
销售提成计算引擎实现
销售提成计算引擎实现
1. 模块概述
该模块是销售提成计算系统的具体实现层,基于模板方法模式设计,实现了不同业务线(BPO、HRO)的提成计算逻辑。
2. 目录结构
1 | CopyInsertcalculation/engine/ |
3. 核心组件说明
3.1 计算引擎接口
CalculationEngine
定义了计算引擎的基本契约
核心方法:
calculation(CalculationDto): 执行业务数据核算supportedProductLine(): 声明支持的产品线类型
3.2 抽象计算引擎
AbstractCalculationEngine
实现了计算引擎的通用逻辑
核心功能:
- 计算流程控制
calculation(CalculationDto): 总体计算流程控制processCalculation(): 执行具体计算过程validateCalculationDto(): 验证计算参数
- 数据处理
getDetailData(): 获取业务数据getBasicSubjectValues(): 获取基础科目值processTableDataBatch(): 处理单个表数据(in查询批量处理)setDetailInfoBasicSubjectValues(): 设置明细数据基础科目值
- 结果处理
processCalculationResults(): 处理计算结果writeCalculationDetail(): 写入计算明细handleCalculationSuccess(): 处理计算成功handleCalculationFailure(): 处理计算失败handleErrorResults(): 处理错误结果
3.3 具体业务实现
3.3.1 BPO业务计算引擎
BpoCalculationEngine
特点:
继承
AbstractCalculationEngine实现BPO业务特有的数据获取和处理逻辑
核心方法:
getDetailData(): 获取BPO业务数据writeDetailInfo(): 写入BPO计算结果supportedProductLine(): 返回BPO产品线标识
3.3.2 HRO业务计算引擎
HroCalculationEngine
特点:
继承
AbstractCalculationEngine实现HRO业务特有的数据获取和处理逻辑
核心方法:
getDetailData(): 获取HRO业务数据writeDetailInfo(): 写入HRO计算结果supportedProductLine(): 返回HRO产品线标识
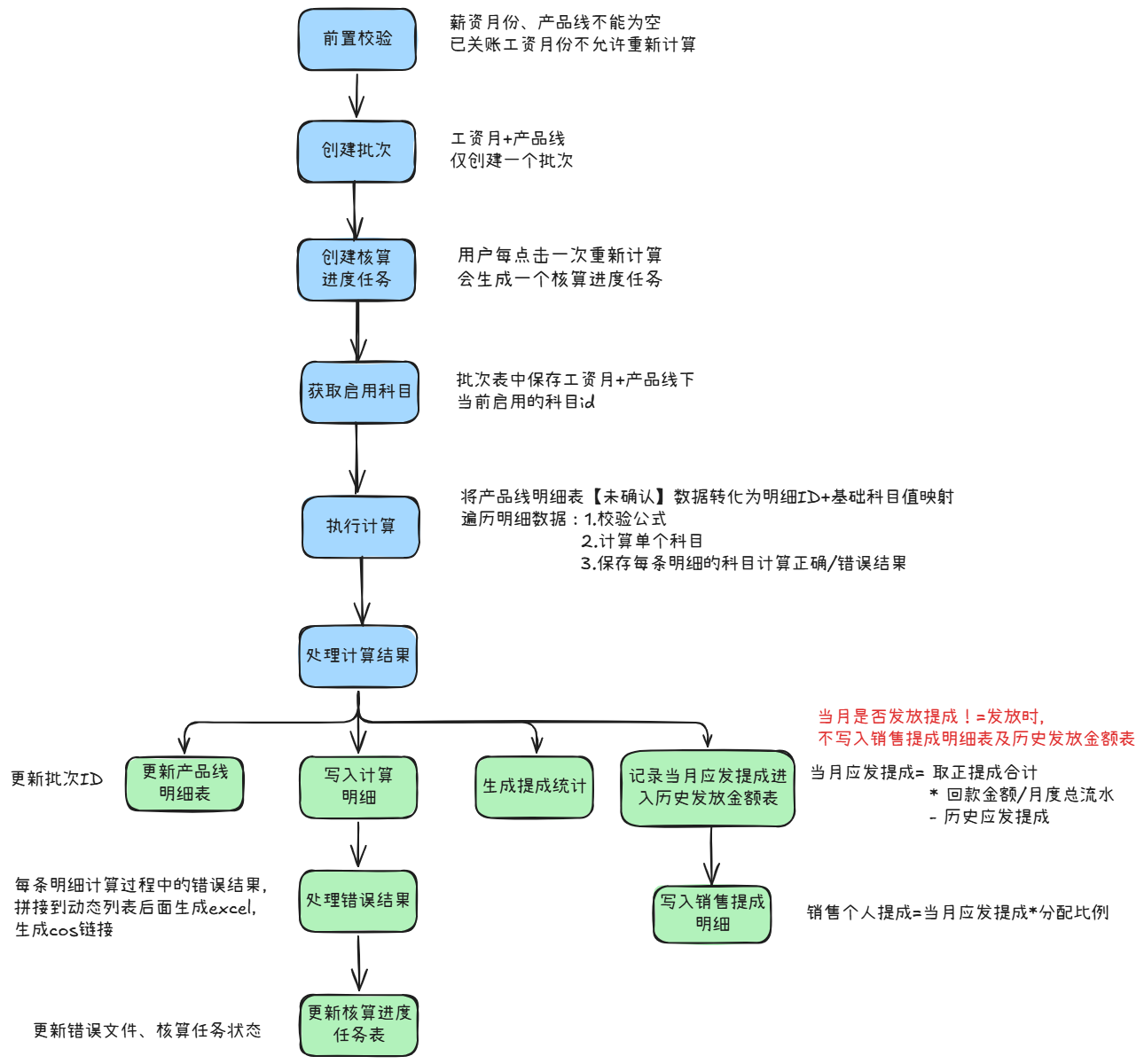
4. 核心流程说明
4.1 计算流程
参数验证
1
validateCalculationDto(calculationDto)
获取分布式锁
1
2
3
4RLock lock = redissonClient.getLock(RedisConstant.CALCULATION_LOCK_PREFIX + batch.getId());
if (!lock.tryLock()) {
throw new BusinessException("核算进行中,请稍后再试");
}创建计算任务
1 | SysCalculationProcess process = calculationProcessService |
- 用户登录信息存入上下文
因计算过程是异步的,且区分于定时任务调用、用户手动调用,需在核算开始前添加用户登录信息至上下文,核算结束后生成的错误文件明细数据是用户数据权限下的数据。
1 | // 优先从 上下文 获取用户,如果没有再从 ServletUtils 获取 |
用户装饰器类,这里使用了装饰器模式,不修改原有的代码结构的前提下,动态地在异步任务开始前设置用户上下文,异步任务结束后清理用户的上下文。
1 |
|
- 获取业务数据
1 | List<DetailData> details = getDetailData(calculationDto) |
获取基础科目值
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93private Map<Long, Map<String, Object>> getBasicSubjectValues(List<SysSubject> subjects, List<DetailData> details) {
