xxl-job 的概念 诞生背景 我们在日常项目开发中,可能会用到分布式调度,在这期间我们可能会遇到这些问题:
同一个服务中可能存在多个互斥的任务,需要统一调度和协调。
定时任务运行期间,为了确保任务能够稳定运行,我们希望能够做到高可用、监控运维、故障告警。
需要统一管理和追踪个个服务节点定时任务的情况,以及任务属性信息,比如:任务所属服务、所属责任人等信息。
所以我们这里就需要用到xxl-job这个轻量级框架。
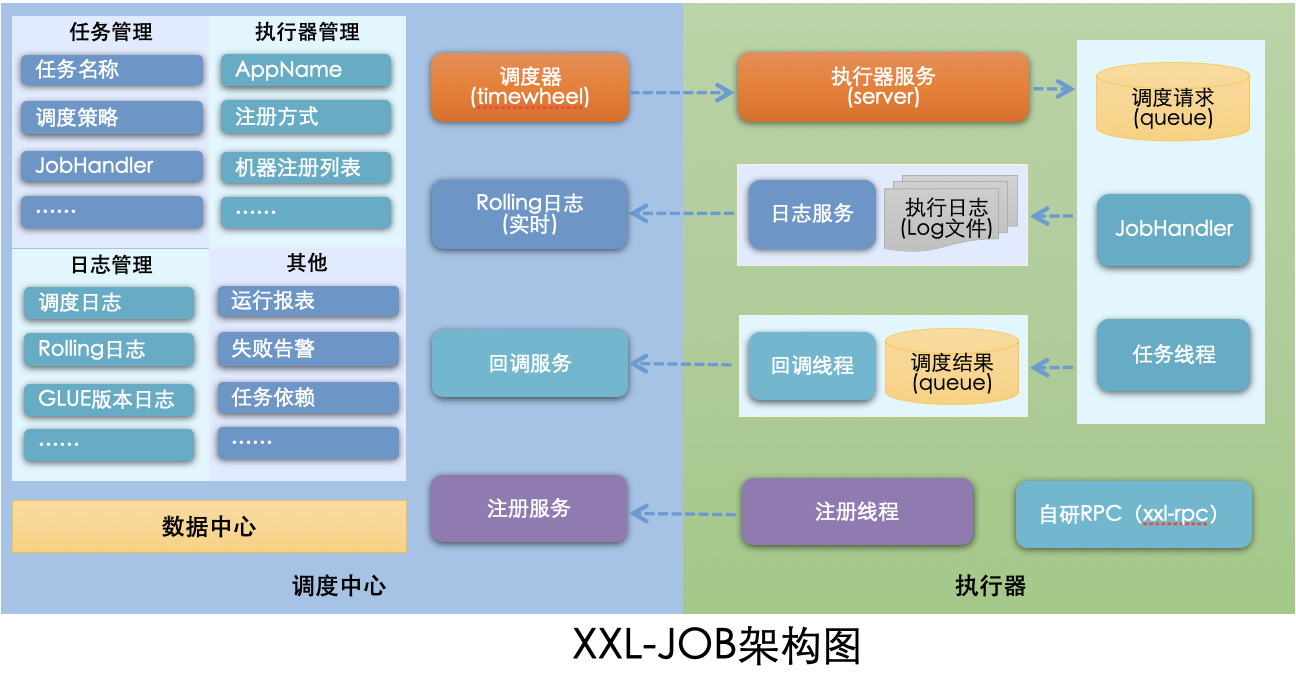
架构设计
调度模块(调度中心) :执行模块(执行器) :
这里放一张官网的系统架构图:
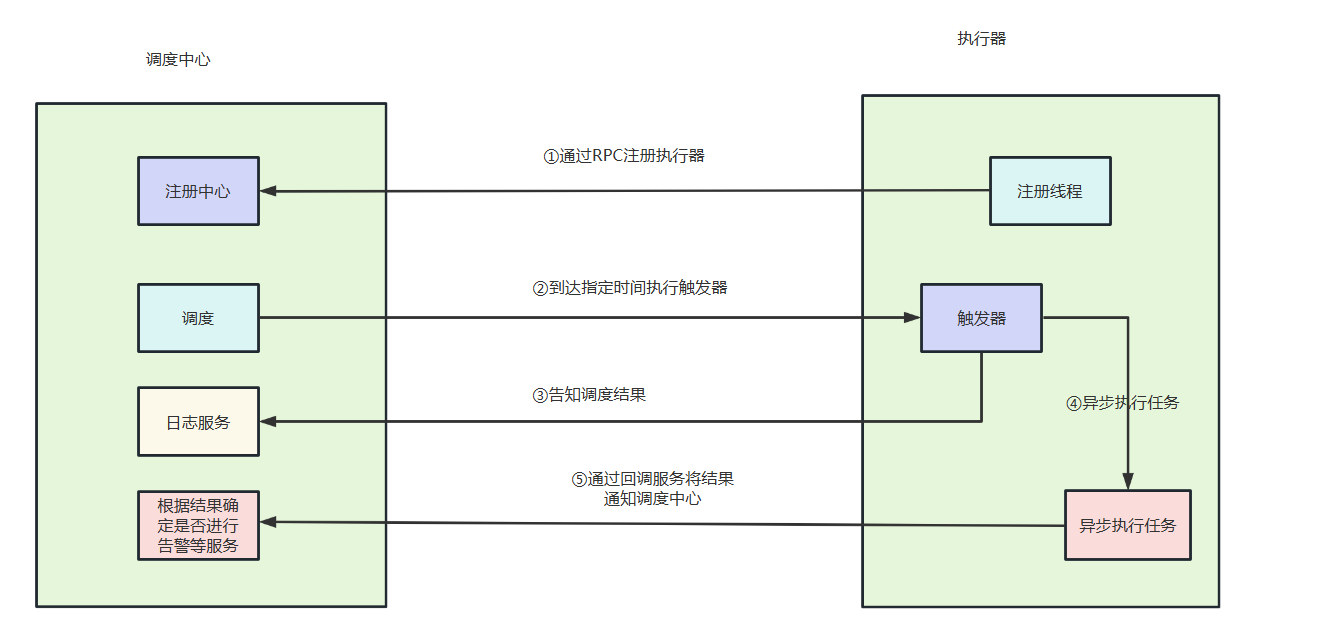
在真正了解 xxl-job 之前,可以带着以下的问题去进行系统性的学习:
执行器是如何自动注册到调度中心的?
调度中心是如何管理执行器的?
调度中心是如何触发任务的?
任务是怎么回调jobHandler的?
任务执行超时会有什么应对策略吗?
