
RocketMQ存储方式探究
简介
首先,在RocketMQ管理页面手动创建一个Topic,配置如下图:
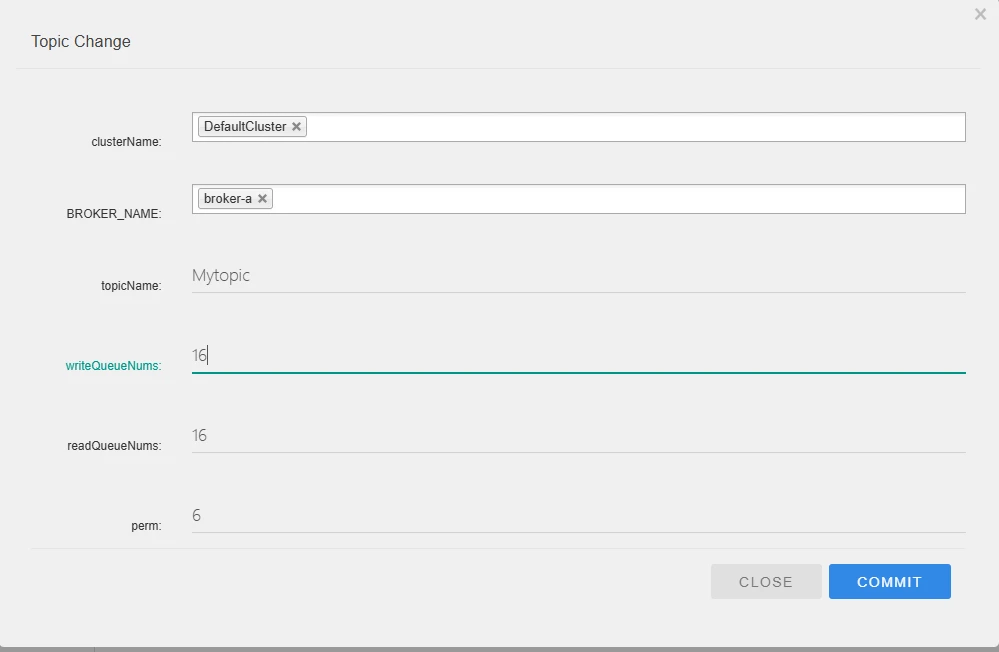
这里解释一下图中的几个参数:
writeQueueNums:客户端在发送消息时,可以向多少个队列进行发送;
readQueueNums:客户端在消费消息时,可以从多少个队列进行拉取;
perm:当前 Topic 读写权限,2 只允许读、4 只允许写、6 允许读写,默认是 6。
RocketMQ 主要有 3 个消息相关的文件:commitlog、consumequeue 和 index。
writeQueueNums 参数控制 consumequeue 的文件数量。往 MyTestTopic 这个 Topic 发送了 100 条消息,这些消息保存在了 commitlog 文件。而 consumequeue 文件如下:
1 | [root@xxx MyTestTopic]# pwd |
可以看到,consumequeue 的保存是在 consumequeue 目录下为每个 Topic 建一个目录,用保存这个 Topic 的 consumequeue 文件。consumequeue 文件为每个 Topic 基于偏移量创建了一个索引。
index 文件保存的是消息基于 key 的 HASH 索引。
commitlog
commitlog 是 RocketMQ 保存消息的文件,保存了消息主体以及元数据的存储主体 。commitlog 并没有按照 Topic 来分割,Broker单个实例下所有的队列的消息都写入同一个 commitlog。
为了追求高效写入,RocketMQ 使用了磁盘顺序写,所有主题的消息按顺序存储在同一个文件中。同时为了避免消息在消息存储服务器中无限地累积,引入了消息文件过期机制与文件存储空间报警机制。
commitlog 单个文件大小默认是1G,可以通过参数 mappedFileSizeCommitLog 来修改。
下面是服务器磁盘上保存的 commitlog 文件(文件大小 1G):
1 | [root@xxx commitlog]# pwd |
