
Redis实战:场景设计
Redis 热升级
对于线上较大流量的业务,单个 Redis 实例的内存占用很容易达到数 G 的容量,对应的 aof 会占用数十 G 的空间。即便每天流量低峰时间,对 Redis 进行 rewriteaof,减少数据冗余,但由于业务数据多,写操作多,aof 文件仍然会达到 10G 以上。
此时,在 Redis 需要升级版本或修复 bug 时,如果直接重启变更,由于需要数据恢复,这个过程需要近 10 分钟的时间,时间过长,会严重影响系统的可用性。
首先构建一个 Redis 壳程序,将 redisServer 的所有属性(包括redisDb、client等)保存为全局变量。然后将 Redis 的处理逻辑代码全部封装到动态连接库 so 文件中。Redis 第一次启动,从磁盘加载恢复数据,在后续升级时,通过指令,壳程序重新加载 Redis 新的 so 文件,即可完成功能升级,毫秒级完成 Redis 的版本升级。而且整个过程中,所有 Client 连接仍然保留,在升级成功后,原有 Client 可以继续进行读写操作,整个过程对业务完全透明。
Redis 功能扩展
在 Redis 使用中,也经常会遇到一些特殊业务场景,是当前 Redis 的数据结构无法很好满足的。此时可以对 Redis 进行定制化扩展。可以根据业务数据特点,扩展新的数据结构,甚至扩展新的 Redis 存储模型,来提升 Redis 的内存效率和处理性能。
在微博中,有个业务类型是关注列表。关注列表存储的是一个用户所有关注的用户 uid。关注列表可以用来验证关注关系,也可以用关注列表,进一步获取所有关注人的微博列表等。由于用户数量过于庞大,存储关注列表的 Redis 是作为一个缓存使用的,即不活跃的关注列表会很快被踢出 Redis。在再次需要这个用户的关注列表时,重新从 DB 加载,并写回 Redis。关注列表的元素全部 long,最初使用 set 存储,回种 set 时,使用 sadd 进行批量添加。线上发现,对于关注数比较多的关注列表,比如关注数有数千上万个用户,需要 sadd 上成千上万个 uid,即便分几次进行批量添加,每次也会消耗较多时间,数据回种效率较低,而且会导致 Redis 卡顿。另外,用 set 存关注列表,内存效率也比较低。
于是,我们对 Redis 扩展了 longset 数据结构。longset 本质上是一个 long 型的一维开放数组。可以采用 double-hash 进行寻址。
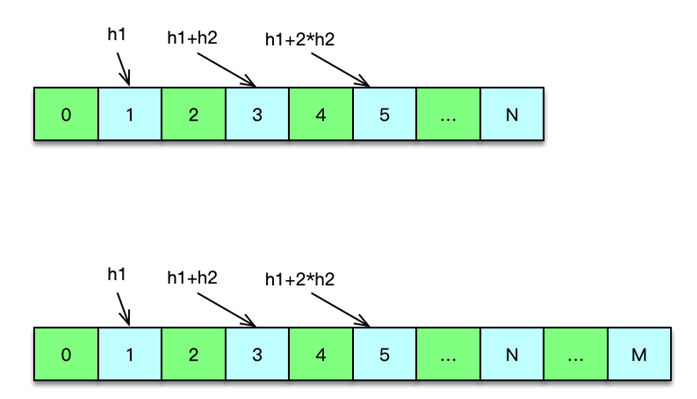
从 DB 加载到用户的关注列表,准备写入 Redis 前。Client 首先根据关注的 uid 列表,构建成 long 数组的二进制格式,然后通过扩展的 lsset 指令写入 Redis。
longset 中的 long 数组,采用 double-hash 进行寻址,即对每个 long 值采用 2 个哈希函数计算,然后按 (h1 + n*h2)% 数组长度 的方式,确定 long 值的位置。n 从 0 开始计算,如果出现哈希冲突,即计算的哈希位置,已经有其他元素,则 n 加 1,继续向前推进计算,最大计算次数是数组的长度。