服务端启动流程
要想设计一个分布式任务调度中心,我们需要下面几个东西:
注册服务
RPC通信框架
调度服务
日志服务
告警服务
整体过程概述 在 xxl-job-admin 的 XxlJobAdminConfig 中,可以看到它在 bean 完成初始化之后通过 InitializingBean 进行了一些特殊操作。
它继承InitializingBean所实现的afterPropertiesSet方法执行了下面的操作。代码很简单创建一个调度器之后就调用init进行初始化。我们不妨查看init做了什么操作。
1 2 3 4 5 6 7 @Override public void afterPropertiesSet () throws Exception { adminConfig = this ; xxlJobScheduler = new XxlJobScheduler (); xxlJobScheduler.init(); }
步入了init我们看到了各种helper类的启动操作。从注释中我们也可以看出这些操作分别是:
初始化i18n。
JobTriggerPoolHelper这里面会完成一些线程池初始化的操作。
初始化注册监控相关,在这个操作里面,会每隔30秒进行一次注册表维护。
初始化失败处理监控器,对失败的情况进行监控,这里面会涉及一些失败发送邮箱或者重试的操作。
初始化任务完成器,将一些长时间没有响应的任务进行结束处理。
初始化报表统计,会进行一些成功失败的报表统计。
初始化调度器,执行任务调度处理。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 public void init () throws Exception { initI18n(); JobTriggerPoolHelper.toStart(); JobRegistryHelper.getInstance().start(); JobFailMonitorHelper.getInstance().start(); JobCompleteHelper.getInstance().start(); JobLogReportHelper.getInstance().start(); JobScheduleHelper.getInstance().start(); logger.info(">>>>>>>>> init xxl-job admin success." ); }
初始化触发器 我们先来看看JobTriggerPoolHelper.toStart();这段代码内部的逻辑,非常简单,无非就是初始化两个线程池,一个线程池是名为快触发线程池,另一个则是慢触发线程池。
从配置参数中我们可以看到这两个线程池的区别:
快线程池的最大线程数默认为200,慢线程池为100。
快线程池最多容纳1000个任务,慢线程池默认容纳2000个任务。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 public void start () { fastTriggerPool = new ThreadPoolExecutor ( 10 , XxlJobAdminConfig.getAdminConfig().getTriggerPoolFastMax(), 60L , TimeUnit.SECONDS, new LinkedBlockingQueue <Runnable>(1000 ), new ThreadFactory () { @Override public Thread newThread (Runnable r) { return new Thread (r, "xxl-job, admin JobTriggerPoolHelper-fastTriggerPool-" + r.hashCode()); } }); slowTriggerPool = new ThreadPoolExecutor ( 10 , XxlJobAdminConfig.getAdminConfig().getTriggerPoolSlowMax(), 60L , TimeUnit.SECONDS, new LinkedBlockingQueue <Runnable>(2000 ), new ThreadFactory () { @Override public Thread newThread (Runnable r) { return new Thread (r, "xxl-job, admin JobTriggerPoolHelper-slowTriggerPool-" + r.hashCode()); } }); }
问题来了,什么时候使用快触发线程池,什么时候使用慢触发线程池呢?
从添加触发器的代码中可以看到如果一分钟执行超过10次的任务就会通过 slowTriggerPool 执行,反之就通过 fastTriggerPool 执行。
这也是设计者执行的巧妙所在,将那些可以快速执行的任务放到快线程池中快速执行完成。
而将那些耗时且频繁的任务放到慢线程池中堆着慢慢消化,合理分配避免某些快任务因为慢任务而导致执行频率低下。
1 2 3 4 5 6 7 8 9 10 11 12 13 public void addTrigger (......) { ThreadPoolExecutor triggerPool_ = fastTriggerPool; AtomicInteger jobTimeoutCount = jobTimeoutCountMap.get(jobId); if (jobTimeoutCount!=null && jobTimeoutCount.get() > 10 ) { triggerPool_ = slowTriggerPool; } triggerPool_.execute(......) }
维护注册表信息 接下来就是 JobRegistryHelper 的start方法。
该方法首先会声明一个线程池,从语义上可以猜测出这个线程池是负责注册或者删除执行器的线程池。而且这个线程池的拒绝策略也很特殊,会将任务再次执行一遍。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 registryOrRemoveThreadPool = new ThreadPoolExecutor ( 2 , 10 , 30L , TimeUnit.SECONDS, new LinkedBlockingQueue <Runnable>(2000 ), new ThreadFactory () { @Override public Thread newThread (Runnable r) { return new Thread (r, "xxl-job, admin JobRegistryMonitorHelper-registryOrRemoveThreadPool-" + r.hashCode()); } }, new RejectedExecutionHandler () { @Override public void rejectedExecution (Runnable r, ThreadPoolExecutor executor) { r.run(); logger.warn(">>>>>>>>>>> xxl-job, registry or remove too fast, match threadpool rejected handler(run now)." ); } });
后续我们又会看到这样一个守护线程,它做的事情很简单:
将超过90s的注册器删除。
从xxl_job_registry查找出更新时间大于现在+90s的执行器,即可能是最新注册的执行器,以appname作为key,相关地址作为value并将其存放到appAddressMap中。
从appAddressMap取出所有appName对应的地址,更新xxl_job_group执行器地址列表,组装成 addressListStr生成一个group并将其保存到xxl_job_group表中。
休眠30s后继续1-3的操作。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 registryMonitorThread = new Thread (new Runnable () { @Override public void run () { while (!toStop) { try { List<XxlJobGroup> groupList = XxlJobAdminConfig.getAdminConfig().getXxlJobGroupDao().findByAddressType(0 ); if (groupList!=null && !groupList.isEmpty()) { List<Integer> ids = XxlJobAdminConfig.getAdminConfig().getXxlJobRegistryDao().findDead(RegistryConfig.DEAD_TIMEOUT, new Date ()); if (ids!=null && ids.size()>0 ) { XxlJobAdminConfig.getAdminConfig().getXxlJobRegistryDao().removeDead(ids); } HashMap<String, List<String>> appAddressMap = new HashMap <String, List<String>>(); List<XxlJobRegistry> list = XxlJobAdminConfig.getAdminConfig().getXxlJobRegistryDao().findAll(RegistryConfig.DEAD_TIMEOUT, new Date ()); if (list != null ) { for (XxlJobRegistry item: list) { if (RegistryConfig.RegistType.EXECUTOR.name().equals(item.getRegistryGroup())) { String appname = item.getRegistryKey(); List<String> registryList = appAddressMap.get(appname); if (registryList == null ) { registryList = new ArrayList <String>(); } if (!registryList.contains(item.getRegistryValue())) { registryList.add(item.getRegistryValue()); } appAddressMap.put(appname, registryList); } } } for (XxlJobGroup group: groupList) { List<String> registryList = appAddressMap.get(group.getAppname()); String addressListStr = null ; if (registryList!