一键解标功能需求分析 需求说明:
1.明月AI标讯平台导航栏新增菜单“招标解读”
2.用户上传招标文件(<150页,且<10万字),文件类型限制为(docx、doc、pdf),上传完成AI输出招标文件分析结果(关键指标),每条分析结果支持反向定位到原始依据页面
3.新增招标解读Agent,后端调用该Agent获取招标文件的分析结果
4.新增招标解读历史记录模块,支持用户查询自己历史解读的标讯结果
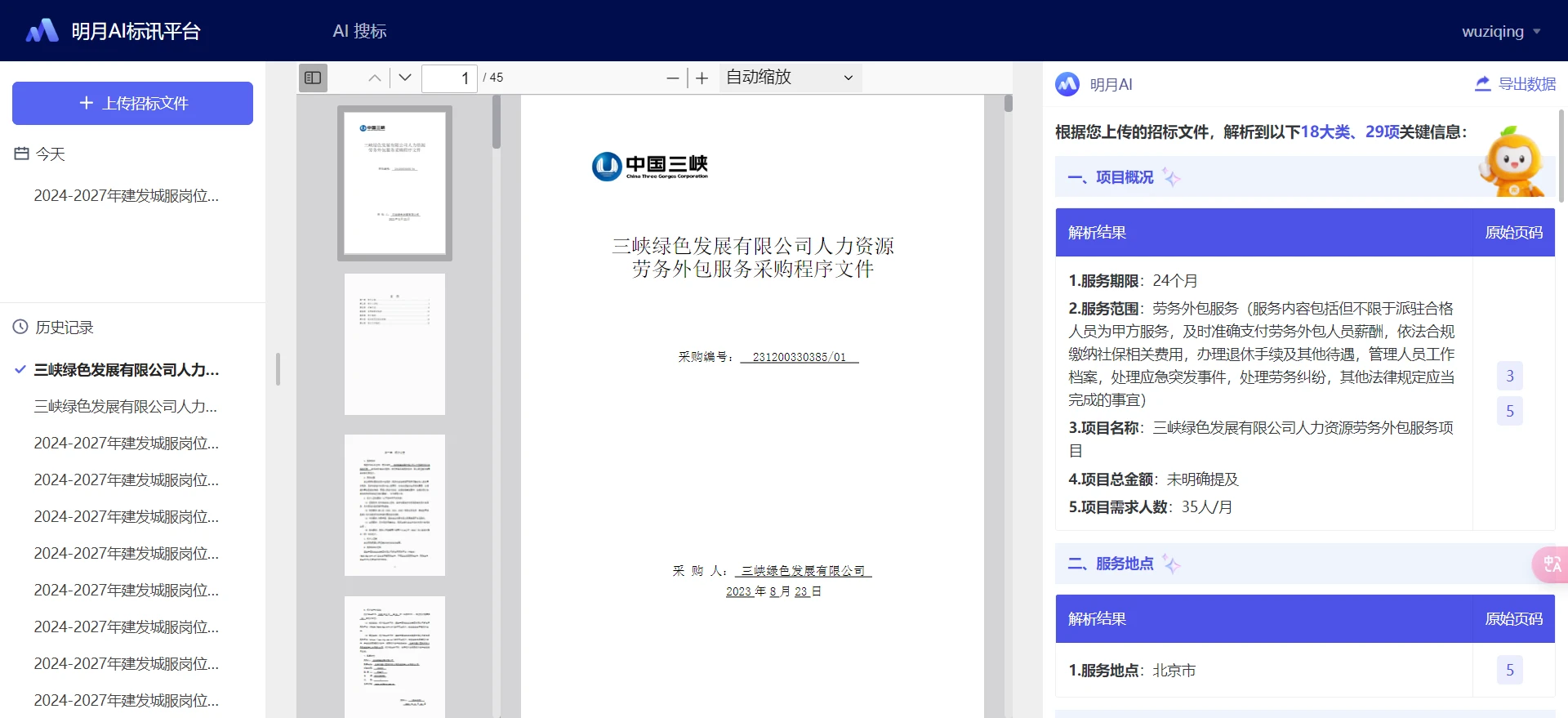
最终产品效果图:
表设计 招标文件解析表 1 2 3 4 5 6 7 8 9 10 11 12 13 14 CREATE TABLE `func_bid_doc_analysis` ( `id` int (11 ) NOT NULL AUTO_INCREMENT COMMENT '主键' , `file_name` varchar (255 ) DEFAULT NULL COMMENT '招标文件名称' , `file_url` varchar (2000 ) DEFAULT '' COMMENT '招标文件url' , `original_content` longtext COMMENT '招标文件原始文本' , `analyze_content` json DEFAULT NULL COMMENT '解析内容' , `md5` varchar (255 ) DEFAULT NULL COMMENT '文件md5' , `created_at` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间' , `created_by` varchar (255 ) NOT NULL DEFAULT '' COMMENT '创建用户' , `updated_at` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '修改时间' , `updated_by` varchar (255 ) NOT NULL DEFAULT '' COMMENT '修改用户' , `is_deleted` tinyint(1 ) DEFAULT '0' COMMENT '是否已删除:0-未删除,其他表示已删除' , PRIMARY KEY (`id`) USING BTREE ) ENGINE= InnoDB DEFAULT CHARSET= utf8mb4 COMMENT= '招标文件解析表' ;
接口功能设计 上传招标文件 前置校验:
文件不能为空
文件类型限制为(docx、doc、pdf)
招标文件(<150页,且<10万字)
若文件类型为 docx 或 doc ,转换为 pdf
将 pdf 文件上传到cos
新增到招标文件表
返回结果:文件id、文件名称、文件url
异常结果:
解析招标文件 Agent:参照已有的信息提取Agent,具体产品来写
前置校验:
按页提取 pdf 文件文本
标识页码,调用一键解标 Agent ,返回解析结果(原始依据包含页码)
更新解析内容到招标文件解读表
返回解析结果
异常结果:
查询该用户上传的招标文件列表 根据上传人查询招标文件表
校验是否是该登录用户的招标文件
返回结果:
文件id、文件名称、文件url、创建时间(按创建日期倒序)
查询该招标文件的解析结果 根据文件id查询招标文件表
校验:
返回解析结果
改进功能点 上文是初步的一个技术方案,在开发过程中,仍还有很多细节没有关注到,所以后面我们的重点放在如何对接口的功能设计进行改造上。
解析文件异步处理 最初的方案是前端做一个假的loading界面,调用解析文件接口,这个接口会同步返回解析结果。但是如果这时候,用户手动刷新了一下界面,前端调用的解析请求就没了,想要再次解析,只能手动发起。如果每次用户都在快解析结束的时候刷新,那调用 agent 的花销就是一笔大数目了。
综合前端、用户的体验,决定把解析文件的操作做异步处理。还有一个衍生的问题,产品认为流式传输比非流式要准确,所以建议我们后端接收流,把流式的结果拼接成完整的结果。
产品刚把 agent 写好,就提了这么些需求。而且更麻烦的是,产品需要我整合两个 agent 的信息。离上线还有一天,突然就得大改,内心慌得一批…
整理一下产品的需求:
解析文件修改为异步
调用流式API,拼接结果
等待两个 agent 结果,组装成 json 存入数据库
异步很好处理,使用 CompletableFuture 的 runAsync 方法,搞定。
1 CompletableFuture.runAsync(()->dealWithContent());
流式API需要就可以借助AI问问相关的API怎么用了
