RocketMQ的最佳实践
幂等性保证
对于非幂等的请求,我们在业务里要做幂等性保证。
在消息队列中的幂等性体现
消息队列中,很可能一条消息被冗余部署的多个消费者收到,对于非幂等的操作,比如用户的注册,就需要做幂等性保证,否则消息将会被重复消费。可以将情况概括为以下几种:
生产者重复发送:由于网络抖动,导致生产者没有收到broker的ack而再次重发消息,实际上broker收到了多条重复的消息,造成消息重复
消费者重复消费:由于网络抖动,消费者没有返回ack给broker,导致消费者重试消费。
rebalance时的重复消费:由于网络抖动,在rebalance重分配时也可能出现消费者重复消费某条消息。
如何保证幂等性消费
- mysql插入业务id作为主键,主键是唯一的,所以一次只能插入一条
- 使用redis或zk的分布式锁(主流的方案)
- 添加业务性的判断,过滤掉已修改状态的数据
消息顺序消费
为什么要保证消息有序
比如有这么一个物联网的应用场景,IOT中的设备在初始化时需要按顺序接收这样的消息:
- 设置设备名称
- 设置设备的网络
- 重启设备使配置生效
如果这个顺序颠倒了,可能就没有办法让设备的配置生效,因为只有重启设备才能让配置生效,但重启的消息却在设置设备消息之前被消费
如何保证消息顺序消费
全局有序:消费的所有消息都严格按照发送消息的顺序进行消费。在 RocketMQ 中,要实现全局有序,只能使用一个队列,并且由一个消费者进行消费。这意味着无论消息来自哪个业务场景,都必须按照顺序依次处理,对系统的性能和扩展性有很大的限制。