=null && !registryList.isEmpty()) { Collections.sort(registryList); StringBuilder addressListSB = new StringBuilder (); for (String item:registryList) { addressListSB.append(item).append("," ); } addressListStr = addressListSB.toString(); addressListStr = addressListStr.substring(0 , addressListStr.length()-1 ); } group.setAddressList(addressListStr); group.setUpdateTime(new Date ()); XxlJobAdminConfig.getAdminConfig().getXxlJobGroupDao().update(group); } } } catch (Exception e) { if (!toStop) { logger.error(">>>>>>>>>>> xxl-job, job registry monitor thread error:{}" , e); } } try { TimeUnit.SECONDS.sleep(RegistryConfig.BEAT_TIMEOUT); } catch (InterruptedException e) { if (!toStop) { logger.error(">>>>>>>>>>> xxl-job, job registry monitor thread error:{}" , e); } } } logger.info(">>>>>>>>>>> xxl-job, job registry monitor thread stop" ); } });
失败管理监视器 我们再来看看JobFailMonitorHelper的start代码。大体步骤为:
从xxl_job_log找到执行失败的任务。
lock log 将xxl_job_log表中这些任务alarm_status设置为-1,意为上锁,如果没锁成功下次循环继续上锁。
从xxl_job_log获取这些job的id。
根据xxl_job_log的id从xxl_job_info获取到这个任务的信息。
查看xxl_job_info失败的任务重试次数是否大于0,大于0则继续重试执行。
对于失败的任务,判断info是否为空,如果不为空,则进行告警,然后基于乐观锁更新xxl_job_log告警信息。
休眠10s,继续1-6的操作。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 monitorThread = new Thread (new Runnable () { @Override public void run () { while (!toStop) { try { List<Long> failLogIds = XxlJobAdminConfig.getAdminConfig().getXxlJobLogDao().findFailJobLogIds(1000 ); if (failLogIds!=null && !failLogIds.isEmpty()) { for (long failLogId: failLogIds) { int lockRet = XxlJobAdminConfig.getAdminConfig().getXxlJobLogDao().updateAlarmStatus(failLogId, 0 , -1 ); if (lockRet < 1 ) { continue ; } XxlJobLog log = XxlJobAdminConfig.getAdminConfig().getXxlJobLogDao().load(failLogId); XxlJobInfo info = XxlJobAdminConfig.getAdminConfig().getXxlJobInfoDao().loadById(log.getJobId()); if (log.getExecutorFailRetryCount() > 0 ) { JobTriggerPoolHelper.trigger(log.getJobId(), TriggerTypeEnum.RETRY, (log.getExecutorFailRetryCount()-1 ), log.getExecutorShardingParam(), log.getExecutorParam(), null ); String retryMsg = "<br><br><span style=\"color:#F39C12;\" > >>>>>>>>>>>" + I18nUtil.getString("jobconf_trigger_type_retry" ) +"<<<<<<<<<<< </span><br>" ; log.setTriggerMsg(log.getTriggerMsg() + retryMsg); XxlJobAdminConfig.getAdminConfig().getXxlJobLogDao().updateTriggerInfo(log); } int newAlarmStatus = 0 ; if (info != null ) { boolean alarmResult = XxlJobAdminConfig.getAdminConfig().getJobAlarmer().alarm(info, log); newAlarmStatus = alarmResult?2 :3 ; } else { newAlarmStatus = 1 ; } XxlJobAdminConfig.getAdminConfig().getXxlJobLogDao().updateAlarmStatus(failLogId, -1 , newAlarmStatus); } } } catch (Exception e) { if (!toStop) { logger.error(">>>>>>>>>>> xxl-job, job fail monitor thread error:{}" , e); } } try { TimeUnit.SECONDS.sleep(10 ); } catch (Exception e) { if (!toStop) { logger.error(e.getMessage(), e); } } } logger.info(">>>>>>>>>>> xxl-job, job fail monitor thread stop" ); } });
任务结束处理器 我们继续前进查看 JobCompleteHelper 的源码。第一步也还是创建一个回调线程池,参数如下,可以看到拒绝策略任然是再次执行任务。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 callbackThreadPool = new ThreadPoolExecutor ( 2 , 20 , 30L , TimeUnit.SECONDS, new LinkedBlockingQueue <Runnable>(3000 ), new ThreadFactory () { @Override public Thread newThread (Runnable r) { return new Thread (r, "xxl-job, admin JobLosedMonitorHelper-callbackThreadPool-" + r.hashCode()); } }, new RejectedExecutionHandler () { @Override public void rejectedExecution (Runnable r, ThreadPoolExecutor executor) { r.run(); logger.warn(">>>>>>>>>>> xxl-job, callback too fast, match threadpool rejected handler(run now)." ); } });
再往后查看代码,我们会发现一个守护线程monitorThread,查看它的核心工作代码如下,具体步骤为:
找到运行中状态超过10min的任务id。
拿着这个任务id组装出一个log对象
基于这个表对象将任务结果通过updateHandleInfoAndFinish设置为结束。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 while (!toStop) { try { Date losedTime = DateUtil.addMinutes(new Date (), -10 ); List<Long> losedJobIds = XxlJobAdminConfig.getAdminConfig().getXxlJobLogDao().findLostJobIds(losedTime); if (losedJobIds!=null && losedJobIds.size()>0 ) { for (Long logId: losedJobIds) { XxlJobLog jobLog = new XxlJobLog (); jobLog.setId(logId); jobLog.setHandleTime(new Date ()); jobLog.setHandleCode(ReturnT.FAIL_CODE); jobLog.setHandleMsg( I18nUtil.getString("joblog_lost_fail" ) ); XxlJobCompleter.updateHandleInfoAndFinish(jobLog); } } } catch (Exception e) { if (!toStop) { logger.error(">>>>>>>>>>> xxl-job, job fail monitor thread error:{}" , e); } } try { TimeUnit.SECONDS.sleep(60 ); } catch (Exception e) { if (!toStop) { logger.error(e.getMessage(), e); } } }