可以看到:commitlog 文件的命名以保存在文件中的消息最小的偏移量来命名的,后一个文件的名字是前一个文件名加文件大小。这样通过偏移量查找消息时可以先用二分查找找到消息所在的文件,然后通过偏移量减去文件名就可以方便地找到消息在文件中的物理地址,定位消息位于那个文件中,并获取到消息实体数据。
为了让 commitlog 操作效率更高,RocketMQ 使用了 mmap 将磁盘上日志文件映射到用户态的内存地址中,减少日志文件从磁盘到用户态内存之间的数据拷贝。代码如下:
1 | //AllocateMappedFileService 类 mmapOperation 方法 |
写入消息时,如果 isTransientStorePoolEnable 方法返回 true,则消息数据先写入堆外内存,然后异步线程把堆外内存数据刷到 PageCache,如果返回 false 则直接写入 PageCache。后面根据刷盘策略把 PageCache 中数据持久化到磁盘。如下图:
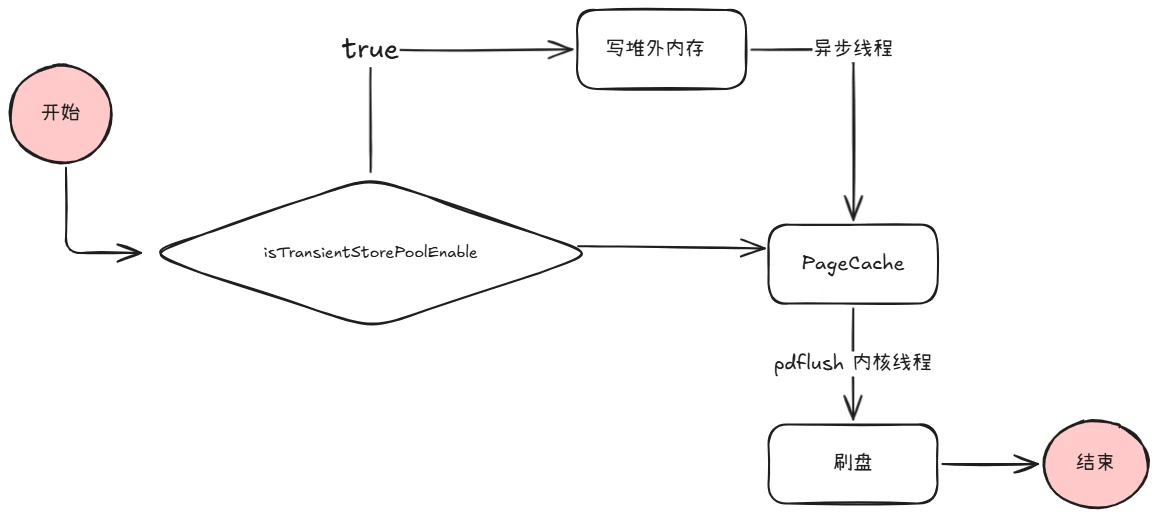
通常有如下两种方式进行读写:
- 第一种,Mmap+PageCache的方式,读写消息都走的是pageCache,这样子读写都在pagecache里面不可避免会有锁的问题,在并发的读写操作情况下,会出现缺页中断降低,内存加锁,污染页的回写。
- 第二种,DirectByteBuffer(堆外内存)+PageCache的两层架构方式,这样子可以实现读写消息分离,写入消息时候写到的是DirectByteBuffer——堆外内存中,读消息走的是PageCache(对于,DirectByteBuffer是两步刷盘,一步是刷到PageCache,还有一步是刷到磁盘文件中),带来的好处就是,避免了内存操作的很多容易堵的地方,降低了时延,比如说缺页中断降低,内存加锁,污染页的回写。
页缓存(PageCache)是OS对文件的缓存,用于加速对文件的读写。一般来说,程序对文件进行顺序读写的速度几乎接近于内存的读写速度,主要原因就是由于OS使用PageCache机制对读写访问操作进行了性能优化,将一部分的内存用作PageCache。对于数据的写入,OS会先写入至Cache内,随后通过异步的方式由pdflush内核线程将Cache内的数据刷盘至物理磁盘上。对于数据的读取,如果一次读取文件时出现未命中PageCache的情况,OS从物理磁盘上访问读取文件的同时,会顺序对其他相邻块的数据文件进行预读取。