在向 longset 数据结构不断增加 long 值元素的过程中,当数组的填充率超过阀值,Redis 则返回 longset 过满的异常。此时 Client 会根据最新全量数据,构建一个容量加倍的一维 long 数组,再次 lsset 回 Redis 中。
完全增量复制
微博整合 Redis 的 rdb 和 aof 策略,构建了完全增量复制方案。
在完全增量方案中,aof 文件不再只有一个,而是按后缀 id 进行递增,如 aof.00001、aof.00002,当 aof 文件超过阀值,则创建下一个 id 加 1 的文件,从而滚动存储最新的写指令。在 bgsave 构建 rdb 时,rdb 文件除了记录当前的内存数据快照,还会记录 rdb 构建时间,对应 aof 文件的 id 及位置。这样 rdb 文件和其记录 aof 文件位置之后的写指令,就构成一份完整的最新数据记录。
主从复制时,master 通过独立的复制线程向 slave 同步数据。每个 slave 会创建一个复制线程。第一次复制是全量复制,之后的复制,不管 slave 断开复制连接有多久,只要 aof 文件没有被删除,都是增量复制。
第一次全量复制时,复制线程首先将 rdb 发给 slave,然后再将 rdb 记录的 aof 文件位置之后的所有数据,也发送给 slave,即可完成。整个过程不用重新构建 rdb。
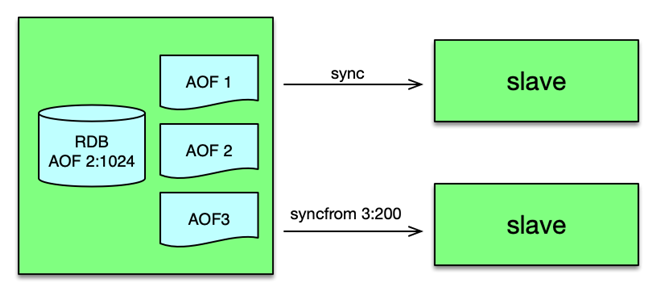
后续同步时,slave 首先传递之前复制的 aof 文件的 id 及位置。master 的复制线程根据这个信息,读取对应 aof 文件位置之后的所有内容,发送给 slave,即可完成数据同步。
由于整个复制过程,master 在独立复制线程中进行,所以复制过程不影响用户的正常请求。为了减轻 master 的复制压力,全增量复制方案仍然支持 slave 嵌套,即可以在 slave 后继续挂载多个 slave,从而把复制压力分散到多个不同的 Redis 实例。
如何为秒杀系统设计缓存体系
在设计秒杀系统时,有两个设计原则。
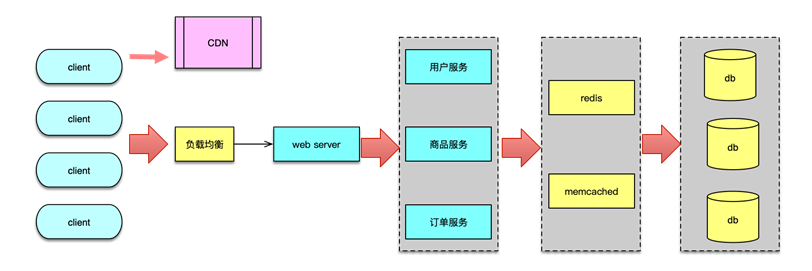
首先,要尽力将请求拦截在系统上游,层层设阻拦截,过滤掉无效或超量的请求。因为访问量远远大于商品数量,所有的请求打到后端服务的最后一步,其实并没有必要,反而会严重拖慢真正能成交的请求,降低用户体验。
其次,要充分利用缓存,提升系统的性能和可用性。
秒杀系统专为秒杀活动服务,售卖商品确定,因此可以在设计秒杀商品页面时,将商品信息提前设计为静态信息,将静态的商品信息以及常规的 CSS、JS、宣传图片等静态资源,一起独立存放到 CDN 节点,加速访问,且降低系统访问压力。
在访问前端也可以制定种种限制策略,比如活动没开始时,抢购按钮置灰,避免抢先访问,用户抢购一次后,也将按钮置灰,让用户排队等待,避免反复刷新。
用户所有的请求进入秒杀系统前,通过负载均衡策略均匀分发到不同 Web 服务器,避免节点过载。在 Web 服务器中,首先进行各种服务预处理,检查用户的访问权限,识别并发刷订单的行为。同时在真正服务前,也要进行服务前置检查,避免超售发生。如果发现售出数量已经达到秒杀数量,则直接返回结束。