局部有序:消费的部分消息按照发送消息的顺序进行消费。对于需要保证顺序的业务场景,将相关消息发送到同一个队列,然后由专门的消费者去处理这个队列。这样,不同业务场景的消息可以在不同的队列中并行处理,而同一业务场景下的消息则按照顺序被消费,既保证了特定业务的消息顺序,又提高了系统的整体性能。
快速处理积压消息
在RocketMQ中,如果消费者消费速度过慢,而生产者生产消息的速度又远超于消费者消费消息的速度,那么就会造成大量消息积压在MQ中。
如何查看消息积压的情况
在console控制台中可以查看:
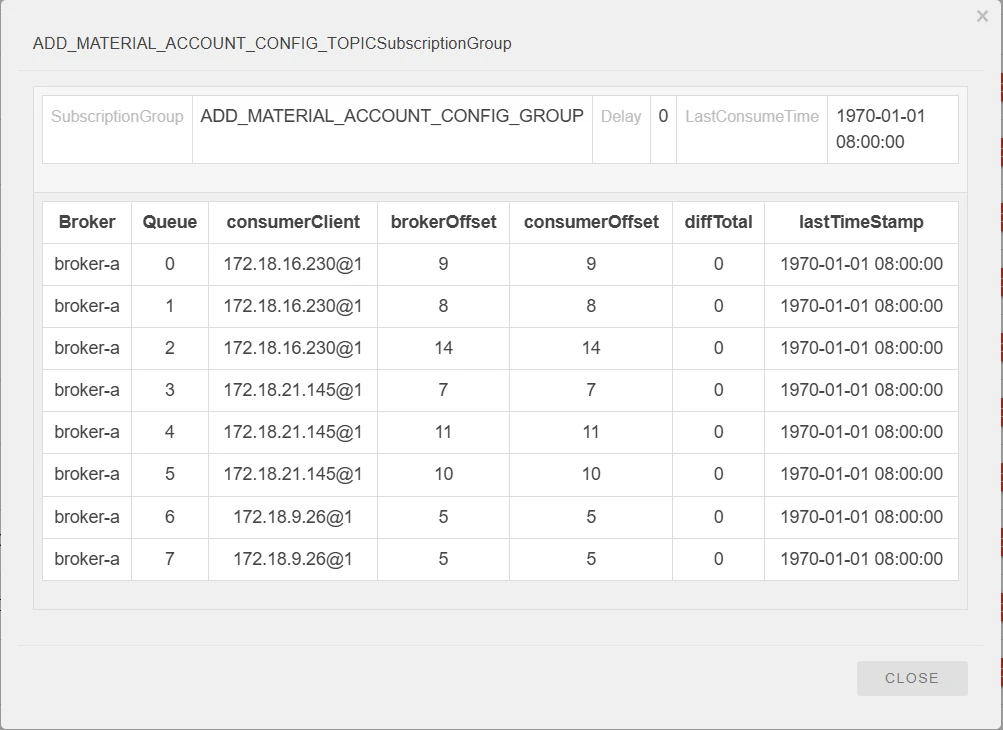
所谓的消息积压:就是 Broker 端当前队列有效数据最大的偏移量(brokerOffset)与消息消费端的当前处理进度(consumerOffset)之间的差值,即表示当前需要消费但没有消费的消息。
问题分析与解决方案
个别消费者组异常
因为一个 Topic 通常会被多个消费端订阅,我们只要看看其他消费组是否也积压,例如如下图所示:
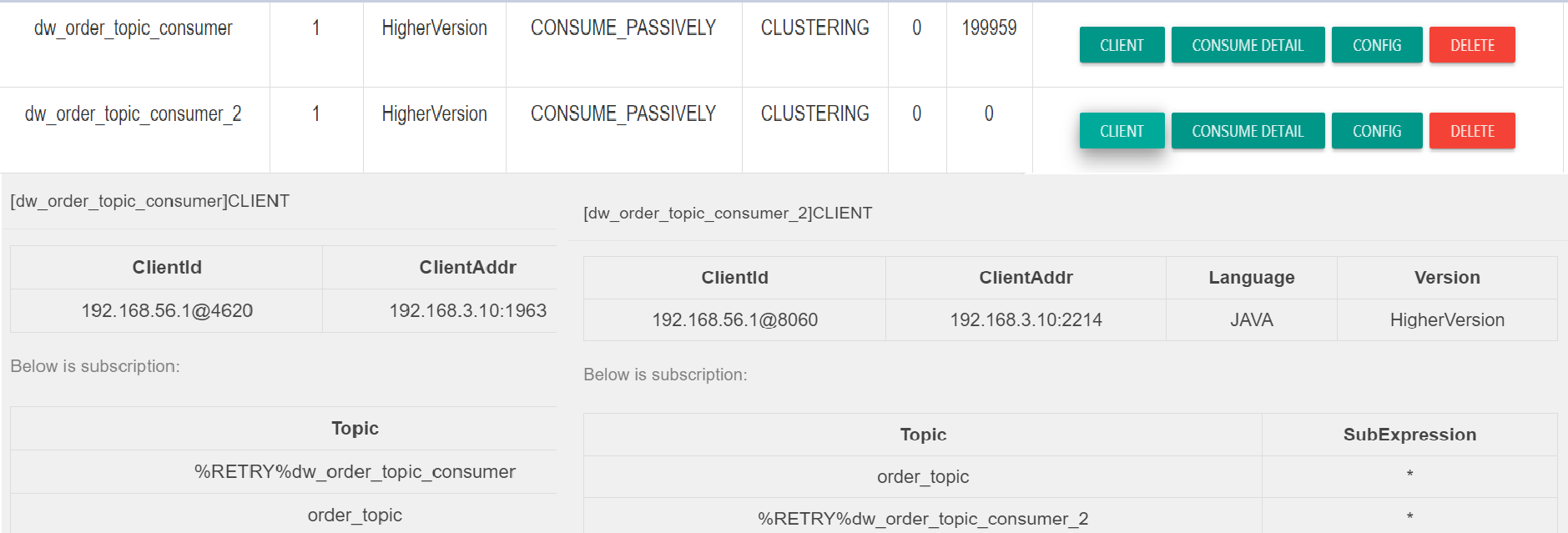
从上图看出,两个不同的消费组订阅了同一个 Topic,一个出现消息积压,一个却消费正常,从这里就可以将分析的重点定位到具体项目组。那如何具体分析这个问题呢?