再来看看updateHandleInfoAndFinish的代码,逻辑也很简单,根据log对象的code值组装对应的msg到xxlJobLog中,然后更新到xxl_job_log表中。
1 2 3 4 5 6 7 8 9 10 11 12 13 public static int updateHandleInfoAndFinish (XxlJobLog xxlJobLog) { finishJob(xxlJobLog); if (xxlJobLog.getHandleMsg().length() > 15000 ) { xxlJobLog.setHandleMsg( xxlJobLog.getHandleMsg().substring(0 , 15000 ) ); } return XxlJobAdminConfig.getAdminConfig().getXxlJobLogDao().updateHandleInfo(xxlJobLog); }
报表处理 还记得我们登录xxl-job-admin时,哪个报表界面吗?这个页面的数据就是通过JobLogReportHelper进行处理的。对此,我们不妨打开源码一探究竟。
核心逻辑为:
获取今天、昨天、前天的任务总数、正在运行数、成功数,得出统计信息更新到表中。
查看日志保留天数,如果到期则将过期日志删除。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 while (!toStop) { try { for (int i = 0 ; i < 3 ; i++) { Calendar itemDay = Calendar.getInstance(); itemDay.add(Calendar.DAY_OF_MONTH, -i); itemDay.set(Calendar.HOUR_OF_DAY, 0 ); itemDay.set(Calendar.MINUTE, 0 ); itemDay.set(Calendar.SECOND, 0 ); itemDay.set(Calendar.MILLISECOND, 0 ); Date todayFrom = itemDay.getTime(); itemDay.set(Calendar.HOUR_OF_DAY, 23 ); itemDay.set(Calendar.MINUTE, 59 ); itemDay.set(Calendar.SECOND, 59 ); itemDay.set(Calendar.MILLISECOND, 999 ); Date todayTo = itemDay.getTime(); XxlJobLogReport xxlJobLogReport = new XxlJobLogReport (); xxlJobLogReport.setTriggerDay(todayFrom); xxlJobLogReport.setRunningCount(0 ); xxlJobLogReport.setSucCount(0 ); xxlJobLogReport.setFailCount(0 ); Map<String, Object> triggerCountMap = XxlJobAdminConfig.getAdminConfig().getXxlJobLogDao().findLogReport(todayFrom, todayTo); if (triggerCountMap!=null && triggerCountMap.size()>0 ) { int triggerDayCount = triggerCountMap.containsKey("triggerDayCount" )?Integer.valueOf(String.valueOf(triggerCountMap.get("triggerDayCount" ))):0 ; int triggerDayCountRunning = triggerCountMap.containsKey("triggerDayCountRunning" )?Integer.valueOf(String.valueOf(triggerCountMap.get("triggerDayCountRunning" ))):0 ; int triggerDayCountSuc = triggerCountMap.containsKey("triggerDayCountSuc" )?Integer.valueOf(String.valueOf(triggerCountMap.get("triggerDayCountSuc" ))):0 ; int triggerDayCountFail = triggerDayCount - triggerDayCountRunning - triggerDayCountSuc; xxlJobLogReport.setRunningCount(triggerDayCountRunning); xxlJobLogReport.setSucCount(triggerDayCountSuc); xxlJobLogReport.setFailCount(triggerDayCountFail); } int ret = XxlJobAdminConfig.getAdminConfig().getXxlJobLogReportDao().update(xxlJobLogReport); if (ret < 1 ) { XxlJobAdminConfig.getAdminConfig().getXxlJobLogReportDao().save(xxlJobLogReport); } } } catch (Exception e) { if (!toStop) { logger.error(">>>>>>>>>>> xxl-job, job log report thread error:{}" , e); } } if (XxlJobAdminConfig.getAdminConfig().getLogretentiondays()>0 && System.currentTimeMillis() - lastCleanLogTime > 24 *60 *60 *1000 ) { Calendar expiredDay = Calendar.getInstance(); expiredDay.add(Calendar.DAY_OF_MONTH, -1 * XxlJobAdminConfig.getAdminConfig().getLogretentiondays()); expiredDay.set(Calendar.HOUR_OF_DAY, 0 ); expiredDay.set(Calendar.MINUTE, 0 ); expiredDay.set(Calendar.SECOND, 0 ); expiredDay.set(Calendar.MILLISECOND, 0 ); Date clearBeforeTime = expiredDay.getTime(); List<Long> logIds = null ; do { logIds = XxlJobAdminConfig.getAdminConfig().getXxlJobLogDao().findClearLogIds(0 , 0 , clearBeforeTime, 0 , 1000 ); if (logIds!=null && logIds.size()>0 ) { XxlJobAdminConfig.getAdminConfig().getXxlJobLogDao().clearLog(logIds); } } while (logIds!=null && logIds.size()>0 ); lastCleanLogTime = System.currentTimeMillis(); } try { TimeUnit.MINUTES.sleep(1 ); } catch (Exception e) { if (!toStop) { logger.error(e.getMessage(), e); } } }
任务调度处理器(重点) 接下来就是xxl-job工作调度的核心源码 JobScheduleHelper,我们还是分两段来查看这其中的逻辑。先来看看第一段逻辑,这段逻辑是由 scheduleThread 这个守护线程处理的,它的逻辑主要是负责安排任务的执行时间的:
查出未来5s要执行的任务。
如果发现这个任务执行时间距离现在已经过期5s,则根据策略要么立即触发要么安排下次处理时间。
如果发现这个任务在过期时间小于5s要么现在立刻执行,要么安排下次一次执行时间,并将这个时间。
剩下的都是未过期即将被执行的任务则全部存到一个ringdata的线程安全map中,这个map以秒为key,所有这个时间点执行的任务构成的list为value。
