
RocketMQ消息发送常见错误及解决方案
No route info of this topic
通常情况下 No route info of this topic 这个错误一般是在刚搭建 RocketMQ、刚入门 RocketMQ 遇到的比较多。通常的排查思路如下。
可以通过 RocketMQ-Console 查询路由信息是否存在,或使用如下命令查询路由信息:
1 | cd ${ROCKETMQ_HOME}/bin |
- 如果通过命令无法查询到路由信息,则查看 Broker 是否开启了自动创建 Topic,参数为 autoCreateTopicEnable,该参数默认为 true。但在生产环境不建议开启。
- 如果开启了自动创建路由信息,但还是抛出这个错误,这个时候请检查客户端(Producer)连接的 NameServer 地址是否与 Broker 中配置的 NameServer 地址是否一致。
经过上面的步骤,基本就能解决该错误。
消息发送超时
RemotingTimeoutException:wait response on the channel<> timeout,3000ms
首先我们执行如下命令查看 RocketMQ 消息写入的耗时分布情况:
1 | cd /${USER.HOME}/logs/rocketmqlogs/ |
RocketMQ 会每一分钟打印前一分钟内消息发送的耗时情况分布,我们从这里就能窥探 RocketMQ 消息写入是否存在明细的性能瓶颈,其区间如下:
- [<=0ms] 小于 0ms,即微妙级别的
- [0~10ms] 小于 10ms 的个数
- [10~50ms] 大于 10ms 小于 50ms 的个数
其他区间显示,绝大多数会落在微秒级别完成,如果 100~200ms 及以上的区间超过 20 个,说明 Broker 确实存在一定的瓶颈,如果只是少数几个,说明这个是内存或 PageCache 的抖动,问题不大。
若出现网络超时,有什么解决方法?
减少消息发送的超时时间,增加重试次数,并增加快速失败的最大等待时长。具体措施如下。
- 增加 Broker 端快速失败的时长,建议为 1000,在 Broker 的配置文件中增加如下配置:
1 | maxWaitTimeMillsInQueue=1000 |
如果 RocketMQ 的客户端版本为 4.3.0 以下版本(不含 4.3.0):
将超时时间设置消息发送的超时时间为 500ms,并将重试次数设置为 6 次(这个可以适当进行调整,尽量大于 3)
尽快超时,并进行重试,并且 RocketMQ 有故障规避机制,重试的时候会尽量选择不同的 Broker,相关的代码如下:
1 | DefaultMQProducer producer = new DefaultMQProducer("dw_test_producer_group"); |
如果 RocketMQ 的客户端版本为 4.3.0 及以上版本:
由于其设置的消息发送超时时间为所有重试的总的超时时间,故不能直接通过设置 RocketMQ 的发送 API 的超时时间,而是需要对其 API 进行包装,重试需要在外层收到进行,例如示例代码如下:
1 | public static SendResult send(DefaultMQProducer producer, Message msg, int |
System busy、Broker busy
纵观 RocketMQ 与 System busy、Broker busy 相关的错误关键字,总共包含如下 5 个:
1 | [REJECTREQUEST]system busy |
异常原因
根据上述 5 类错误日志,其触发的原由可以归纳为如下 3 种。
PageCache 压力较大
其中如下三类错误属于此种情况:
1 | []system busy |
判断 PageCache 是否忙的依据就是,在写入消息、向内存追加消息时加锁的时间,默认的判断标准是加锁时间超过 1s,就认为是 PageCache 压力大,向客户端抛出相关的错误日志。
发送线程池挤压的拒绝策略
在 RocketMQ 中处理消息发送的,是一个只有一个线程的线程池,内部会维护一个有界队列,默认长度为 1W。如果当前队列中挤压的数量超过 1w,执行线程池的拒绝策略,从而抛出 [too many requests and system thread pool busy] 错误。
Broker 端快速失败
[TIMEOUT_CLEAN_QUEUE]broker busy
默认情况下 Broker 端开启了快速失败机制,就是在 Broker 端还未发生 PageCache 繁忙(加锁超过 1s)的情况,但存在一些请求在消息发送队列中等待 200ms 的情况,RocketMQ 会不再继续排队,直接向客户端返回 System busy,但由于 RocketMQ 客户端目前对该错误没有进行重试处理,所以在解决这类问题的时候需要额外处理。
解决方案
PageCache 繁忙解决方案
一旦消息服务器出现大量 PageCache 繁忙(在向内存追加数据加锁超过 1s)的情况,这个是比较严重的问题,需要人为进行干预解决,解决的问题思路如下。
1.transientStorePoolEnable
开启 transientStorePoolEnable 机制,即在 Broker 中配置文件中增加如下配置:
1 | transientStorePoolEnable=true |
引入 transientStorePoolEnable 能缓解 PageCache 的压力背后关键如下:
- 消息先写入到堆外内存中,该内存由于启用了内存锁定机制,故消息的写入是接近直接操作内存,性能可以得到保证。
- 消息进入到堆外内存后,后台会启动一个线程,一批一批将消息提交到 PageCache,即写消息时对 PageCache 的写操作由单条写入变成了批量写入,降低了对 PageCache 的压力。
引入 transientStorePoolEnable 会增加数据丢失的可能性,如果 Broker JVM 进程异常退出,提交到 PageCache 中的消息是不会丢失的,但存在堆外内存(DirectByteBuffer)中但还未提交到 PageCache 中的这部分消息,将会丢失。但通常情况下,RocketMQ 进程退出的可能性不大,通常情况下,如果启用了 transientStorePoolEnable,消息发送端需要有重新推送机制(补偿思想)。