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 client.post() .uri(agentChatUrl) .contentType(MediaType.APPLICATION_JSON) .body(BodyInserters.fromValue(JSON.toJSONString(request))) .header(Constants.MOONAI_ACCOUNT_HEADER, userName) .header(Constants.AUTHORIZATION_HEADER, token).retrieve() .onStatus(HttpStatus::isError, response -> response.bodyToMono(Result.class) .flatMap(errorBody -> Mono.error(new MingYueAiException (errorBody.getCode(), errorBody.getMsg())))) .bodyToFlux(String.class) .doFinally((signalType) -> countDownLatch.countDown()) .subscribe(data -> { if (!"[DONE]" .equals(data)) { ChatCompletionChunk chunk = null ; try { chunk = objectMapper.readValue(data, ChatCompletionChunk.class); } catch (JsonProcessingException e) { throw new RuntimeException (e); } String content = chunk.getChoices().get(0 ).getMessage().getContent(); if (StringUtils.isNotEmpty(content)) { stringBuilder.append(content); } } }, error -> { isError.append("true" ); log.error("error:" , error); });
可以在 subscribe 里对 data 进行聚合,只要没有结束,就可以把 content 拿出来拼接。
至于等待两个流式调用的结果,上面的代码也体现了。在 doFinally 里使用 countDownLatch,确保两个agent都被调用,最后将两个 content 都放进 List 里,作为 json 存入数据库。
既然解析文件的操作都是异步的了,其实也没必要把上传和解析分为两个接口来实现了,一开始上传时就自动解析,前端轮询查询解析内容的接口,拿到解析内容结果,这是最稳妥的办法。因为上传文件还涉及到 word 转 pdf 的过程,可能会花费10秒,如果在这期间,用户点击到别的页面,那前端就永远拿不到返回值,也永远不会主动调用解析文件的接口了,在用户的视角看就是他所上传的招标文件一直在解析中。
幂等性问题 解析文件这一步确实是异步了,但是如果在解析的过程中,我疯狂点击这个解析的接口,那就会有很多个调用 agent 的方法,这样就花了很多不必要的钱。
我们可以定义一个 ConcurrentHashMap,key存储招标文件id,value存储当前时间。在每次解析前,我都去内存里判断当前时间和 value 的间隔有没有超过一分钟,如果在一分钟以内,限制它的提交。最后解析完,把这次的key移除掉,允许它再次解析。
1 this .CURRENT_ANALYSIS_DOC_MAP.put(funcBidDocAnalysis.getId(), System.currentTimeMillis());
为什么要对时间做限制呢?因为实际上我们是允许用户重新解析 的,如果解析内容有异常,在json里会有一个 isError 字段去标识,前端根据这个标识去给用户提供一个重新解析的按钮,后端也可以根据这个标识判断是否需要调用 agent。这样做比多加一个解析状态的字段要高效且简洁。
另外,我们还添加了一个文件md5的字段,约定了用户只要上传同一个招标文件,就可以复用其解析内容。用户体验上,可以无须等待就显示解析内容;产品花费上,对于同一个招标文件,可以少一次调用。
重新解析 发版上线了一段时间,突然有用户反馈说,点击页面上的“重新解析”不生效,赶紧看日志排查原因。
日志表明,该用户第一次异步解析,调用了 agent 失败了,他点击重新解析后,又调用失败了。他所看到的是点击“重新解析”后,页面没有任何变化,所以他反馈了这个问题。
确实,我们虽然允许用户重新解析了,但是重新解析的过程中,我们的页面没有任何变化,用户感知不到我们后台在重新解析。
这时候我们就和前端小伙伴看了这块逻辑,他说,一开始我们的解析内容为空,他就会在页面显示正在加载中,并轮询调用查询接口查解析内容,等待我们后端异步返回。所以,在重新解析的接口里,我们要先将这条标书文件的解析内容设置为空,更新数据库,并异步调用 agent。这样用户就能在页面直接感受到我们后台的运作了。