将job的时间安排结果更新到xxl_job_info表中。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 scheduleThread = new Thread (new Runnable () { @Override public void run () { try { TimeUnit.MILLISECONDS.sleep(5000 - System.currentTimeMillis()%1000 ); } catch (InterruptedException e) { if (!scheduleThreadToStop) { logger.error(e.getMessage(), e); } } logger.info(">>>>>>>>> init xxl-job admin scheduler success." ); int preReadCount = (XxlJobAdminConfig.getAdminConfig().getTriggerPoolFastMax() + XxlJobAdminConfig.getAdminConfig().getTriggerPoolSlowMax()) * 20 ; while (!scheduleThreadToStop) { long start = System.currentTimeMillis(); Connection conn = null ; Boolean connAutoCommit = null ; PreparedStatement preparedStatement = null ; boolean preReadSuc = true ; try { conn = XxlJobAdminConfig.getAdminConfig().getDataSource().getConnection(); connAutoCommit = conn.getAutoCommit(); conn.setAutoCommit(false ); preparedStatement = conn.prepareStatement( "select * from xxl_job_lock where lock_name = 'schedule_lock' for update" ); preparedStatement.execute(); long nowTime = System.currentTimeMillis(); List<XxlJobInfo> scheduleList = XxlJobAdminConfig.getAdminConfig().getXxlJobInfoDao().scheduleJobQuery(nowTime + PRE_READ_MS, preReadCount); if (scheduleList!=null && scheduleList.size()>0 ) { for (XxlJobInfo jobInfo: scheduleList) { if (nowTime > jobInfo.getTriggerNextTime() + PRE_READ_MS) { logger.warn(">>>>>>>>>>> xxl-job, schedule misfire, jobId = " + jobInfo.getId()); MisfireStrategyEnum misfireStrategyEnum = MisfireStrategyEnum.match(jobInfo.getMisfireStrategy(), MisfireStrategyEnum.DO_NOTHING); if (MisfireStrategyEnum.FIRE_ONCE_NOW == misfireStrategyEnum) { JobTriggerPoolHelper.trigger(jobInfo.getId(), TriggerTypeEnum.MISFIRE, -1 , null , null , null ); logger.debug(">>>>>>>>>>> xxl-job, schedule push trigger : jobId = " + jobInfo.getId() ); } refreshNextValidTime(jobInfo, new Date ()); } else if (nowTime > jobInfo.getTriggerNextTime()) { JobTriggerPoolHelper.trigger(jobInfo.getId(), TriggerTypeEnum.CRON, -1 , null , null , null ); logger.debug(">>>>>>>>>>> xxl-job, schedule push trigger : jobId = " + jobInfo.getId() ); refreshNextValidTime(jobInfo, new Date ()); if (jobInfo.getTriggerStatus()==1 && nowTime + PRE_READ_MS > jobInfo.getTriggerNextTime()) { int ringSecond = (int )((jobInfo.getTriggerNextTime()/1000 )%60 ); pushTimeRing(ringSecond, jobInfo.getId()); refreshNextValidTime(jobInfo, new Date (jobInfo.getTriggerNextTime())); } } else { int ringSecond = (int )((jobInfo.getTriggerNextTime()/1000 )%60 ); pushTimeRing(ringSecond, jobInfo.getId()); refreshNextValidTime(jobInfo, new Date (jobInfo.getTriggerNextTime())); } } for (XxlJobInfo jobInfo: scheduleList) { XxlJobAdminConfig.getAdminConfig().getXxlJobInfoDao().scheduleUpdate(jobInfo); } } else { preReadSuc = false ; } } catch (Exception e) { if (!scheduleThreadToStop) { logger.error(">>>>>>>>>>> xxl-job, JobScheduleHelper#scheduleThread error:{}" , e); } } ........ });
接下来就是任务调度的逻辑了,这里的处理也很简单,从上文创建的rindData取出当前时间前2s的任务,然后提交到线程池中执行,避免没必要的延迟。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 ringThread = new Thread (new Runnable () { @Override public void run () { while (!ringThreadToStop) { try { TimeUnit.MILLISECONDS.sleep(1000 - System.currentTimeMillis() % 1000 ); } catch (InterruptedException e) { if (!ringThreadToStop) { logger.error(e.getMessage(), e); } } try { List<Integer> ringItemData = new ArrayList <>(); int nowSecond = Calendar.getInstance().get(Calendar.SECOND); for (int i = 0 ; i < 2 ; i++) { List<Integer> tmpData = ringData.remove( (nowSecond+60 -i)%60 ); if (tmpData != null ) { ringItemData.addAll(tmpData); } } logger.debug(">>>>>>>>>>> xxl-job, time-ring beat : " + nowSecond + " = " + Arrays.asList(ringItemData) ); if (ringItemData.size() > 0 ) { for (int jobId: ringItemData) { JobTriggerPoolHelper.trigger(jobId, TriggerTypeEnum.CRON, -1 , null , null , null ); } ringItemData.clear(); } } catch (Exception e) { if (!ringThreadToStop) { logger.error(">>>>>>>>>>> xxl-job, JobScheduleHelper#ringThread error:{}" , e); } } } logger.info(">>>>>>>>>>> xxl-job, JobScheduleHelper#ringThread stop" ); } });
客户端启动流程 基于配置类了解作业执行器 现在来探寻一下 xxl-job 客户端,源码项目在:xxl-job-executor-sample-springboot
要想了解spring boot项目,我们都可以从项目中的配置类中看到核心类或者操作,于是我们找到了XxlJobConfig。
XxlJobConfig有个方法xxlJobExecutor,这就是创建执行器的方法,可以看到这里面所作的操作非常简单,你拿着配置文件中配置文件中的adminAddresses、appname、address等各种信息创建一个执行器。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 @Bean public XxlJobSpringExecutor xxlJobExecutor () { logger.info(">>>>>>>>>>> xxl-job config init." ); XxlJobSpringExecutor xxlJobSpringExecutor = new XxlJobSpringExecutor (); xxlJobSpringExecutor.setAdminAddresses(adminAddresses); xxlJobSpringExecutor.setAppname(appname); xxlJobSpringExecutor.setAddress(address); xxlJobSpringExecutor.setIp(ip); xxlJobSpringExecutor.setPort(port); xxlJobSpringExecutor.setAccessToken(accessToken); xxlJobSpringExecutor.setLogPath(logPath); xxlJobSpringExecutor.setLogRetentionDays(logRetentionDays); return xxlJobSpringExecutor; }