无论先写堆外内存还是直接写 PageCache,文件数据都会映射到 MappedByteBuffer。如下图:
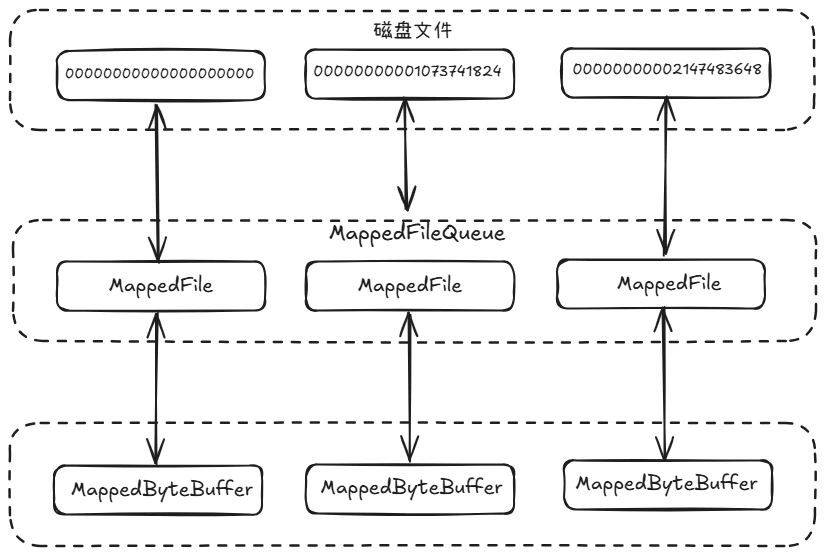
不同的是,如果消息先写入堆外内存,则 MappedByteBuffer 主要用来读消息,堆外内存用来写消息。这一定程度上实现了读写分离,减少 PageCache 写入压力。
再看一下文件映射的代码,如下:
1 | //MappedFile 类 |
这里使用了 Java 中 FileChannel 的 map 方法来实现 mmap。
有一个细节需要注意:创建 MappedFile 后会进行文件预热,目的是为了预先将 PageCache 加载到内存,防止读写数据发生缺页中断时再加载,影响性能。代码如下:
1 | //AllocateMappedFileService 类 mmapOperation 方法 |
RocketMQ主要通过MappedByteBuffer对文件进行读写操作。其中,利用了NIO中的FileChannel模型将磁盘上的物理文件直接映射到用户态的内存地址中,这种Mmap的方式减少了传统IO将磁盘文件数据在操作系统内核地址空间的缓冲区和用户应用程序地址空间的缓冲区之间来回进行拷贝的性能开销。将对文件的操作转化为直接对内存地址进行操作,从而极大地提高了文件的读写效率。正因为需要使用内存映射机制,故RocketMQ的文件存储都使用定长结构来存储,方便一次将整个文件映射至内存。
consumequeue
所有 Topic 的消息都写到同一个 commitlog 文件,如果直接在 commitlog 文件中查找消息,只能从文件头开始查找,肯定会很慢。因此 RocketMQ 引入了 consumequeue,基于 Topic 来保存偏移量。
consumequeue 的文件结构如下图:
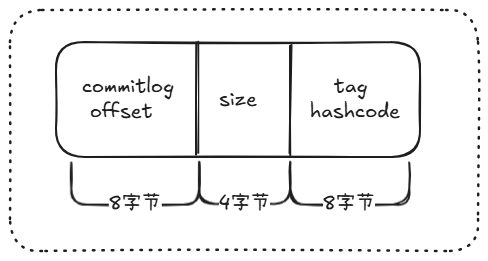
其中前 8 个字节保存消息在 commitlog 中的偏移量,中间 4 个字节保存消息消息大小,最后 8 个字节保存消息中 tag 的 hashcode。
这里为什么要保存一个 tag 的 hashcode 呢?
