人,解除了Ingress和Ingress Controller的强绑定关系。
现在,Kubernetes用户可以转向管理Ingress Class,用它来定义不同的业务逻辑分组,简化Ingress规则的复杂度。比如说,我们可以用Class A处理博客流量、Class B处理短视频流量、Class C处理购物流量。
有了Ingress Controller,这些API对象的关联就更复杂了,你可以用下面的这张图来看出它们是如何使用对象名字联系起来的:
PersistentVolume:数据持久化
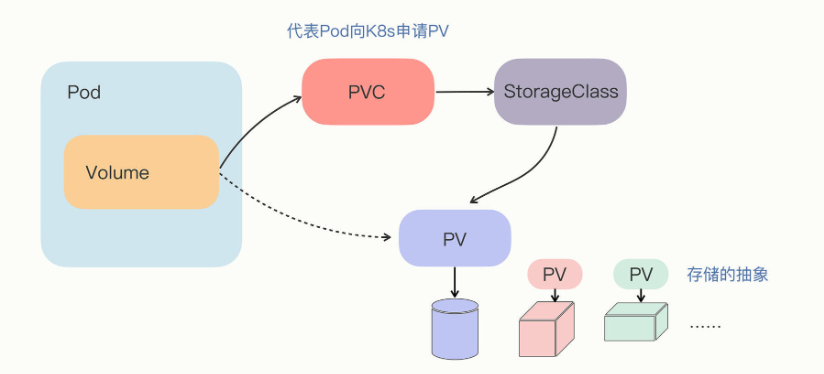
前面说到,pod是kubernetes中运行的最小单位,但是其中存在一个很严重的问题:Pod没有持久化功能,因为Pod里的容器是由镜像产生的,而镜像文件本身是只读的,进程要读写磁盘只能用一个临时的存储空间,一旦Pod销毁,临时存储也就会立即回收释放,数据也就丢失了。
为了保证即使Pod销毁后重建数据依然存在,我们就需要找出一个解决方案,让Pod用上真正的“虚拟盘”。Kubernetes延伸出了PersistentVolume对象,它专门用来表示持久存储设备。作为存储的抽象,PV实际上就是一些存储设备、文件系统,比如Ceph、GlusterFS、NFS,甚至是本地磁盘,管理它们已经超出了Kubernetes的能力范围,所以,一般会由系统管理员单独维护,然后再在Kubernetes里创建对应的PV。
要注意的是,PV属于集群的系统资源,是和Node平级的一种对象,Pod对它没有管理权,只有使用权。
PersistentVolumeClaim
PersistentVolumeClaim,简称PVC,从名字上看比较好理解,就是用来向Kubernetes申请存储资源的。PVC是给Pod使用的对象,它相当于是Pod的代理,代表Pod向系统申请PV。一旦资源申请成功,Kubernetes就会把PV和PVC关联在一起,这个动作叫做“绑定”(bind)。
但是,系统里的存储资源非常多,如果要PVC去直接遍历查找合适的PV也很麻烦,所以就要用到StorageClass。
StorageClass
StorageClass抽象了特定类型的存储系统(比如Ceph、NFS),在PVC和PV之间充当“协调人”的角色,帮助PVC找到合适的PV。也就是说它可以简化Pod挂载“虚拟盘”的过程,让Pod看不到PV的实现细节。
StatefulSet:管理有状态的应用
用Deployment来保证高可用,用PersistentVolume来存储数据,确实可以部分达到管理“有状态应用”的目的。但“状态”不仅仅是数据持久化,在集群化、分布式的场景里,还有多实例的依赖关系、启动顺序和网络标识等问题需要解决,而这些问题恰恰是Deployment力所不及的。
因为只使用Deployment,多个实例之间是无关的,启动的顺序不固定,Pod的名字、IP地址、域名也都是完全随机的,这正是“无状态应用”的特点。
但对于“有状态应用”,多个实例之间可能存在依赖关系,比如master/slave、active/passive,需要依次启动才能保证应用正常运行,外界的客户端也可能要使用固定的网络标识来访问实例,而且这些信息还必须要保证在Pod重启后不变。
所以,Kubernetes就在Deployment的基础之上定义了一个新的API对象,名字也很好理解,就叫StatefulSet,专门用来管理有状态的应用。
前面提到,Service自己会有一个域名,格式是“对象名.名字空间”,每个Pod也会有一个域名,形式是“IP地址.名字空间”。但因为IP地址不稳定,所以Pod的域名并不实用,一般我们会使用稳定的Service域名。
当我们把Service对象应用于StatefulSet的时候,情况就不一样了。