上述appname、address等信息都是来自于配置文件中。
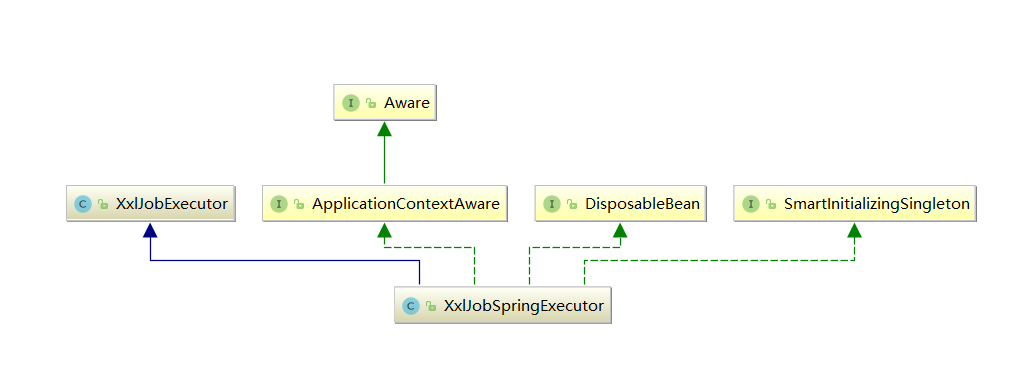
基于XxlJobSpringExecutor了解客户端初始化流程 从类图中我们不难看出它继承了和xxl-job相关的XxlJobExecutor以及一个和spring相关的SmartInitializingSingleton接口。
SmartInitializingSingleton的概念 该接口也是SpringBoot的一个扩展点,它会在spring将所有的单例bean初始化之后,执行afterSingletonsInstantiated这个方法。所以查看我们的XxlJobSpringExecutor这个方法实现。
可以看到这个类主要做了以下三件事:
初始化JobHandler的方法。
刷新GlueFactory这个工厂。
调用XxlJobExecutor的start方法。
基于afterSingletonsInstantiated了解执行器启动流程 初始化所有 JobHandler 方法 接下来我们开始了解每一个方法的具体逻辑,我们首先步入initJobHandlerMethodRepository(applicationContext);方法查看一下详情。
代码如下,具体含义笔者以及详细注释,整体来说分为3步:
获取spring容器中所有bean。
过滤出懒加载的bean。
看看这个bean的方法是否包含XxlJob这个注解。
将带有XxlJob注解的方法注册到xxl-job-admin上。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 private void initJobHandlerMethodRepository (ApplicationContext applicationContext) { if (applicationContext == null ) { return ; } String[] beanDefinitionNames = applicationContext.getBeanNamesForType(Object.class, false , true ); for (String beanDefinitionName : beanDefinitionNames) { Object bean = null ; Lazy onBean = applicationContext.findAnnotationOnBean(beanDefinitionName, Lazy.class); if (onBean!=null ){ logger.debug("xxl-job annotation scan, skip @Lazy Bean:{}" , beanDefinitionName); continue ; }else { bean = applicationContext.getBean(beanDefinitionName); } Map<Method, XxlJob> annotatedMethods = null ; try { annotatedMethods = MethodIntrospector.selectMethods(bean.getClass(), new MethodIntrospector .MetadataLookup<XxlJob>() { @Override public XxlJob inspect (Method method) { return AnnotatedElementUtils.findMergedAnnotation(method, XxlJob.class); } }); } catch (Throwable ex) { logger.error("xxl-job method-jobhandler resolve error for bean[" + beanDefinitionName + "]." , ex); } if (annotatedMethods==null || annotatedMethods.isEmpty()) { continue ; } for (Map.Entry<Method, XxlJob> methodXxlJobEntry : annotatedMethods.entrySet()) { Method executeMethod = methodXxlJobEntry.getKey(); XxlJob xxlJob = methodXxlJobEntry.getValue(); registJobHandler(xxlJob, bean, executeMethod); } } }
刷新GlueFactory 我们继续查看refreshInstance方法,没有什么特殊逻辑,无非是将glueFactory 指向一个全新的工厂而已。最终代码会new SpringGlueFactory();
1 2 3 4 5 6 7 public static void refreshInstance (int type) { if (type == 0 ) { glueFactory = new GlueFactory (); } else if (type == 1 ) { glueFactory = new SpringGlueFactory (); } }
了解XxlJobExecutor的start方法(重点) 终于我们来到的最核心的不妨,在XxlJobSpringExecutor的afterSingletonsInstantiated中调用了一个super.start();,这个super就是我们的XxlJobExecutor,具体逻辑如下。
可以看到它整体分为以下几个步骤:
初始化日志文件存放路径。
初始化xxl-job-admin地址列表。
初始化过期日志文件清理线程。
初始化回调结果通知xxl-job-admin线程。
初始化 executor-server监听调度器的请求器。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 public void start () throws Exception { XxlJobFileAppender.initLogPath(logPath); initAdminBizList(adminAddresses, accessToken); JobLogFileCleanThread.getInstance().start(logRetentionDays); TriggerCallbackThread.getInstance().start(); initEmbedServer(address, ip, port, appname, accessToken); }
XxlJobExecutor的start方法流程详解 初始化日志 首先是initLogPath方法,逻辑其实很简单就是通过配置文件获取路径然后进行拼接,最后设置到glueSrcPath 中。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 private static String logBasePath = "/data/applogs/xxl-job/jobhandler" ; private static String glueSrcPath = logBasePath.concat("/gluesource" ); public static void initLogPath (String logPath) { if (logPath!=null && logPath.trim().length()>0 ) { logBasePath = logPath; } File logPathDir = new File (logBasePath); if (!logPathDir.exists()) { logPathDir.mkdirs(); } logBasePath = logPathDir.getPath(); File glueBaseDir = new File (logPathDir, "gluesource" ); if (!glueBaseDir.exists()) { glueBaseDir.mkdirs(); } glueSrcPath = glueBaseDir.getPath(); }
初始化 admin 地址 然后是initAdminBizList方法,逻辑也很简单,将我们的配置文件中配置的adminAddresses通过逗号进行切割,然后存放到adminBizList中。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 private static List<AdminBiz> adminBizList; private void initAdminBizList (String adminAddresses, String accessToken) throws Exception { if (adminAddresses!=null && adminAddresses.trim().length()>0 ) { for (String address: adminAddresses.trim().split("," )) { if (address!=null && address.trim().length()>0 ) { AdminBiz adminBiz = new AdminBizClient (address.trim(), accessToken); if (adminBizList == null ) { adminBizList = new ArrayList <AdminBiz>(); } adminBizList.add(adminBiz); } } } }
清除过期日志 该方法时JobLogFileCleanThread的start方法,逻辑比较长,我们分为两段来说
首先判断日志保留天数,这个logRetentionDays 的值是从配置文件中来的,如果发现小于3天则直接返回。