如果一个 Consumer 订阅了 TopicA 这个 Topic 中的 Tag1 和 Tag2 这两个 tag,那这个 Consumer 的订阅关系如下图:
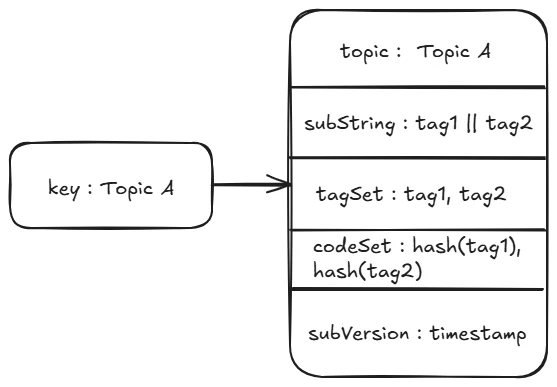
可以看到,订阅关系这个对象封装了 Topic、tag 以及所订阅 tag 的 hashcode 集合。
Consumer 发送拉取消息请求时,会把订阅关系传给 Broker(Broker 解析成 SubscriptionData 对象),Broker 使用 consumequeue 获取消息时,首先判断最后 8 个字节的 tag hashcode 是否在 SubscriptionData 的 codeSet 中,如果不在就跳过,如果存在就根据偏移量从 commitlog 中获取消息返回给 Consumer。如下图:
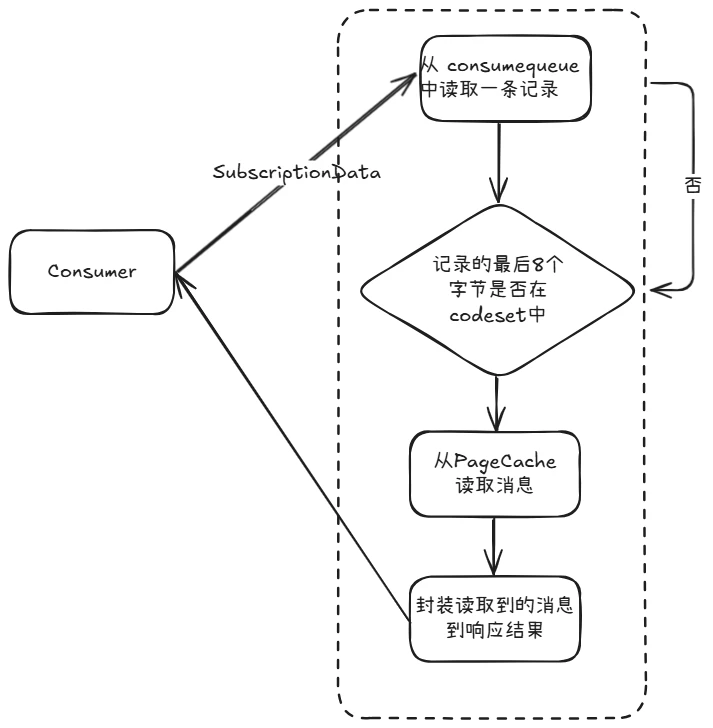
跟 commitlog 一样,consumequeue 也会使用 mmap 映射为 MappedFile 存储对象。
index
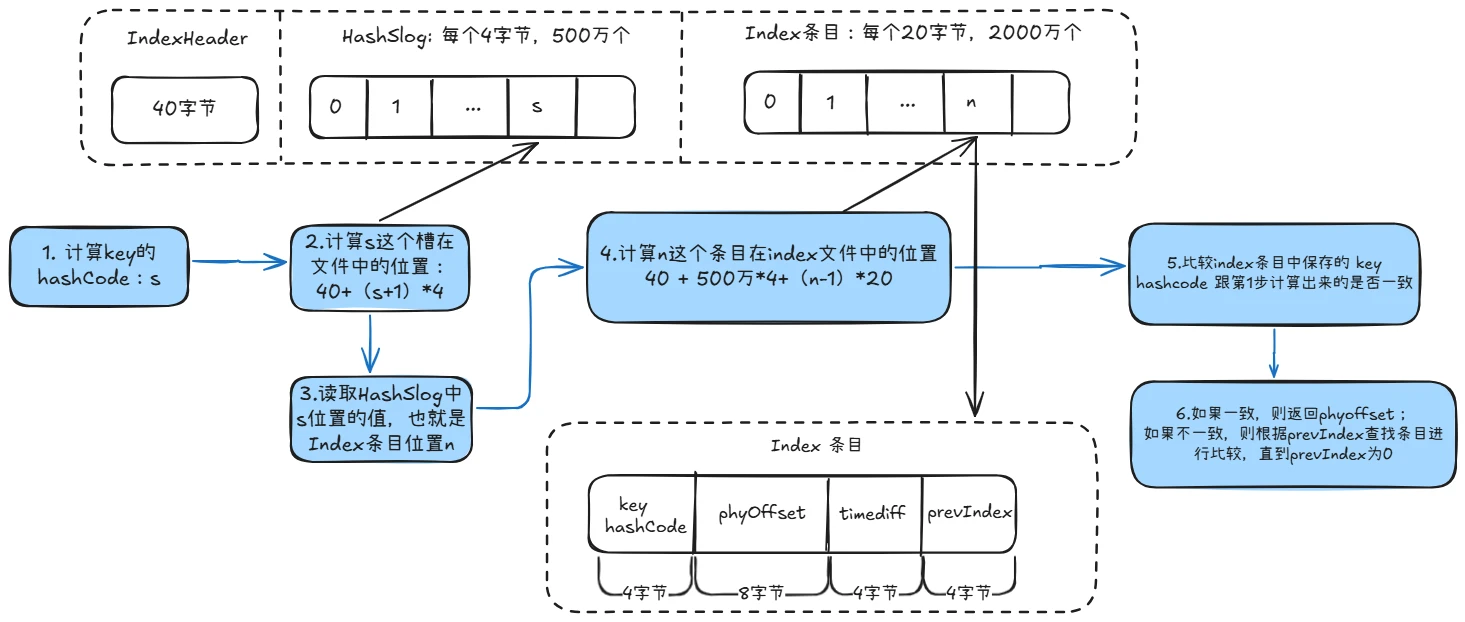
每个消息在业务层面的唯一标识码要设置到 keys 字段,方便将来定位消息丢失问题。服务器为每个消息创建哈希索引,应用可以通过 topic、key 来查询这条消息内容,以及消息被谁消费。为了支持按照消息的某一个属性来查询,RocketMQ 引入了 index 索引文件。index 文件结构如下图:
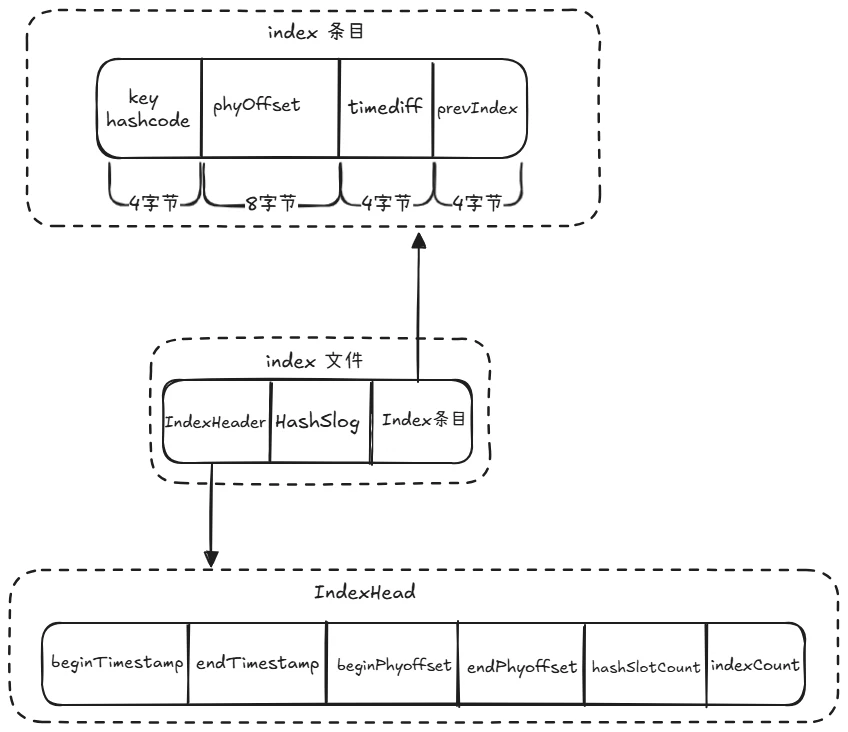
主要由三部分组成:IndexHeader、HashSlog 和 Index 条目。跟 commitlog 一样,Index 文件也会使用 mmap 映射为 MappedFile 存储对象。
IndexHeader
IndexHead 由如下 6 个属性组成,这些熟悉定义在类 IndexHeader:
1.beginTimestamp:index 文件中最小的消息存储时间;
2.endTimestamp:index 文件中最大的消息存储时间;
3.beginPhyoffset:index 文件中包含的消息中最小的 commitlog 偏移量;
4.endPhyoffset:index 文件中包含的消息中最大的 commitlog 偏移量;
5.hashSlotcount:index 文件中包含的 hash 槽的数量;
6.indexCount:index 文件中包含的 index 条目个数。
HashSlog
HashSlot 就是 Java HashMap 中的 hash 槽,默认有 500 万个。每个 HashSlot 使用 4 个字节 int 类型保存最后一个 Index 条目的位置。
为什么是保存的最后一个 index 条目呢?