Service发现这些Pod不是一般的应用,而是有状态应用,需要有稳定的网络标识,所以就会为Pod再多创建出一个新的域名,格式是“Pod名.服务名.名字空间.svc.cluster.local”。当然,这个域名也可以简写成“Pod名.服务名”。
显然,在StatefulSet里的这两个Pod都有了各自的域名,也就是稳定的网络标识。那么接下来,外部的客户端只要知道了StatefulSet对象,就可以用固定的编号去访问某个具体的实例了,虽然Pod的IP地址可能会变,但这个有编号的域名由Service对象维护,是稳定不变的。
StatefulSet的数据持久化
现在StatefulSet已经有了固定的名字、启动顺序和网络标识,只要再给它加上数据持久化功能,我们就可以实现对“有状态应用”的管理了。
不过,为了强调持久化存储与StatefulSet的一对一绑定关系,Kubernetes为StatefulSet专门定义了一个字段“volumeClaimTemplates”,直接把PVC定义嵌入StatefulSet的YAML文件里。这样能保证创建StatefulSet的同时,就会为每个Pod自动创建PVC,让StatefulSet的可用性更高。
滚动更新:平滑的应用升降级
应用升级
在Kubernetes里,版本更新使用的不是API对象,而是两个命令:kubectl apply 和 kubectl rollout,当然它们也要搭配部署应用所需要的Deployment、DaemonSet等YAML文件。
Kubernetes里应用都是以Pod的形式运行的,而Pod通常又会被Deployment等对象来管理,所以应用的“版本更新”实际上更新的是整个Pod。
Pod是由YAML描述文件来确定的,更准确地说,是Deployment等对象里的字段 template。所以,在Kubernetes里应用的版本变化就是 template 里Pod的变化,哪怕 template 里只变动了一个字段,那也会形成一个新的版本,也算是版本变化。
Kubernetes不是把旧Pod全部销毁再一次性创建出新Pod,而是在逐个地创建新Pod,同时也在销毁旧Pod,保证系统里始终有足够数量的Pod在运行,不会有“空窗期”中断服务。
新Pod数量增加的过程有点像是“滚雪球”,从零开始,越滚越大,所以这就是所谓的“滚动更新”(rolling update)。
其实“滚动更新”就是由Deployment控制的两个同步进行的“应用伸缩”操作,老版本缩容到0,同时新版本扩容到指定值,是一个“此消彼长”的过程。
生产环境中就有关于应用无感发布的例子,只要开启了健康检测,且3次不通过,启动检测和存活检测不通过会将 pod 重启,就绪检测不通过会把 pod 从 svc EndPoint 列表列表中删除,请求不会打到此 pod 上。如果生产上 pod 出现了某些异常,会创建一个新的 pod,等到新的pod健康检测完成以后,才会把旧 pod 从 endpoint 列表中移出,新 pod 加入,此时旧 pod 已经不会接收到新请求了,旧 pod 会把一些没有完成的请求正常响应,响应完才会销毁掉,terminationGracePeriodSecond 这个参数配置表明 Pod 在收到终止信号后,允许其正常关闭的最大宽限时间,在这段时间内可以处理剩余请求。
应用回滚
对于更新后出现的问题,Kubernetes为我们提供了“后悔药”,也就是更新历史,你可以查看之前的每次更新记录,并且回退到任何位置,和我们开发常用的Git等版本控制软件非常类似。
如果想要回退到上一个版本,就可以使用命令 kubectl rollout undo,也可以加上参数 --to-revision 回退到任意一个历史版本。kubectWl rollout undo 的操作过程其实和 kubectl apply 是一样的,执行的仍然是“滚动更新”,只不过使用的是旧版本Pod模板,把新版本Pod数量收缩到0,同时把老版本Pod扩展到指定值。
应用保障:如何让Pod运行得更健康?