// 1.提取基础科目ID
Set<Long> basicSubjectIds = extractBasicSubjectIds(subjects);
// 2. 根据基础科目ID获取基础科目
List<SysBasicSubject> basicSubjects = basicSubjectService.getBasicSubjectById(new ArrayList<>(basicSubjectIds));
// 3. 获取基础科目值
return doGetBasicSubjectValue(basicSubjects, details);
}
/**
* 获取基础数据
*/
protected Map<Long, Map<String, Object>> doGetBasicSubjectValue(List<SysBasicSubject> basicSubjects,
List<DetailData> details) {
if (CollectionUtils.isEmpty(basicSubjects) || CollectionUtils.isEmpty(details)) {
return Collections.emptyMap();
}
Map<Long, Map<String, Object>> basicSubjectValues = new HashMap<>();
List<Long> detailIds = details.stream().map(DetailData::getDetailInfoId).collect(Collectors.toList());
// 1. 按表分组的同时预处理字段映射
Map<String, TableQueryInfo> tableQueries = basicSubjects.stream()
.collect(Collectors.groupingBy(
SysBasicSubject::getTableName,
Collectors.collectingAndThen(
Collectors.toList(),
TableQueryInfo::new
)
));
// 2. 批量处理数据
int batchSize = 1000;
List<List<Long>> batches = CollUtil.split(detailIds, batchSize);
for (Map.Entry<String, TableQueryInfo> entry : tableQueries.entrySet()) {
String tableName = entry.getKey();
TableQueryInfo queryInfo = entry.getValue();
// 3. 分批查询
for (List<Long> batchIds : batches) {
processTableDataBatch(tableName, queryInfo, batchIds, basicSubjectValues);
}
}
return basicSubjectValues;
}
// 封装表查询信息
private static class TableQueryInfo {
final Map<String, String> fieldToSubjectCode;
final String queryFields;
TableQueryInfo(List<SysBasicSubject> subjects) {
this.fieldToSubjectCode = subjects.stream()
.collect(Collectors.toMap(
SysBasicSubject::getFieldName,
SysBasicSubject::getSubjectCode,
(v1, v2) -> v1
));
List<String> fields = new ArrayList<>(fieldToSubjectCode.keySet());
fields.add("id");
this.queryFields = String.join(",", fields);
}
}
/**
* 处理单个表的数据
* @param tableName 表名