秒杀系统在处理抢购业务逻辑时,除了对用户进行权限校验,还需要访问商品服务,对库存进行修改,访问订单服务进行订单创建,最后再进行支付、物流等后续服务。这些依赖服务,可以专门为秒杀业务设计排队策略,或者额外部署实例,对秒杀系统进行专门服务,避免影响其他常规业务系统。
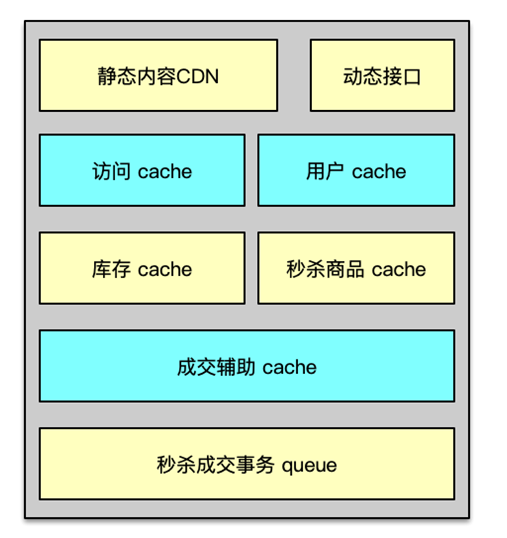
由于秒杀的参与者远大于商品数,为了提高抢购的概率,时常会出现一些利用脚本和僵尸账户并发频繁调用接口进行强刷的行为,秒杀系统需要构建访问记录缓存,记录访问 IP、用户的访问行为,发现异常访问,提前进行阻断及返回。同时还需要构建用户缓存,并针对历史数据分析,提前缓存僵尸强刷专业户,方便在秒杀期间对其进行策略限制。这些访问记录、用户数据,通过缓存进行存储,可以加速访问,另外,对用户数据还进行缓存预热,避免活动期间大量穿透。
在业务请求处理时,所有操作尽可能由缓存交互完成。由于秒杀商品较少,相关信息全部加载到内存,把缓存暂时当作存储用,并不会带来过大成本负担。
为秒杀商品构建商品信息缓存,并对全部目标商品进行预热加载。同时对秒杀商品构建独立的库存缓存,加速库存检测。这样通过秒杀商品列表缓存,进行快速商品信息查询,通过库存缓存,可以快速确定秒杀活动进程,方便高效成交或无可售商品后的快速检测及返回。在用户抢购到商品后,要进行库存事务变更,进行库存、订单、支付等相关的构建和修改,这些操作可以尽量由系统只与缓存组件交互完成初步处理。后续落地等操作,必须要入DB库的操作,可以先利用消息队列机,记录成交事件信息,然后再逐步分批执行,避免对 DB 造成过大压力。
总之,在秒杀系统中,除了常规的分拆访问内容和服务,最重要的是尽量将所有数据访问进行缓存化,尽量减少 DB 的访问,在大幅提升系统性能的同时,提升用户体验。
如何为海量计数场景设计缓存体系
计数常规方案
计数服务在互联网系统中非常常见,用户的关注粉丝数、帖子数、评论数等都需要进行计数存储。计数的存储格式也很简单,key 一般是用户 uid 或者帖子 id 加上后缀,value 一般是 8 字节的 long 型整数。
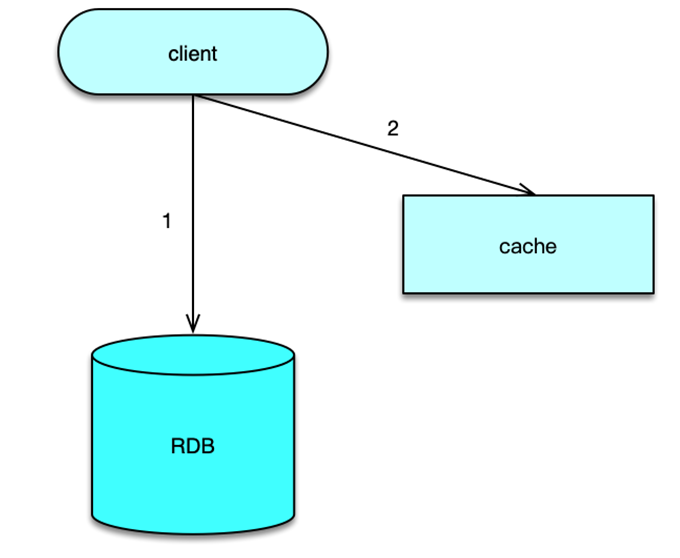
最常见的计数方案是采用缓存 + DB 的存储方案。当计数变更时,先变更计数 DB,计数加 1,然后再变更计数缓存,修改计数存储的 Memcached 或 Redis。这种方案比较通用且成熟,但在高并发访问场景,支持不够友好。在互联网社交系统中,有些业务的计数变更特别频繁,比如微博 feed 的阅读数,计数的变更次数和访问次数相当,每秒十万到百万级以上的更新量,如果用 DB 存储,会给 DB 带来巨大的压力,DB 就会成为整个计数服务的瓶颈所在。即便采用聚合延迟更新 DB 的方案,由于总量特别大,同时请求均衡分散在大量不同的业务端,巨大的写压力仍然是 DB 的不可承受之重。因此这种方案只适合中小规模的计数服务使用。
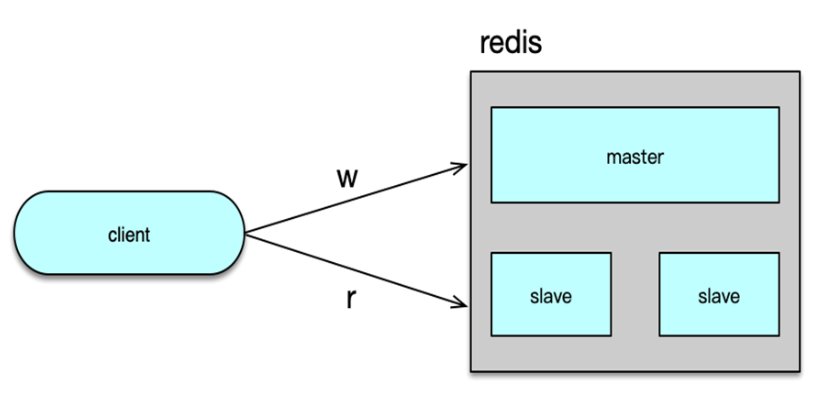