容器资源配额
创建容器有三大隔离技术:namespace、cgroup、chroot。其中的namespace实现了独立的进程空间,cgroup的作用是管控CPU、内存,保证容器不会无节制地占用基础资源,进而影响到系统里的其他应用,chroot实现了独立的文件系统。
与PersistentVolumeClaim用法有些类似,就是容器需要先提出一个“书面申请”,Kubernetes再依据这个“申请”决定资源是否分配和如何分配。使用 resources 字段加上资源配额之后,Pod在Kubernetes里的运行就有了初步保障,Kubernetes会监控Pod的资源使用情况,让它既不会“饿死”也不会“撑死”。
Kubernetes会根据每个Pod声明的需求,像搭积木或者玩俄罗斯方块一样,把节点尽量“塞满”,充分利用每个节点的资源,让集群的效益最大化。
容器状态探针
一个程序即使正常启动了,它也有可能因为某些原因无法对外提供服务。其中最常见的情况就是运行时发生“死锁”或者“死循环”的故障,这个时候从外部来看进程一切都是正常的,但内部已经是一团糟了。
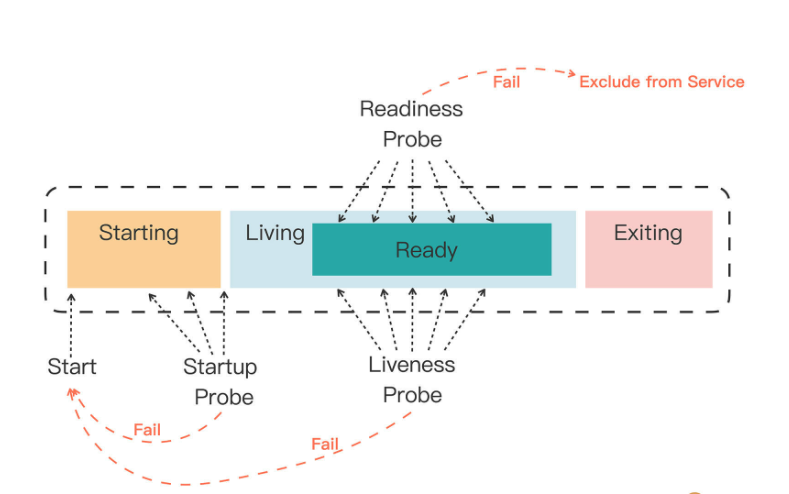
Kubernetes为检查应用状态定义了三种探针,它们分别对应容器不同的状态:
- Startup,启动探针,用来检查应用是否已经启动成功,适合那些有大量初始化工作要做,启动很慢的应用。
- Liveness,存活探针,用来检查应用是否正常运行,是否存在死锁、死循环。
- Readiness,就绪探针,用来检查应用是否可以接收流量,是否能够对外提供服务。
你需要注意这三种探针是递进的关系:应用程序先启动,加载完配置文件等基本的初始化数据就进入了Startup状态,之后如果没有什么异常就是Liveness存活状态,但可能有一些准备工作没有完成,还不一定能对外提供服务,只有到最后的Readiness状态才是一个容器最健康可用的状态。
那Kubernetes具体是如何使用状态和探针来管理容器的呢?
如果一个Pod里的容器配置了探针,Kubernetes在启动容器后就会不断地调用探针来检查容器的状态:
- 如果Startup探针失败,Kubernetes会认为容器没有正常启动,就会尝试反复重启,当然其后面的Liveness探针和Readiness探针也不会启动。
- 如果Liveness探针失败,Kubernetes就会认为容器发生了异常,也会重启容器。
- 如果Readiness探针失败,Kubernetes会认为容器虽然在运行,但内部有错误,不能正常提供服务,就会把容器从Service对象的负载均衡集合中排除,不会给它分配流量。
集群管理:如何用名字空间分隔系统资源?