* @param queryInfo 查询条件 subject
* @param batchIds 明细id
* @param basicSubjectValues 基础科目映射
*/
private void processTableDataBatch(String tableName, TableQueryInfo queryInfo,
List<Long> batchIds, Map<Long, Map<String, Object>> basicSubjectValues) {
String condition = "AND id in (" + CollUtil.join(batchIds, ",") + ")";
List<Map<String, Object>> basicData = dynamicQueryService.queryDynamic(tableName, queryInfo.queryFields, condition);
// 4. 使用批量处理
basicData.forEach(data -> {
Long id = Convert.toLong(data.get("id"));
Map<String, Object> subjectValues = basicSubjectValues.computeIfAbsent(id, k -> new HashMap<>());
data.forEach((field, value) -> {
String subjectCode = queryInfo.fieldToSubjectCode.get(field);
if (StrUtil.isNotBlank(subjectCode)) {
subjectValues.put(subjectCode, value);
}
});
});
}执行计算
1 | // 执行计算 |
为了提升每次核算的速度,将每条明细数据的核算过程并行处理。因为计算过程都是基于内存的操作,所以整个流程非常快。
1 | /** |
每次计算都创建一次计算上下文,计算完成后将计算结果存进内存
1 | private CalculationResult calculateDetail(DetailData detail) { |
使用规则引擎进行计算
1 | /** |
使用懒加载模式,只在首次使用时初始化,避免了类加载时的初始化开销,保持了线程安全性
1 | public static Object computer(String express, DefaultContext<String, Object> context) { |
1 | /** |
- 处理结果
将批次id写入提成明细
写入科目计算结果
写入销售提成金额
处理错误信息,生成错误文件
1
2
3
4
5
6
7// 第一个事务:处理核心计算结果
transactionTemplate.executeWithoutResult(status -> {
writeDetailInfo(results, batch);
writeCalculationDetail(results, batch);
writeSaleCommissionDetail(results, batch);
handleErrorResults(results, process, calculationDto.getSalaryMonth());
});实时生成提成统计,并更改任务状态
1 | try { |
4.2 错误处理
- 计算失败处理
1
handleCalculationFailure(batch, process, exception)
- 结果错误处理
1
handleErrorResults(results, process)
5. 扩展指南
5.1 添加新的业务线
创建新的业务线计算引擎类,继承
AbstractCalculationEngine实现必要的抽象方法:
getDetailData()writeDetailInfo()supportedProductLine()
根据业务需求,可能需要重写其他方法
5.2 修改计算逻辑
- 核心计算逻辑在
processCalculation()方法中 - 基础数据处理逻辑在
getBasicSubjectValues()方法中 - 结果处理逻辑在
processCalculationResults()方法中