1 2 3 4 if (logRetentionDays < 3 ) { return ; }
然后这个方法创建了一个localThread线程,其run方法核心逻辑如下:
得到所有文件位置。
算出今天的时间。
计算出这个文件的时间。
如果创建时间至今超过logRetentionDays (这里配置为30天),则将通过递归的方式删除这些日志文件。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 while (!toStop) { try { File[] childDirs = new File (XxlJobFileAppender.getLogPath()).listFiles(); if (childDirs!=null && childDirs.length>0 ) { Calendar todayCal = Calendar.getInstance(); todayCal.set(Calendar.HOUR_OF_DAY,0 ); todayCal.set(Calendar.MINUTE,0 ); todayCal.set(Calendar.SECOND,0 ); todayCal.set(Calendar.MILLISECOND,0 ); Date todayDate = todayCal.getTime(); for (File childFile: childDirs) { if (!childFile.isDirectory()) { continue ; } if (childFile.getName().indexOf("-" ) == -1 ) { continue ; } Date logFileCreateDate = null ; try { SimpleDateFormat simpleDateFormat = new SimpleDateFormat ("yyyy-MM-dd" ); logFileCreateDate = simpleDateFormat.parse(childFile.getName()); } catch (ParseException e) { logger.error(e.getMessage(), e); } if (logFileCreateDate == null ) { continue ; } if ((todayDate.getTime()-logFileCreateDate.getTime()) >= logRetentionDays * (24 * 60 * 60 * 1000 ) ) { FileUtil.deleteRecursively(childFile); } } } } catch (Exception e) { if (!toStop) { logger.error(e.getMessage(), e); } } try { TimeUnit.DAYS.sleep(1 ); } catch (InterruptedException e) { if (!toStop) { logger.error(e.getMessage(), e); } } }
初始化回调线程回调结果给admin 继续查看start方法中TriggerCallbackThread的start,我们查看其run方法,它的主要作用是将当前任务的执行结果告诉给xxl-job-admin,步骤也很简单:
从队列中取出一个任务的执行结果HandleCallbackParam。
将结果存到callbackParamList中。
调用doCallback将结果发送给xxl-job-admin。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 while (!toStop){ try { HandleCallbackParam callback = getInstance().callBackQueue.take(); if (callback != null ) { List<HandleCallbackParam> callbackParamList = new ArrayList <HandleCallbackParam>(); int drainToNum = getInstance().callBackQueue.drainTo(callbackParamList); callbackParamList.add(callback); if (callbackParamList!=null && callbackParamList.size()>0 ) { doCallback(callbackParamList); } } } catch (Exception e) { if (!toStop) { logger.error(e.getMessage(), e); } } }
查看doCallback的实现细节,它的工作过程也很简单,遍历出对应的xxl-job实例,发送结果某一个发送失败,则遍历下一个实例继续发送,直到成功为止。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 private void doCallback (List<HandleCallbackParam> callbackParamList) { boolean callbackRet = false ; for (AdminBiz adminBiz: XxlJobExecutor.getAdminBizList()) { try { ReturnT<String> callbackResult = adminBiz.callback(callbackParamList); if (callbackResult!=null && ReturnT.SUCCESS_CODE == callbackResult.getCode()) { callbackLog(callbackParamList, "<br>----------- xxl-job job callback finish." ); callbackRet = true ; break ; } else { callbackLog(callbackParamList, "<br>----------- xxl-job job callback fail, callbackResult:" + callbackResult); } } catch (Exception e) { callbackLog(callbackParamList, "<br>----------- xxl-job job callback error, errorMsg:" + e.getMessage()); } } if (!callbackRet) { appendFailCallbackFile(callbackParamList); } }
注册内嵌服务等待服务端调用(重点) 到了最关键的一步initEmbedServer(address, ip, port, appname, accessToken);,这一步就是可以确保我们的执行器可以收到调度器的关键所在。 它的工作流程就是组装端口等参数,通过netty的方式将服务开启并等待调度器的调用。现在不妨我们自顶向下查看一下它的实现细节。
从调用我们可以看到它的步骤也很清晰:
获取端口号以及ip地址。于端口号和ip地址组装服务地址。
获取token。
基于上述所有参数调用embedServer的start启动内嵌服务。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 private void initEmbedServer (String address, String ip, int port, String appname, String accessToken) throws Exception { port = port>0 ?port: NetUtil.findAvailablePort(9999 ); ip = (ip!=null &&ip.trim().length()>0 )?ip: IpUtil.getIp(); if (address==null || address.trim().length()==0 ) { String ip_port_address = IpUtil.getIpPort(ip, port); address = "http://{ip_port}/" .replace("{ip_port}" , ip_port_address); } if (accessToken==null || accessToken.trim().length()==0 ) { logger.warn(">>>>>>>>>>> xxl-job accessToken is empty. To ensure system security, please set the accessToken." ); } embedServer = new EmbedServer (); embedServer.start(address, port, appname, accessToken); }
了解了整体流程之后,我们再来看看细节。即embedServer的start的具体实现。
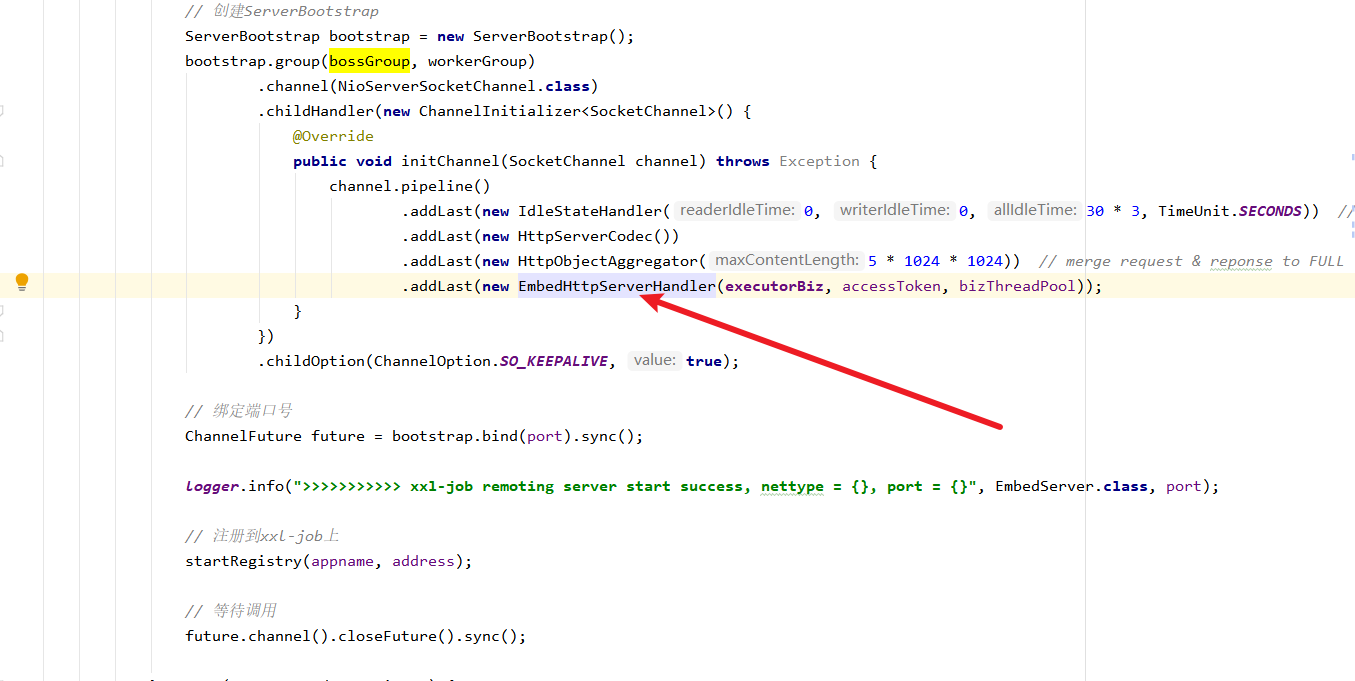
我们步入start方法会看到一个名为thread的线程,代码比较长,我们分段来解读。首先它会创建两个NIO group。然后再创建一个业务线程池,初始为0,最大线程数为200,队列中可以容纳2000个任务。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 EventLoopGroup bossGroup = new NioEventLoopGroup (); EventLoopGroup workerGroup = new NioEventLoopGroup (); ThreadPoolExecutor bizThreadPool = new ThreadPoolExecutor ( 0 , 200 , 60L , TimeUnit.SECONDS, new LinkedBlockingQueue <Runnable>(2000 ), new ThreadFactory () { @Override public Thread newThread (Runnable r) { return new Thread (r, "xxl-job, EmbedServer bizThreadPool-" + r.hashCode()); } }, new RejectedExecutionHandler () { @Override public void rejectedExecution (Runnable r, ThreadPoolExecutor executor) { throw new RuntimeException ("xxl-job, EmbedServer bizThreadPool is EXHAUSTED!" ); } });