在 Redis 问世并越来越成熟后,很多互联网系统会直接把计数全部存储在 Redis 中。通过 hash 分拆的方式,可以大幅提升计数服务在 Redis 集群的写性能,通过主从复制,在 master 后挂载多个从库,利用读写分离,可以大幅提升计数服务在 Redis 集群的读性能。而且 Redis 有持久化机制,不会丢数据,在很多大中型互联网场景,这都是一个比较适合的计数服务方案。
在互联网移动社交领域,由于用户基数巨大,每日发表大量状态数据,且相互之间有大量的交互动作,从而产生了海量计数和超高并发访问,如果直接用 Redis 进行存储,会带来巨大的成本和性能问题。
海量计数场景
以微博为例,系统内有大量的待计数对象。如从用户维度,日活跃用户 2 亿+,月活跃用户接近 5 亿。从 Feed 维度,微博历史 Feed 有数千亿条,而且每日新增数亿条的新 Feed。这些用户和 Feed 不但需要进行计数,而且需要进行多个计数。比如,用户维度,每个用户需要记录关注数、粉丝数、发表 Feed 数等。而从 Feed 维度,每条 Feed 需要记录转发数、评论数、赞、阅读等计数。
而且,在微博业务场景下,每次请求都会请求多个对象的多个计数。比如查看用户时,除了获取该用户的基本信息,还需要同时获取用户的关注数、粉丝数、发表 Feed 数。获取微博列表时,除了获取 Feed 内容,还需要同时获取 Feed 的转发数、评论数、赞数,以及阅读数。因此,微博计数服务的总访问量特别大,很容易达到百万级以上的 QPS。
方案选择:
因此,在海量计数高并发访问场景,如果采用缓存 + DB 的架构,首先 DB 在计数更新就会存在瓶颈,其次,单个请求一次请求数十个计数,一旦缓存 miss,穿透到 DB,DB 的读也会成为瓶颈。因为 DB 能支撑的 TPS 不过 3000~6000 之间,远远无法满足高并发计数访问场景的需要。
采用 Redis 全量存储方案,通过分片和主从复制,读写性能不会成为主要问题,但容量成本却会带来巨大开销。
因为,一方面 Redis 作为通用型存储来存储计数,内存存储效率低。以存储一个 key 为 long 型 id、value 为 4 字节的计数为例,Redis 至少需要 65 个字节左右,不同版本略有差异。但这个计数理论只需要占用 12 个字节即可。内存有效负荷只有 12⁄65=18.5%。如果再考虑一个 long 型 id 需要存 4 个不同类型的 4 字节计数,内存有效负荷只有 (8+16)/(65*4)= 9.2%。
另一方面,Redis 所有数据均存在内存,单存储历史千亿级记录,单份数据拷贝需要 10T 以上,要考虑核心业务上 1 主 3 从,需要 40T 以上的内存,再考虑多 IDC 部署,轻松占用上百 T 内存。就按单机 100G 内存来算,计数服务就要占用上千台大内存服务器。存储成本太高。
海量计数服务架构
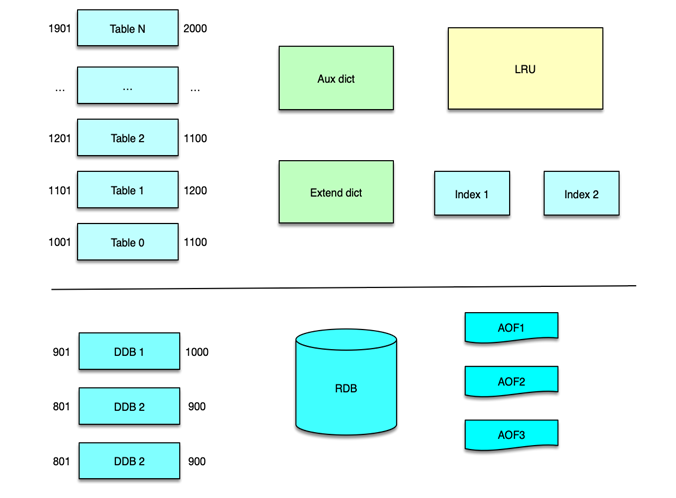