Kubernetes的名字空间并不是一个实体对象,只是一个逻辑上的概念。它可以把集群切分成一个个彼此独立的区域,然后我们把对象放到这些区域里,就实现了类似容器技术里namespace的隔离效果,应用只能在自己的名字空间里分配资源和运行,不会干扰到其他名字空间里的应用。
资源配额
有了名字空间,我们就可以像管理容器一样,给名字空间设定配额,把整个集群的计算资源分割成不同的大小,按需分配给团队或项目使用。
不过集群和单机不一样,除了限制最基本的CPU和内存,还必须限制各种对象的数量,否则对象之间也会互相挤占资源。
默认资源配额
学到这里估计你也发现了,在名字空间加上了资源配额限制之后,它会有一个合理但比较“烦人”的约束:要求所有在里面运行的Pod都必须用字段 resources 声明资源需求,否则就无法创建。
Kubernetes这样做的原因也很好理解,如果Pod里没有 resources 字段,就可以无限制地使用CPU和内存,这显然与名字空间的资源配额相冲突。为了保证名字空间的资源总量可管可控,Kubernetes就只能拒绝创建这样的Pod了。
那么能不能让Kubernetes自动为Pod加上资源限制呢?也就是说给个默认值,这样就可以省去反复设置配额的烦心事。
这个时候就要用到一个很小但很有用的辅助对象了—— LimitRange,简称是 limits,它能为API对象添加默认的资源配额限制。
系统监控:如何使用Metrics Server和Prometheus?
希望给集群也安装上“检查探针”,观察到集群的资源利用率和其他指标,让集群的整体运行状况对我们“透明可见”,这样才能更准确更方便地做好集群的运维工作。
Metrics Server
Metrics Server是一个专门用来收集Kubernetes核心资源指标(metrics)的工具,它定时从所有节点的kubelet里采集信息,但是对集群的整体性能影响极小,每个节点只大约会占用1m的CPU和2MB的内存,所以性价比非常高。
它调用kubelet的API拿到节点和Pod的指标,再把这些信息交给apiserver,这样kubectl、HPA就可以利用apiserver来读取指标了:
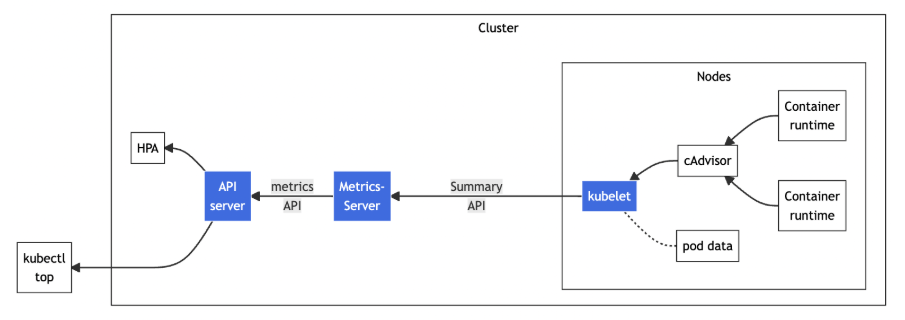
HorizontalPodAutoscaler
有了Metrics Server,我们就可以轻松地查看集群的资源使用状况了,不过它另外一个更重要的功能是辅助实现应用的“水平自动伸缩”。
“HorizontalPodAutoscaler”,简称是“hpa”。顾名思义,它是专门用来自动伸缩Pod数量的对象,适用于Deployment和StatefulSet,但不能用于DaemonSet。
HorizontalPodAutoscaler的能力完全基于Metrics Server,它从Metrics Server获取当前应用的运行指标,主要是CPU使用率,再依据预定的策略增加或者减少Pod的数量。
因为Metrics Server大约每15秒采集一次数据,所以HorizontalPodAutoscaler的自动化扩容和缩容也是按照这个时间点来逐步处理的。
当它发现目标的CPU使用率超过了预定的5%后,就会以2的倍数开始扩容,一直到数量上限,然后持续监控一段时间,如果CPU使用率回落,就会再缩容到最小值。
Prometheus