在 RocketMQ 中每一客户端会单独创建一个线程 PullMessageService 会循环从 Broker 拉取一批消息,然后提交到消费端的线程池中进行消费,线程池中的线程消费完一条消息后会上服务端上报当前消费端的消费进度,而且在提交消费进度时是提交当前处理队列中消息消费偏移量最小的消息作为消费组的进度,即如果消息偏移量为 100 的消息,如果由于某种原因迟迟没有消费成功,那该消费组的进度则无法向前推进,久而久之,Broker 端的消息偏移量就会远远大于消费组当前消费的进度,从而造成消息积压现象。
可通过 jps -m 或者 ps -ef | grep java 命令获取当前正在运行的 Java 程序,通过启动主类即可获得应用的进程 id,然后可以通过 jstack pid > j.log 命令获取线程的堆栈,在这里我建议大家连续运行 5 次该命令,分别获取 5 个线程堆栈文件,主要用于对比线程的状态是否在向前推进。
通过 jstack 获取堆栈信息后,可以重点搜索 ConsumeMessageThread_ 开头的线程状态,例如下图所示:
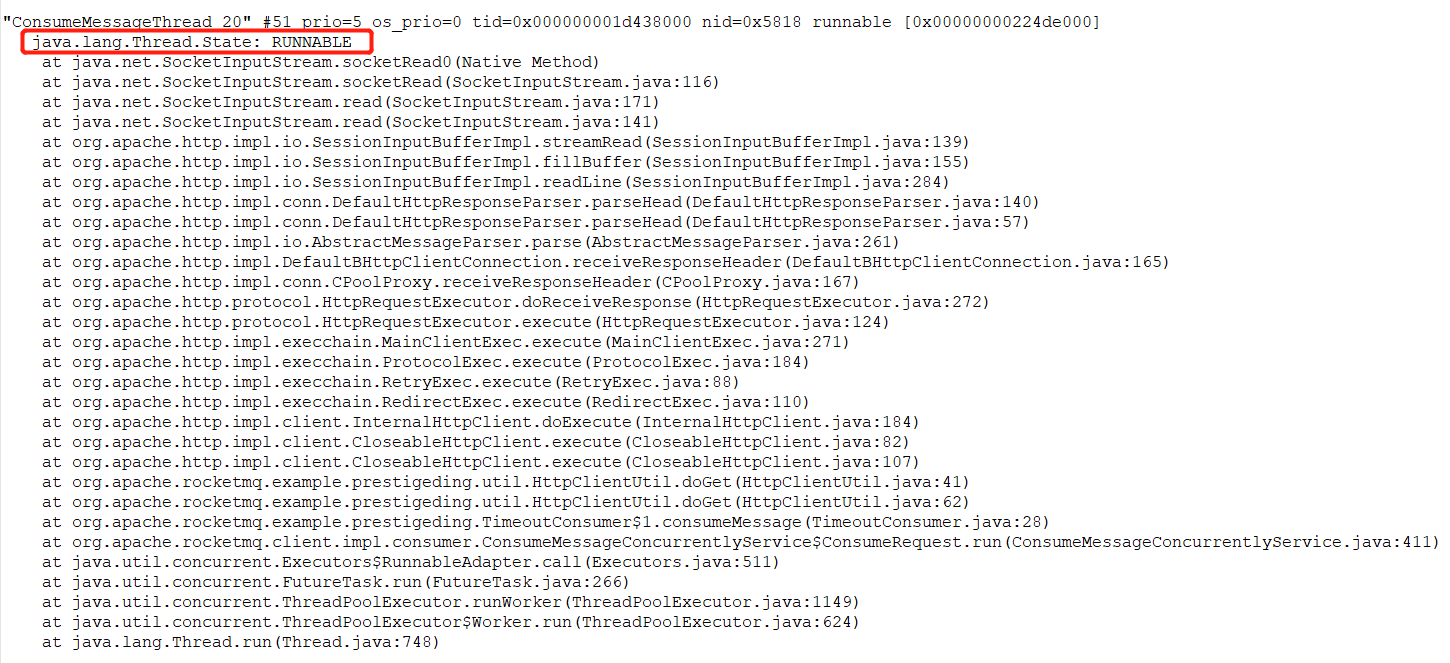
状态为 RUNABLE 的消费端线程正在等待网络读取,我们再去其他文件看该线程的状态,如果其状态一直是 RUNNABLE,表示线程一直在等待网络读取,及线程一直“阻塞”在网络读取上,一旦阻塞,那该线程正在处理的消息就一直处于消费中,消息消费进度就会卡在这里,不会继续向前推进,久而久之,就会出现消息积压情况。