为了解决海量计数的存储及访问的问题,微博基于 Redis 定制开发了计数服务系统,该计数服务兼容 Redis 协议,将所有数据分别存储在内存和磁盘 2 个区域。首先,内存会预分配 N 块大小相同的 Table 空间,线上一般每个 Table 占用 1G 字节,最大分配 10 个左右的 Table 空间。首先使用 Table0,当存储填充率超过阀值,就使用 Table1,依次类推。每个 Table 中,key 是微博 id,value 是自定义的多个计数。
微博的 id 按时间递增,因此每个内存 Table 只用存储一定范围内的 id 即可。内存 Table 预先按设置分配为相同 size 大小的 key-value 槽空间。每插入一个新 key,就占用一个槽空间,当槽位填充率超过阀值,就滚动使用下一个 Table,当所有预分配的 Table 使用完毕,还可以根据配置,继续从内存分配更多新的 Table 空间。当内存占用达到阀值,就会把内存中 id 范围最小的 Table 落盘到 SSD 磁盘。落盘的 Table 文件称为 DDB。每个内存 Table 对应落盘为 1 个 DDB 文件。
计数服务会将落盘 DDB 文件的索引记录在内存,这样当查询需要从内存穿透到磁盘时,可以直接定位到磁盘文件,加快查询速度。
计数服务可以设置 Schema 策略,使一个 key 的 value 对应存储多个计数。每个计数占用空间根据 Schema 确定,可以精确到 bit。key 中的各个计数,设置了最大存储空间,所以只能支持有限范围内的计数。如果计数超过设置的阀值,则需要将这个 key 从 Table 中删除,转储到 aux dict 辅助词典中。
同时每个 Table 负责一定范围的 id,由于微博 id 随时间增长,而非逐一递增,Table 滚动是按照填充率达到阀值来进行的。当系统发生异常时,或者不同区域网络长时间断开重连后,在老数据修复期间,可能在之前的 Table 中插入较多的计数 key。如果旧 Table 插入数据量过大,超过容量限制,或者持续搜索存储位置而不得,查找次数超过阀值,则将新 key 插入到 extend dict 扩展词典中。
微博中的 feed 一般具有明显的冷热区分,并且越新的 feed 越热,访问量越大,越久远的 feed 越冷。新的热 key 存放内存 Table,老的冷 key 随所在的 Table 被置换到 DDB 文件。当查询 DDB 文件中的冷 key 时,会采用多线程异步并行查询,基本不影响业务的正常访问。同时,这些冷 key 从 DDB 中查询后,会被存放到 LRU 中,从而方便后续的再次访问。
计数服务的内存数据快照仍然采用前面讲的 RDB + 滚动 AOF 策略。RDB 记录构建时刻对应的 AOF 文件 id 及 pos 位置。全量复制时,master 会将磁盘中的 DDB 文件,以及内存数据快照对应的 RDB 和 AOF 全部传送给 slave。
在之后的所有复制就是全增量复制,slave 在断开连接,再次重连 master 时,汇报自己同步的 AOF 文件 id 及位置,master 将对应文件位置之后的内容全部发送给 slave,即可完成同步。
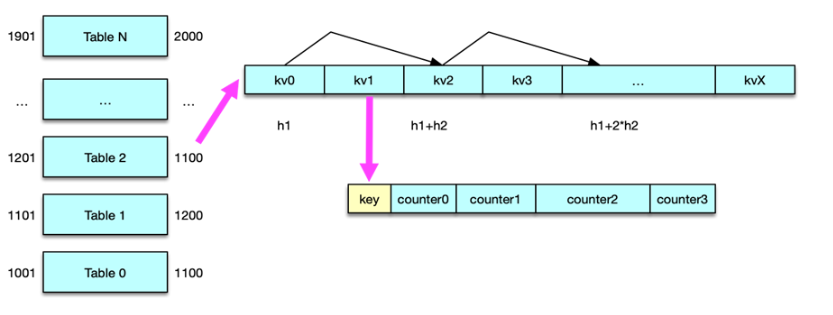