显然,有了Metrics Server和HorizontalPodAutoscaler的帮助,我们的应用管理工作又轻松了一些。不过,Metrics Server能够获取的指标还是太少了,只有CPU和内存,想要监控到更多更全面的应用运行状况,还得请出这方面的权威项目“Prometheus”。
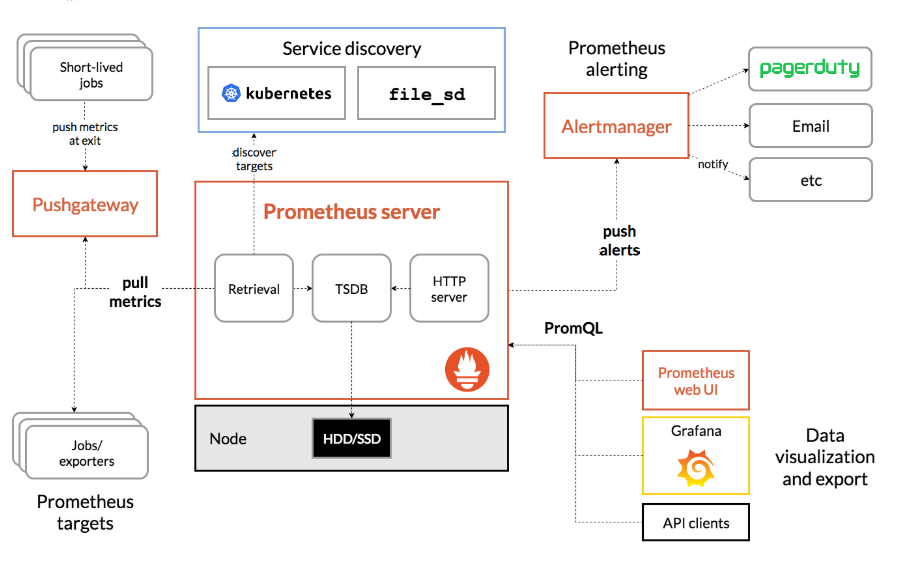
Prometheus系统的核心是它的Server,里面有一个时序数据库TSDB,用来存储监控数据,另一个组件Retrieval使用拉取(Pull)的方式从各个目标收集数据,再通过HTTP Server把这些数据交给外界使用。
在Prometheus Server之外还有三个重要的组件:
- Push Gateway,用来适配一些特殊的监控目标,把默认的Pull模式转变为Push模式,让业务程序能够推送数据,再由收集系统来收集。
- Alert Manager,告警中心,预先设定规则,发现问题时就通过邮件等方式告警。
- Grafana是图形化界面,可以定制大量直观的监控仪表盘。
网络通信
Kubernetes提出了一个自己的网络模型“IP-per-pod”,能够很好地适应集群系统的网络需求,它有下面的这4点基本假设:
- 集群里的每个Pod都会有唯一的一个IP地址。
- Pod里的所有容器共享这个IP地址。
- 集群里的所有Pod都属于同一个网段。
- Pod直接可以基于IP地址直接访问另一个Pod,不需要做麻烦的网络地址转换(NAT)。
内部k8s亲和性配置规范说明
注意运行中的节点。谨慎添加
NoExecute属性污点标签,否则会导致节点中服务被驱逐。造成生产事故
节点资源类型目前分四种
- 非核心组 8核32G 标签:
jr.k8s.node/group:non-core - 核心组 16核64G 标签:
jr.k8s.node/group:core,污点标签:jr.k8s.node/group:task:core - 任务组 8核64G 标签:
jr.k8s.node/group:task,污点标签:jr.k8s.node/group:task:NoExecute(待实现云托管,取消该标签) - 专属节点 8核32G 标签:
jr.k8s.service.node/group:系统简称,污点标签:jr.k8s.service.node/group=系统简称:NoExecute(另外需要添加是否为核心组标签,以满足后期区节点类别统计)
节点标签:用来保障亲和性配置标签,使拥有相同标签的服务pod优先部署在本节点上
污点标签:节点部署pod容忍度配置,未配置匹配容忍度将不允许被部署到该节点,并被驱逐。
注意
专属节点与核心节点:最少两个相同节点,防止节点故障(用于特殊情况指定防止影响其它系统)
除非核心组节点外,其它类型节点必须包含污点标签,避免其他服务注册至节点上。
污点标签:如果给一个节点添加了一个 effect 值为 NoExecute 的污点, 则任何不能忍受这个污点的 Pod 都会马上被驱逐
非核心服务亲和性配置
1 | apiVersion: apps/v1 |
核心服务亲和性配置
1 | apiVersion: apps/v1 |
任务/导出型服务亲和性配置
1 | apiVersion: apps/v1 |
专属节点服务亲和性配置
1 | apiVersion: apps/v1 |
扩展
K8S的调度策略有哪些?能否让K8S按照我们的期望来进行资源调度?