从调用线程栈就可以找到阻塞的具体方法,从这里看出是在调用一个 HTTP 请求,跟踪到代码,截图如下:
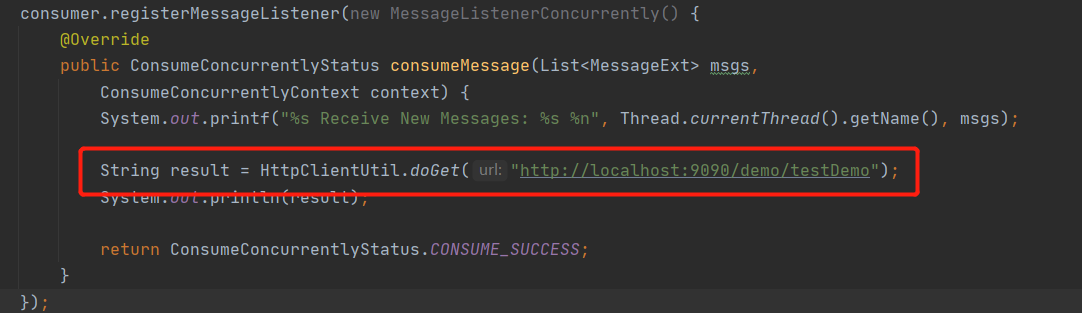
定位到代码后再定位问题就比较简单的,通常的网络调用需要设置超时时间,这里由于没有设置超时时间,导致一直在等待对端的返回,从而消息消费进度无法向前推进,解决方案:设置超时时间。
通常会造成线程阻塞的场景如下:
- HTTP 请求未设置超时时间
- 数据库查询慢查询导致查询时间过长,一条消息消费延时过高
线程栈分析经验
网上说分析线程栈,一般盯着 WAIT、Block、TIMEOUT_WAIT 等状态,其实不然,处于 RUNNABLE 状态的线程也不能忽略,因为 MySQL 的读写、HTTP 请求等网络读写,即在等待对端网络的返回数据时线程的状态是 RUNNABLE,并不是所谓的 BLOCK 状态。
如果处于下图所示的线程栈中的线程数量越多,说明消息消费端的处理能力很好,反而是拉取消息的速度跟不上消息消费的速度。

RocketMQ 消费端限流机制
RocketMQ 消息消费端会从 3 个维度进行限流:
- 消息消费端队列中积压的消息超过 1000 条
- 消息处理队列中尽管积压没有超过 1000 条,但最大偏移量与最小偏移量的差值超过 2000
- 消息处理队列中积压的消息总大小超过 100M
为了方便理解上述三条规则的设计理念,我们首先来看一下消费端的数据结构,如下图所示:
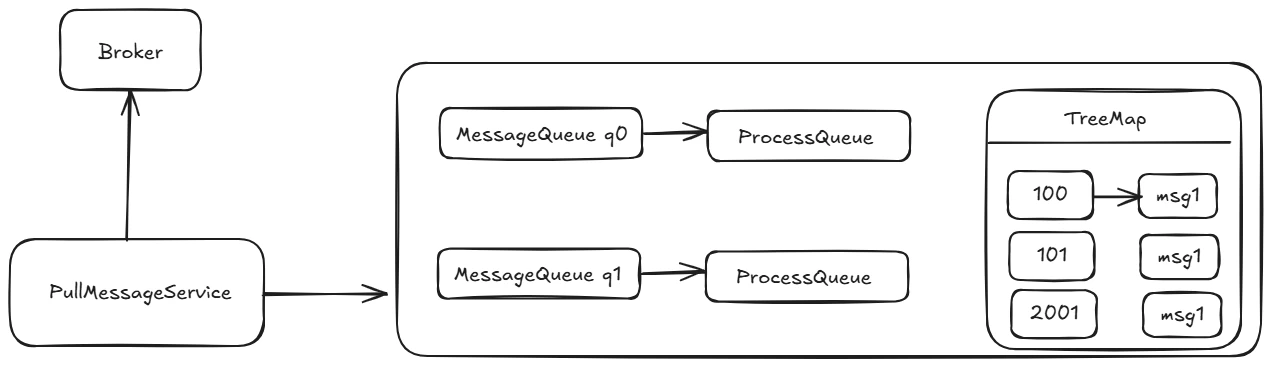