计数服务中的内存 Table 是一个一维开放数据,每个 key-value 按照 Schema 策略占用相同的内存。每个 key-value 内部,key 和多个计数紧凑部署。首先 8 字节放置 long 型 key,然后按Schema 设置依次存放各个计数。
key 在插入及查询时,流程如下。
首先根据所有 Table 的 id 范围,确定 key 所在的内存 Table。
然后再根据 double-hash 算法计算 hash,用 2 个 hash 函数分别计算出 2 个 hash 值,采用公示 h1+N*h2 来定位查找。
在对计数插入或变更时,如果查询位置为空,则立即作为新值插入 key/value,否则对比 key,如果 key 相同,则进行计数增减;如果 key 不同,则将 N 加 1,然后进入到下一个位置,继续进行前面的判断。如果查询的位置一直不为空,且 key 不同,则最多查询设置的阀值次数,如果仍然没查到,则不再进行查询。将该 key 记录到 extend dict 扩展词典中。
在对计数 key 查找时,如果查询的位置为空,说明 key 不存在,立即停止。如果 key 相同,返回计数,否则 N 加 1,继续向后查询,如果查询达到阀值次数,没有遇到空,且 key 不同,再查询 aux dict 辅助字典 和 extend dict 扩展字典,如果也没找到该 key,则说明该 key 不存在,即计数为 0。
海量计数服务收益
微博计数服务,多个计数按 Schema 进行紧凑存储,共享同一个 key,每个计数的 size 按 bit 设计大小,没有额外的指针开销,内存占用只有 Redis 的 10% 以下。同时,由于 key 的计数 size 固定,如果计数超过阀值,则独立存储 aux dict 辅助字典中。
同时由于一个 key 存储多个计数,同时这些计数一般都需要返回,这样一次查询即可同时获取多个计数,查询性能相比每个计数独立存储的方式提升 3~5 倍。
如何为社交feed场景设计缓存体系
Feed 流场景分析
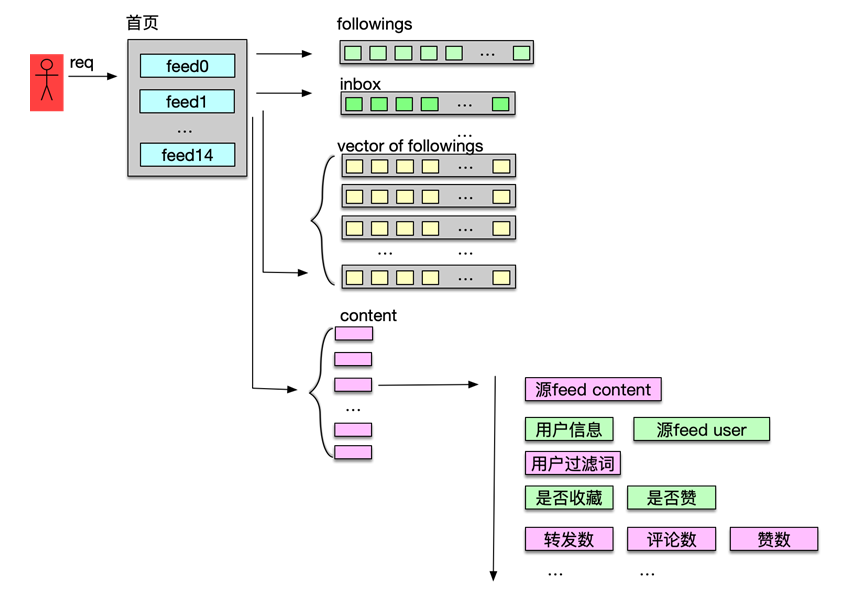
Feed 流是很多移动互联网系统的重要一环,如微博、微信朋友圈、QQ 好友动态、头条/抖音信息流等。虽然这些产品形态各不相同,但业务处理逻辑却大体相同。用户日常的“刷刷刷”,就是在获取 Feed 流,这也是 Feed 流的一个最重要应用场景。用户刷新获取 Feed 流的过程,对于服务后端,就是一个获取用户感兴趣的 Feed,并对 Feed 进行过滤、动态组装的过程。
接下来,我将以微博为例,介绍用户在发出刷新 Feed 流的请求后,服务后端是如何进行处理的。
获取 Feed 流操作是一个重操作,后端数据处理存在 100 ~ 1000 倍以上的读放大。也就是说,前端用户发出一个接口请求,服务后端需要请求数百甚至数千条数据,然后进行组装处理并返回响应。因此,为了提升处理性能、快速响应用户,微博 Feed 平台重度依赖缓存,几乎所有的数据都从缓存获取。如用户的关注关系从 Redis 缓存中获取,用户发出的 Feed 或收到特殊 Feed 从 Memcached 中获取,用户及 Feed 的各种计数从计数服务中获取。