自定义typeHandler 解析内容实际上是聚合了两个 agent 的 json,为了存储方便,我们将两个 json 组装成一个 List, 以 json 的形式存入数据库中。那这就引发了一个新的问题,我们需要从数据库中查到解析内容,以 List 的形式返回给前端,且存入数据库时该字段为json。
一开始我是手动实现这一过程的,每次从数据库中查出来的解析内容,都被自动判定为 String 类型,所以我要手动转换成 JsonArray 的形式,再返回给前端 or 存入数据库,否则它会以字符串的形式返回/入库。
在这一步出过一次生产问题,因为逻辑删除的时候没有考虑到 String 转换的问题,删掉该文件后,顺便把解析内容篡改成了 String 类型,再次上传相同的文件,根据文件md5找到的解析内容(已经是篡改过的了),就没办法转换成 List 再入库了。紧急措施就是在删除接口查出来的解析内容设置为Null,这样更新的时候不会篡改掉原有的解析内容字段。
但是更优雅的做法是自定义 typeHandler。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 @MappedTypes(List.class) @MappedJdbcTypes(JdbcType.VARCHAR) public class JsonObjectListTypeHandler extends BaseTypeHandler <List<JSONObject>> { private static final ObjectMapper mapper = new ObjectMapper (); @Override public void setNonNullParameter (PreparedStatement ps, int i, List<JSONObject> parameter, JdbcType jdbcType) throws SQLException { try { String json = mapper.writeValueAsString(parameter); ps.setString(i, json); } catch (JsonProcessingException e) { throw new SQLException ("Error converting List<JSONObject> to json" ); } } @Override public List<JSONObject> getNullableResult (ResultSet rs, String columnName) throws SQLException { return parseJson(rs.getString(columnName)); } @Override public List<JSONObject> getNullableResult (ResultSet rs, int columnIndex) throws SQLException { return parseJson(rs.getString(columnIndex)); } @Override public List<JSONObject> getNullableResult (CallableStatement cs, int columnIndex) throws SQLException { return parseJson(cs.getString(columnIndex)); } private List<JSONObject> parseJson (String json) throws SQLException { try { if (StringUtils.isNotEmpty(json)){ return mapper.readValue(json, List.class); } return null ; } catch (JsonProcessingException e) { throw new SQLException ("Error converting json to List<JSONObject>" ); } } }
再在实体类加上注解(注意这都是必须添加上的,缺一不可)
1 2 3 4 5 6 7 8 9 @Data @TableName(value = "func_bid_doc_analysis",autoResultMap = true) public class FuncBidDocAnalysis implements Serializable { @TableField(typeHandler = JsonObjectListTypeHandler.class) private List<JSONObject> analyzeContent; }
总结 一个小小的需求,就涵盖了很多的技术要点。把功能实现很容易,难得是怎么把功能完善合理,节省花销,创造更大的收益,让用户体验更佳。很少做这种 to C 的需求,希望借此机会多积累点经验值。