PullMessageService 线程会按照队列向 Broker 拉取一批消息,然后会存入到 ProcessQueue 队列中,即所谓的处理队列,然后再提交到消费端线程池中进行消息消费,消息消费完成后会将对应的消息从 ProcessQueue 中移除,然后向 Broker 端提交消费进度,提交的消费偏移量为 ProceeQueue 中的最小偏移量。
规则一:消息消费端队列中积压的消息超过 1000 条值的就是 ProcessQueue 中存在的消息条数超过指定值,默认为 1000 条,就触发限流,限流的具体做法就是暂停向 Broker 拉取该队列中的消息,但并不会阻止其他队列的消息拉取。例如如果 q0 中积压的消息超过 1000 条,但 q1 中积压的消息不足 1000,那 q1 队列中的消息会继续消费。其目的就是担心积压的消息太多,如果再继续拉取,会造成内存溢出。
规则二:消息在 ProcessQueue 中实际上维护的是一个 TreeMap,key 为消息的偏移量、vlaue 为消息对象,由于 TreeMap 本身是排序的,故很容易得出最大偏移量与最小偏移量的差值,即有可能存在处理队列中其实就只有 3 条消息,但偏移量确超过了 2000,例如如下图所示:
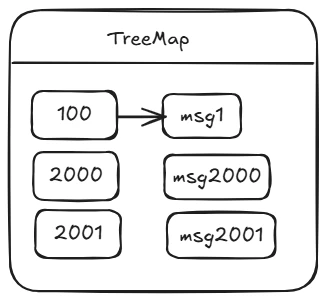
出现这种情况也是非常有可能的,其主要原因就是消费偏移量为 100 的这个线程由于某种情况卡主了(“阻塞”了),其他消息却能正常消费,这种情况虽然不会造成内存溢出,但大概率会造成大量消息重复消费,究其原因与消息消费进度的提交机制有关,在 RocketMQ 中,例如消息偏移量为 2001 