Feed 流流程分析
Feed 流业务作为微博系统的核心业务,为了保障用户体验,SLA 要求较高,核心接口的可用性要达到 4 个 9,接口耗时要在 50100ms 以内,后端数据请求平均耗时要在 35ms 以内,因此为了满足亿级庞大用户群的海量并发访问需求,需要对缓存体系进行良好架构且不断改进。
在 Feed 流业务中,核心业务数据的缓存命中率基本都在 99% 以上,这些缓存数据,由 Feed 系统进行多线程并发获取及组装,从而及时发送响应给用户。
Feed 流获取的处理流程如下。
首先,根据用户信息,获取用户的关注关系,一般会得到 300~2000 个关注用户的 UID。
然后,再获取用户自己的 Feed inbox 收件箱。收件箱主要存放其他用户发表的供部分特定用户可见的微博 ID 列表。
接下来,再获取所有关注列表用户的微博 ID 列表,即关注者发表的所有用户或者大部分用户可见的 Feed ID 列表。这些 Feed ID 列表都以 vector 数组的形式存储在缓存。由于一般用户的关注数会达到数百甚至数千,因此这一步需要获取数百或数千个 Feed vector。
然后,Feed 系统将 inbox 和关注用户的所有 Feed vector 进行合并,并排序、分页,即得到目标 Feed 的 ID 列表。
接下来,再根据 Feed ID 列表获取对应的 Feed 内容,如微博的文字、视频、发表时间、源微博 ID 等。
然后,再进一步获取所有微博的发表者 user 详细信息、源微博内容等信息,并进行内容组装。
之后,如果用户设置的过滤词,还要将这些 Feed 进行过滤筛选,剔除用户不感兴趣的 Feed。
接下来,再获取用户对这些 Feed 的收藏、赞等状态,并设置到对应微博中。
最后,获取这些 Feed 的转发数、评论数、赞数等,并进行计数组装。至此,Feed 流获取处理完毕,Feed 列表以 JSON 形式返回给前端,用户刷新微博首页成功完成。
Feed 流缓存架构
Feed 流处理中,缓存核心业务数据主要分为 6 大类。
第一类是用户的 inbox 收件箱,在用户发表仅供少量用户可见的 Feed 时,为了提升访问效率,这些 Feed ID 并不会进入公共可见的 outbox 发件箱,而会直接推送到目标客户的收件箱。
第二类是用户的 outbox 发件箱。用户发表的普通微博都进入 outbox,这些微博几乎所有人都可见,由粉丝在刷新 Feed 列表首页时,系统直接拉取组装。
第三类是 Social Graph 即用户的关注关系,如各种关注列表、粉丝列表。
第四类是 Feed Content 即 Feed 的内容,包括 Feed 的文字、视频、发表时间、源微博 ID 等。
第五类是 Existence 存在性判断缓存,用来判断用户是否阅读了某条 Feed,是否赞了某条 Feed 等。对于存在性判断,微博是采用自研的 phantom 系统,通过 bloomfilter 算法进行存储的。
第六类是 Counter 计数服务,用来存储诸如关注数、粉丝数,Feed 的转发、评论、赞、阅读等各种计数。