| 特性 | 作用 | 适用场景 |
|---|---|---|
| 节点选择器 | 简单标签匹配 | 简单的环境区分,如 env=prod |
| 节点亲和性 | 复杂的节点标签匹配规则 | 硬件类型、可用区、自定义架构要求 |
| Pod 亲和性 | 让 Pod 靠近其他 Pod | 微服务间需要低延迟通信 |
| Pod 反亲和性 | 让 Pod 远离其他 Pod | 高可用、避免资源竞争、故障隔离 |
| 污点和容忍度 | 让节点排斥 Pod | 专用节点、故障隔离、基于节点的特权 |
K8S是怎么进行域名解析的?为什么通过创建的service名称进行接口调用可以转发至pod服务?
K8S 集群内置了一个 DNS 服务,通常是 CoreDNS(早期版本是 kube-dns)。这个 DNS 服务作为集群的”电话簿”,为各种资源提供名称解析。
步骤 1:Service 的创建与 Endpoint 的维护
当你创建一个 Service(比如叫 my-service)时,K8S 会做两件事:
- 定义一个网络端点:Service 会被分配一个虚拟的 IP 地址,称为 Cluster IP。这个 IP 在集群内部是可达的,但它是一个虚拟 IP,不像普通 IP 地址那样绑定在某张网卡上。
- 创建并维护 Endpoint/EndpointSlice 对象:K8S 会自动根据 Service 的 Label Selector,持续地查找集群中所有匹配的 Pod。然后,它将这些 Pod 的
IP:Port列表存储在一个名为 Endpoint 或 EndpointSlice 的对象中。你可以把它看作是 Service 背后真实服务器的地址列表。
步骤 2:DNS 服务的注册
CoreDNS 会监听 K8S API Server,当有新的 Service 被创建时,CoreDNS 会自动将其域名(my-service.default.svc.cluster.local)和 Cluster IP 地址记录到它的 DNS 记录中。
步骤 3:Pod 内的请求发起与解析
现在,当一个 Pod(我们称之为 client-pod)想要调用 my-service 服务时:
- 你在
client-pod的代码里使用了一个 URL,例如http://my-service:8080/api。 - 操作系统会发起一个 DNS 查询,请求解析
my-service。 - 由于 Pod 的
/etc/resolv.conf文件被 K8S 自动配置,它会指向集群的 CoreDNS 服务地址。 - DNS 查询请求被发送到 CoreDNS。
- CoreDNS 查找自己的记录,发现
my-service对应着 Cluster IP(例如10.96.1.2),于是将这个 IP 地址返回给client-pod。
步骤 4:流量转发与负载均衡
client-pod拿到 IP 地址10.96.1.2后,向这个地址发送网络请求。- 这个虚拟 IP 被 K8S 的网络插件(如 Calico, Flannel 等)和每个节点上的 kube-proxy 组件所感知。
- kube-proxy 在这个虚拟 IP 和真实 Pod IP 之间建立了转发规则(可能是 iptables 或 ipvs 规则)。
- 当请求到达
10.96.1.2时,这些网络规则会拦截该请求,并根据负载均衡策略(默认是轮询),将其转发到Endpoint列表中的某一个 Pod 的真实 IP 和端口上。
K8S如何做为配置中心并实现配置文件的热更新?
- 将 ConfigMap 或 Secret 作为一个卷(Volume)挂载到 Pod 的容器中。
- K8S 会在挂载的目录下创建对应的文件(如
/etc/config/redis-config.conf)。 - 当更新 ConfigMap(
kubectl apply -f updated-configmap.yaml)时,K8S 会自动将新内容投射到已挂载该卷的所有 Pod 中。 - 这个”投射”动作是异步的,但通常很快(几秒到几十秒)。
- 投射完成后,容器内看到的就是一个文件内容被更新的文件。