因为 index 条目保存的是 key 的 hashcode,存在 hash 冲突的情况下,Hashslog 使用链表法解决,在 Index 条目中会保存相同 Hash 值的前一个条目位置。
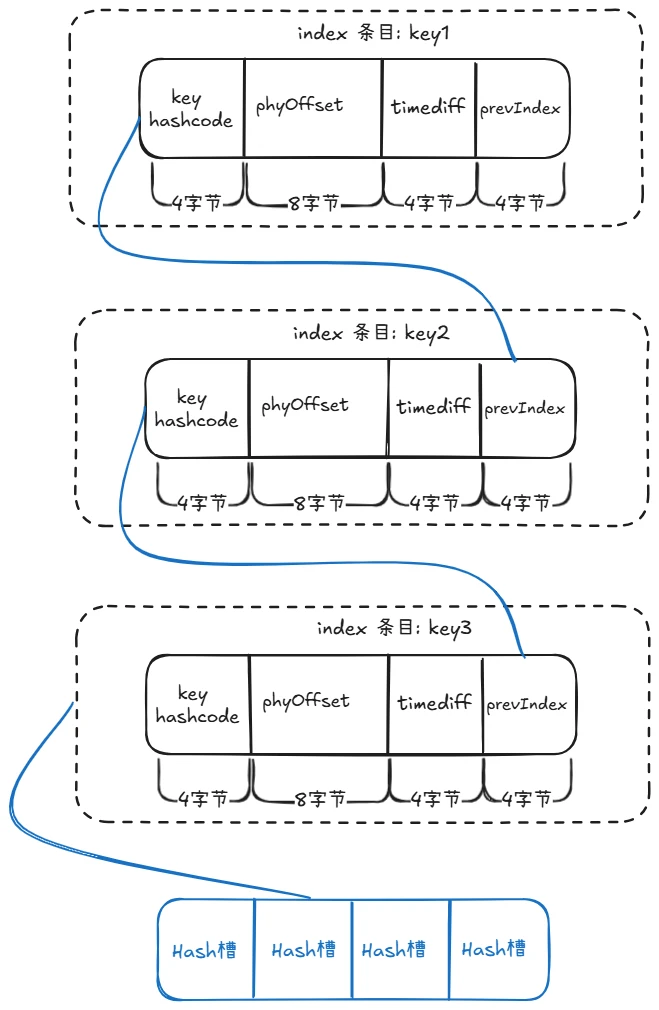
index 条目
index 条目录由 4 个属性组成:
1.key hashcode:要查找消息的 key 的 hashcode;
2.phyOffset:消息在 commitlog 文件中的物理偏移量;
3.timediff:该消息存储时间与 beginTimestamp 的差值。通过 key 查找消息时,在 key 相同的情况下,还要看 timediff 是否在区间范围内 ,不在时间范围内的就不返回,参考下面代码:
1 | //IndexFile 类 |
4.prevIndex:key 发生 hash 冲突后保存相同 hash code 的前一个 index 条目位置。
index 条目默认有 2000 万个。
查找过程
文件构建
consumequeue 和 index 文件的内容是什么时候写入呢?
在 MessageStore 初始化的时候会启动一个线程 ReputMessageService,这个线程的逻辑是死循环里面每个 1ms 执行一次,从 commitlog 中获取消息然后写入 consumequeue 和 index 文件。参考下面代码:
1 | //DefaultMessageStore 类 doReput 方法 |
1 | public void doDispatch(DispatchRequest req) { |
下面是 dispatcherList 的定义:
1 | this.dispatcherList = new LinkedList<>(); |
可以看到,即使 Broker 挂了,只要 commitlog 在,就可以重新构建出 consumequeue 和 index 文件。