的消息消费成功后,向服务端汇报消费进度时并不是报告 2001,而是取处理队列中最小偏移量 100,这样虽然消息一直在处理,但消息消费进度始终无法向前推进,试想一下如果此时最大的消息偏移量为 1000,项目组发现出现了消息积压,然后重启消费端,那消息就会从 100 开始重新消费,会造成大量消息重复消费,RocketMQ 为了避免出现大量消息重复消费,故对此种情况会对其进行限制,超过 2000 就不再拉取消息了。
规则三:消息处理队列中积压的消息总大小超过 100M。
这个就更加直接了,不仅从消息数量考虑,再结合从消息体大小考虑,处理队列中消息总大小超过 100M 进行限流,这个显而易见就是为了避免内存溢出。
在了解了 RocketMQ 消息限流规则后,会在 rocketmq_client.log 中输出相关的限流日志,具体搜索“so do flow control”,详细如下图所示:
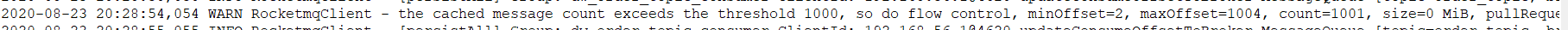
扩充消息队列
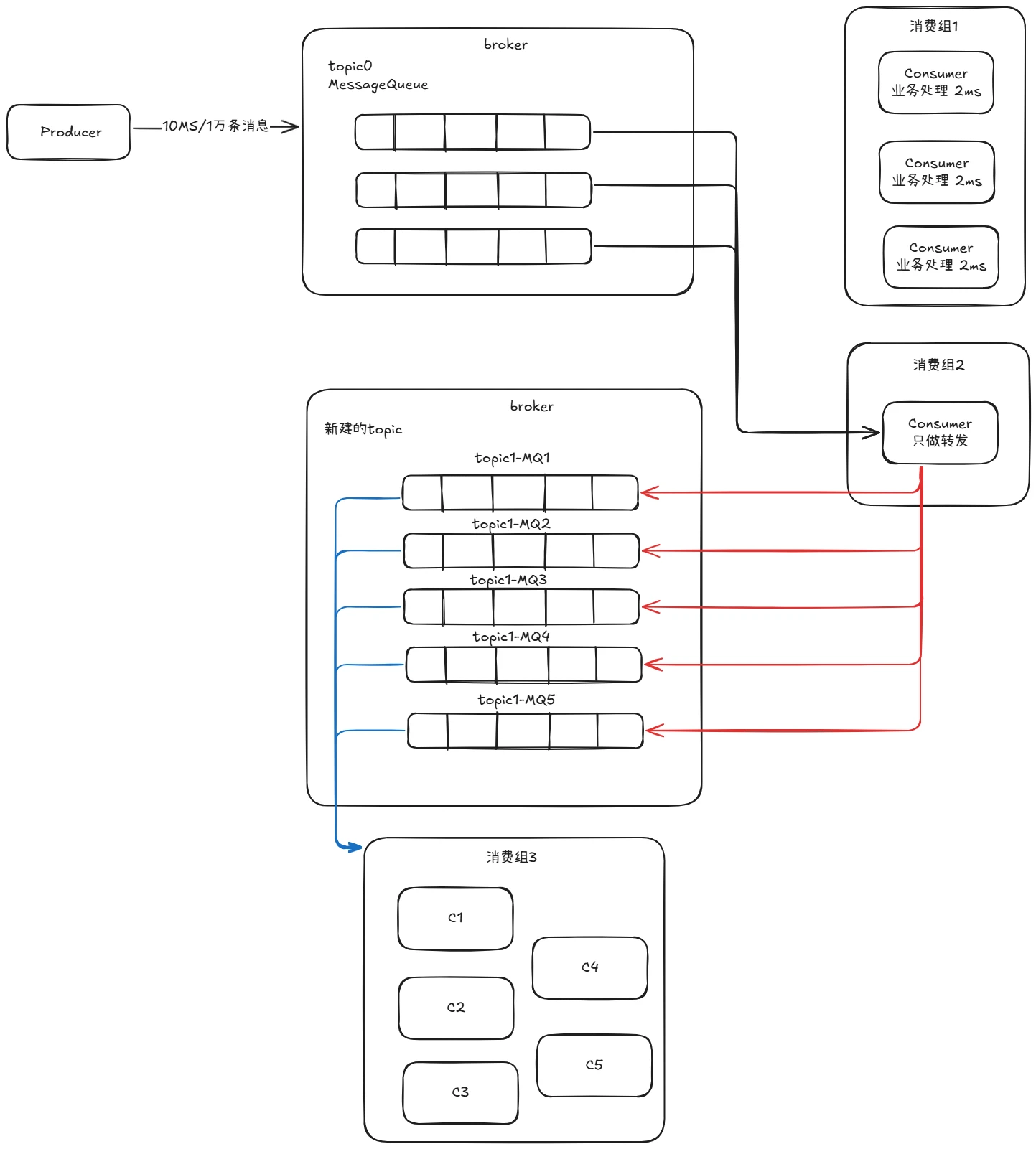
如果生产者在10ms内发送了一万条消息,大量的消息都被推送到了现有的消息队列里,导致消息堆积,扩充消息队列和增加消费者都不能将已经在队列里排队的消息迅速消费完,此时应该如何解决呢?
解决方式如下图所示,可以增加一个消费组2,里面只有一个用于转发消息的消费者,将现有的3个队列里的消息全部转发到另外几个新建的topic,并在broker内新建几个消息队列,新建一个专门用来消费积压消息的消费组3,配置相应的消费者来消费这些积压消息。