对于 Feed 的 inbox 收件箱、outbox 发件箱,Feed 系统通过 Memcached 进行缓存,以 feed id的一维数组格式进行存储。
对于关注列表,Feed 系统采用 Redis 进行缓存,存储格式为 longset。longset 在之前的课时介绍过,是微博扩展的一种数据结构,它是一个采用 double-hash 寻址的一维数组。当缓存 miss 后,业务 client 可以从 DB 加载,并直接构建 longset 的二进制格式数据作为 value写入Redis,Redis 收到后直接 restore 到内存,而不用逐条加入。这样,即便用户有成千上万个关注,也不会引发阻塞。
Feed content 即 Feed 内容,采用 Memcached 存储。由于 Feed 内容有众多的属性,且时常需要根据业务需要进行扩展,Feed 系统采用 Google 的 protocol bufers 的格式进行存放。protocol buffers 序列化后的所生成的二进制消息非常紧凑,二进制存储空间比 XML 小 3~10 倍,而序列化及反序列化的性能却高 10 倍以上,而且扩展及变更字段也很方便。微博的 Feed content 最初采用 XML 和 JSON 存储,在 2011 年之后逐渐全部改为 protocol buffers 存储。
对于存在性判断,微博 Feed 系统采用自研的 phantom 进行存储。数据存储采用 bloom filter 存储结构。实际上 phantom 本身就是一个分段存储的 bloomfilter 结构。bloomFilter 采用 bit 数组来表示一个集合,整个数组最初所有 bit 位都是 0,插入 key 时,采用 k 个相互独立的 hash 函数计算,将对应 hash 位置置 1。而检测某个 key 是否存在时,通过对 key 进行多次 hash,检查对应 hash 位置是否为 1 即可,如果有一个为 0,则可以确定该 key 肯定不存在,但如果全部为 1,大概率说明该 key 存在,但该 key 也有可能不存在,即存在一定的误判率,不过这个误判率很低,一般平均每条记录占用 1.2 字节时,误判率即可降低到 1%,1.8 字节,误判率可以降到千分之一。基本可以满足大多数业务场景的需要。
对于计数服务,微博就是用前面讲到的 CounterService。CounterService 采用 schema 策略,支持一个 key 对应多个计数,只用 510% 的空间,却提升 35 倍的读取性能。
对于 Feed 流中的 Redis 存储访问,业务的 Redis 部署基本都采用 1 主多从的方式。同时多个子业务按类型分为 cluster 集群,通过多租户 proxy 进行访问。对于一些数据量很小的业务,还可以共享 Redis 存储,进行混合读写。对于一些响应时间敏感的业务,基于性能考虑,也支持smart client 直接访问 Redis 集群。整个 Redis 集群,由 clusterManager 进行运维、slot 维护及迁移。配置中心记录集群相关的 proxy 部署及 Redis 配置及部署等。这个架构在之前的经典分布式缓存系统课程中有详细介绍,此处不再赘述。