2.扩容
如果在开启了 transientStorePoolEnable 后,还会出现 PageCache 级别的繁忙,那需要集群进行扩容,或者对集群中的 Topic 进行拆分,即将一部分 Topic 迁移到其他集群中,降低集群的负载。
温馨提示:在Broker扩容时候,可以复制集群中任意一台Broker服务下${ROCKETMQ_HOME}/store/config/topics.json到新Broker服务器指定目录,避免在新Broker服务器上为Broker创建队列,然后消息发送者、消息消费者都能动态获取Topic的路由信息。
TIMEOUT_CLEAN_QUEUE 解决方案
由于如果出现 TIMEOUT_CLEAN_QUEUE 的错误,客户端暂时不会对其进行重试,故现阶段的建议是适当增加快速失败的判断标准,即在 Broker 的配置文件中增加如下配置:
1 | #该值默认为 200,表示 200ms |
处理消息堆积
问题现象
在使用云消息队列 RocketMQ 版实例时收到消息堆积告警,登录云消息队列 RocketMQ 版控制台后发现了下列现象:
- 在Group 详情页面,看到Group ID的实时消息堆积量的值高于预期。
- 导航栏中选择消息轨迹,单击创建查询任务,选择按 Message ID 查询,输入对应的信息,发现部分消息已发送至Broker节点,但未投递给下游消费者。
可能原因
云消息队列 RocketMQ 版的消息发送至Broker节点后,配置了Group ID的客户端根据当前的消费位点,从Broker节点拉取部分消息到本地进行消费,拉取到的消息缓存到本地缓冲队列中。
一般情况下,客户端从Broker节点拉取消息的过程不会导致消息堆积,例如:1个单线程单分区的低规格机器(4C8GB)可以达到几万TPS,如果是多个分区可以达到几十万TPS。所以这一阶段一般不会成为消息堆积的瓶颈。
主要是客户端本地消费过程中,由于消费耗时过长或消费并发度较小等原因,导致客户端消费能力不足,出现消息堆积的问题。
消息出现堆积,可能原因如下:
- 消费者消息处理逻辑异常,导致消息无法正常消费。
- 消息生产应用出现突发流量,消息生产速度远大于消费速度,消息来不及消费出现堆积。
- 消费者依赖的下游服务耗时变长,消费线程阻塞等。
- 消费线程不够,消费并发度较小,消费速度跟不上生产速度。
解决方案
若出现消息堆积,可参考以下措施进行定位和处理。
判断消息堆积在云消息队列 RocketMQ 版服务端还是客户端。
查看客户端本地日志文件
ons.log,搜索是否出现如下信息:1
the cached message count exceeds the threshold
- 出现相关日志信息,说明客户端本地缓冲队列已满,消息堆积在客户端,请执行步骤2。
- 若未出现相关日志,说明消息堆积不在客户端,若出现这种特殊情况,请直接联系阿里云技术支持。
确认消息的消费耗时是否合理。
- 若查看到消费耗时较长,则需要查看客户端堆栈信息排查具体业务逻辑,请执行步骤3。
- 若查看到消费耗时正常,则有可能是因为消费并发度不够导致消息堆积,需要逐步调大消费线程或扩容节点来解决。
消息的消费耗时可以通过以下方式查看:
- 登录云消息队列 RocketMQ 版控制台查看消息的消费轨迹,在消费者区域中可以看到单条消息的消费耗时。
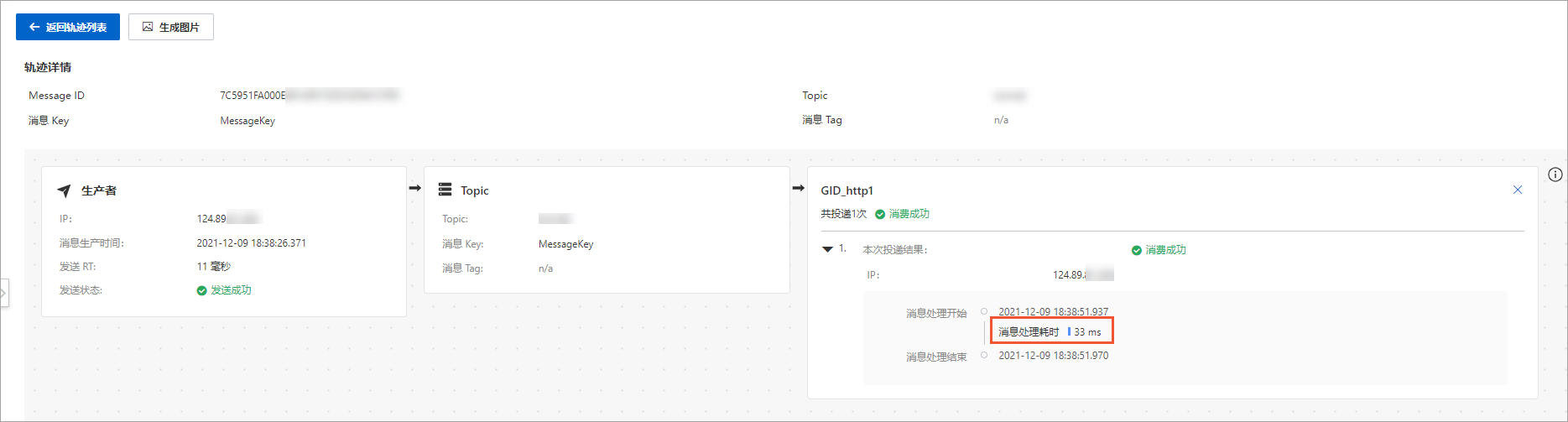
登录云消息队列 RocketMQ 版控制台查看消费者状态,在客户端连接信息中查看业务处理时间,获取消费耗时的平均值。

- 查看客户端堆栈信息。只需要关注线程名为ConsumeMessageThread的线程,这些都是业务消费消息的逻辑。
客户端堆栈信息可以通过以下方式获取:
- 登录云消息队列 RocketMQ 版控制台查看消费者状态,在客户端连接信息中查看Java客户端堆栈信息。
- 使用Jstack工具打印堆栈信息。
执行以下任意命令,查看并记录Java进程的PID。
1 | ps -ef |
执行以下命令,查看堆栈信息。
1 | jstack -l pid > /tmp/pid.jstack |
执行以下命令,查看ConsumeMessageThread的信息。
1 | cat /tmp/pid.jstack|grep ConsumeMessageThread -A 10 --color |
常见的异常堆栈信息如下:
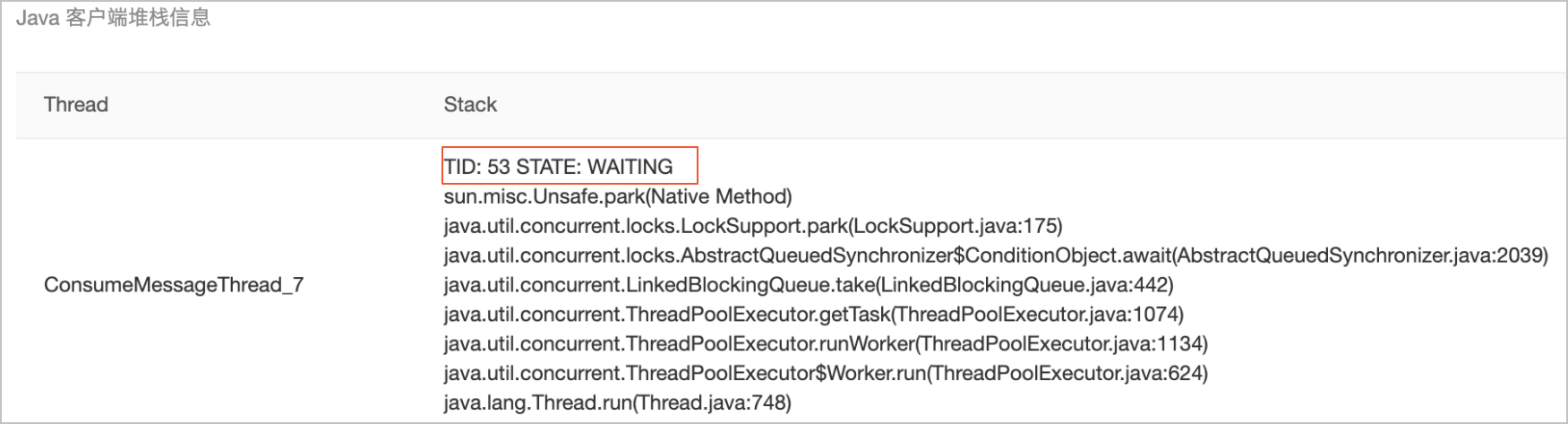
示例一:空闲无堆积的堆栈。
消费空闲情况下消费线程都会处于WAITING状态等待从消费任务队中获取消息。
示例二:消费逻辑有抢锁休眠等待等情况。
消费线程阻塞在内部的一个睡眠等待上,导致消费缓慢。

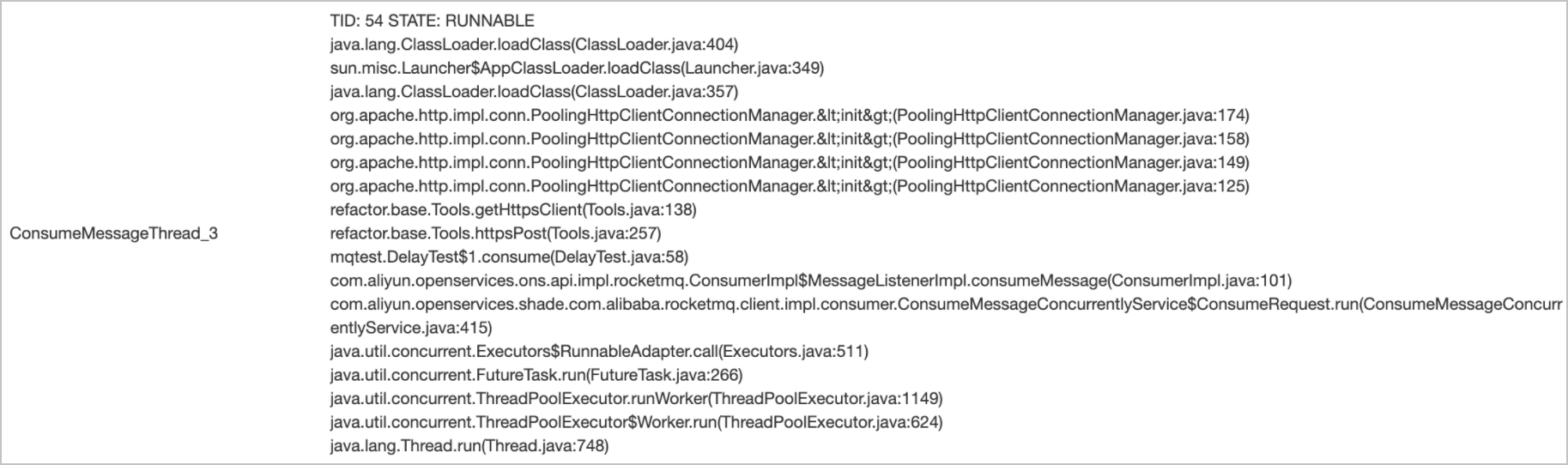
示例三:消费逻辑操作数据库等外部存储卡住。
消费线程阻塞在外部的HTTP调用上,导致消费缓慢。
针对某些特殊业务场景,如果消息堆积已经影响到业务运行,且堆积的消息本身可以跳过不消费,您可以通过重置消费位点跳过这些堆积的消息从最新位点开始消费,快速恢复业务。(广播模式不支持重置消费位点,且消费者必须在线才能重置消费位点)
最新位点开始消费:若选择此项,该Group ID在消费指定Topic下的消息时会跳过当前堆积(未被消费)的所有消息,从最新消息开始消费。
警告
若选择从最新位点开始消费,则Group ID在指定Topic中的堆积消息将被全部清除,该操作大概2
3分钟后生效,请勿重复操作。期间应用所有的消费者将暂停消费23分钟,对延迟敏感的业务请谨慎使用。从指定时间点的位点开始消费:选择此项后会出现时间选择控件。请指定一个时间点,消费者将从这个时间点之后发送的消息开始消费,不管之前的消息是否又被消费过。(通过重置消费位点最多可重新消费到3天前的消息)
目前重置消息功能对重试中消息不生效,因此重置后仍然可能会有少量重试消息投递。
若某个消费组下的机器宕机,机器重启期间,消息会不会丢失?
云消息队列 RocketMQ 版的订阅是持久化订阅,ConsumerGroup下线或消费异常时,消息不会丢失。当消费者客户端重新上线后,直接从下线前的消费位点继续消费消息。
创建新的消费分组订阅旧的Topic,如何设置消费起始位置?
消费者分组创建时不支持设置消费起始位置,不管是订阅新的Topic还是旧的Topic,消费者第一次启动时都会默认从Topic中的最早一条消息开始消费。
消费者首次启动后,可以重置消费位点。