基于上述的参数启动ServerBootstrap,并将配置文件中appName和当前应用地址信息作为参数,将服务注册到xxl-job-admin上。然后就是调用 future.channel().closeFuture().sync()等待调度器调用了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 ServerBootstrap bootstrap = new ServerBootstrap (); bootstrap.group(bossGroup, workerGroup) .channel(NioServerSocketChannel.class) .childHandler(new ChannelInitializer <SocketChannel>() { @Override public void initChannel (SocketChannel channel) throws Exception { channel.pipeline() .addLast(new IdleStateHandler (0 , 0 , 30 * 3 , TimeUnit.SECONDS)) .addLast(new HttpServerCodec ()) .addLast(new HttpObjectAggregator (5 * 1024 * 1024 )) .addLast(new EmbedHttpServerHandler (executorBiz, accessToken, bizThreadPool)); } }) .childOption(ChannelOption.SO_KEEPALIVE, true ); ChannelFuture future = bootstrap.bind(port).sync(); logger.info(">>>>>>>>>>> xxl-job remoting server start success, nettype = {}, port = {}" , EmbedServer.class, port); startRegistry(appname, address); future.channel().closeFuture().sync();
上文提到一个注册服务到xxl-job-admin的操作,我们查看startRegistry源码,我们查看其内部源码也是基于一个线程的带有while循环的run方法来实现的,核心逻辑如下,很简单,获取xxl-job-admin实例,调用其注册方法将当前服务注册上去,如果成功就结束循环,如果失败就遍历其他实例继续尝试注册,这一点和上文的回调处理器工作流程差不多。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 RegistryParam registryParam = new RegistryParam (RegistryConfig.RegistType.EXECUTOR.name(), appname, address); for (AdminBiz adminBiz: XxlJobExecutor.getAdminBizList()) { try { ReturnT<String> registryResult = adminBiz.registry(registryParam); if (registryResult!=null && ReturnT.SUCCESS_CODE == registryResult.getCode()) { registryResult = ReturnT.SUCCESS; logger.debug(">>>>>>>>>>> xxl-job registry success, registryParam:{}, registryResult:{}" , new Object []{registryParam, registryResult}); break ; } else { logger.info(">>>>>>>>>>> xxl-job registry fail, registryParam:{}, registryResult:{}" , new Object []{registryParam, registryResult}); } } catch (Exception e) { logger.info(">>>>>>>>>>> xxl-job registry error, registryParam:{}" , registryParam, e); } }
上述操作完成之后,线程会休眠30s,然后继续向xxl-job-admin注册当前服务信息,起到一个保持心跳的作用。自此我们的客户端启动流程就结束了。
1 2 3 4 5 6 7 8 9 10 try { if (!toStop) { TimeUnit.SECONDS.sleep(RegistryConfig.BEAT_TIMEOUT); } } catch (InterruptedException e) { if (!toStop) { logger.warn(">>>>>>>>>>> xxl-job, executor registry thread interrupted, error msg:{}" , e.getMessage()); } }
EmbedHttpServerHandler详解 还记得我们上文注册内嵌服务时候的逻辑吗?这一步中它们组装了一个处理器,这个就是处理调度器请求的核心所在。
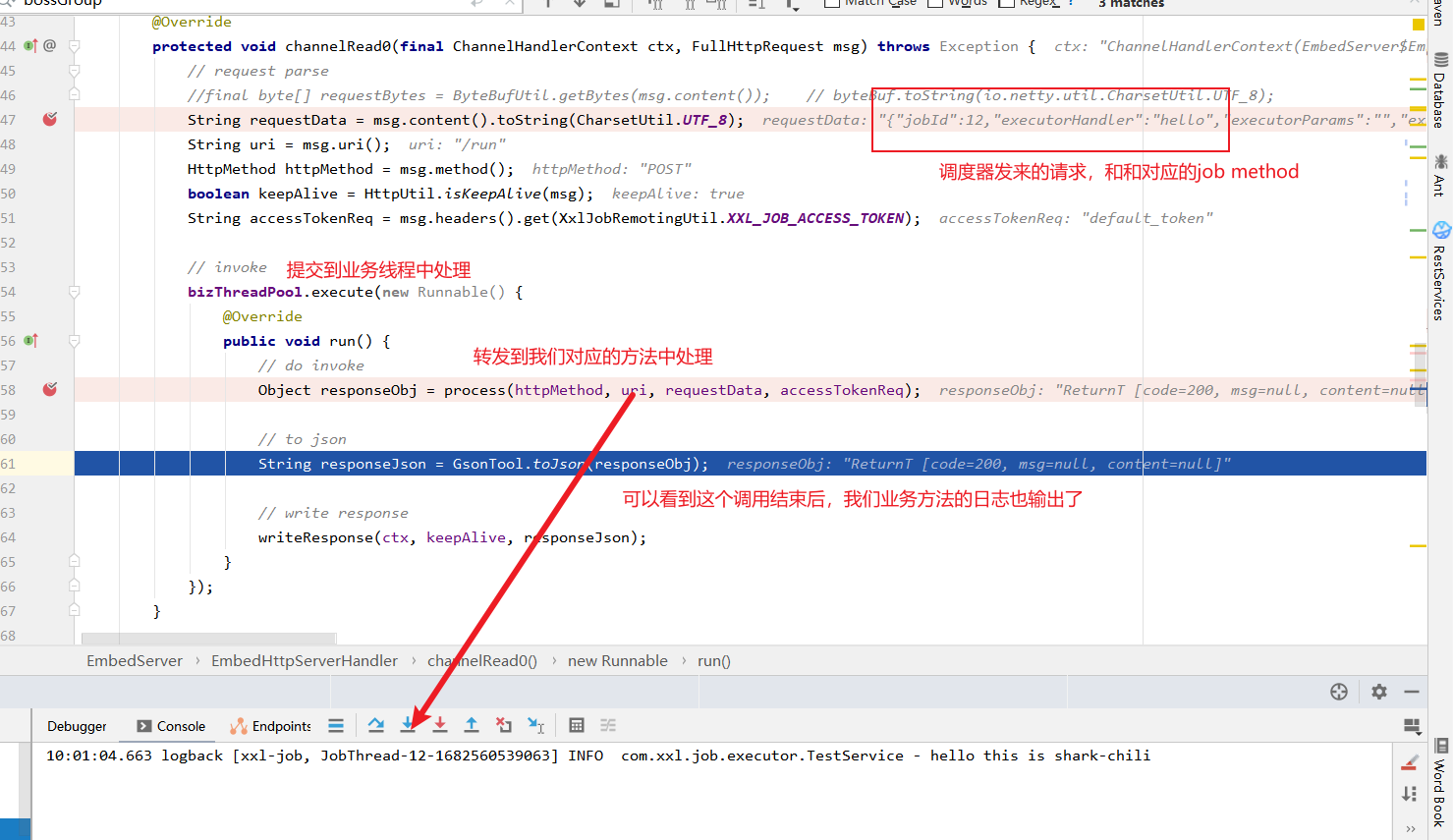
我们不妨找到这个类,对其channelRead0方法打个断点。
从断点参数中我们可以看到这个方法收到调取器的参数之后,会将其提交到业务线程中,调用process方法调用当前服务的方法完成请求。
自此,一次完整的job调度就完成了。
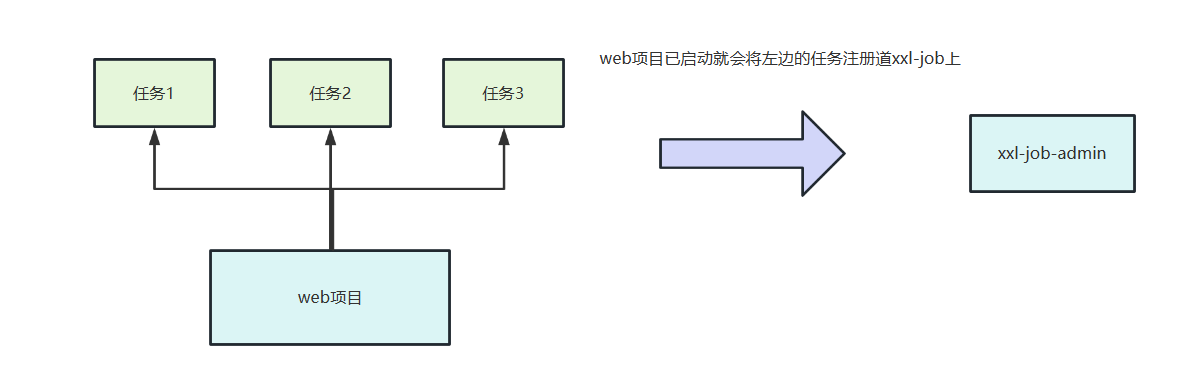
编写任务自动注册组件 需求分析 使用 xxl-job 时会存在一个问题,编写好任务后,虽然@XxlJob注解会将方法注册到xxl-job-admin,但是任务需要我们手动添加。此时,我们希望有这样一个工具,可以让我们只需一个注解即可将执行器和任务直接注册到xxl-job-admin上,这样我们只需在编码阶段写好任务将项目启动,就可以将任务注册到xxl-job-admin中。
实现思路 我们可以借由spring-boot自动装配机制,并定义一个注解,扫描容器中所有执行器和带有这个注解的任务,然后调用xxl-job的api将这些任务注册到xxl-job-admin中。
编写组件 在正式编写组件前,先引入相关依赖
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 <dependency > <groupId > org.springframework.boot</groupId > <artifactId > spring-boot-starter-web</artifactId > </dependency > <dependency > <groupId > org.springframework.boot</groupId > <artifactId > spring-boot-autoconfigure</artifactId > </dependency > <dependency > <groupId > com.xuxueli</groupId > <artifactId > xxl-job-core</artifactId > <version > ${xxl-job.version}</version > </dependency > <dependency > <groupId > cn.hutool</groupId > <artifactId > hutool-all</artifactId > <version > ${hutool.version}</version > </dependency >
首先我们从xxl-job-admin中将这两个类拷过来。
我们在web界面操作xxl-job-admin时发现所有操作都需要基于一个cookie,而这个cookie是需要登录才能得到的。所以我们要定义一个接口,后续将登录和获取cookie保存到内存的操作补充上。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 public interface JobLoginService { void login () ; String getCookie () ; }
同理然后编写一个接口,定义所有关于执行器的bean的操作。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 public interface JobGroupService { List<XxlJobGroup> getJobGroup () ; boolean autoRegisterGroup () ; boolean preciselyCheck () ; }
上文提到我们也需要将任务注册到xxl-job上,所以在这里我们也把这个接口定义上。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 public interface JobInfoService { List<XxlJobInfo> getJobInfo (Integer jobGroupId, String executorHandler) ; Integer addJobInfo (XxlJobInfo xxlJobInfo) ; }
自此所有我们需要的行为都有了,我们就需要开始将逻辑补充上了。首先是登录和获取cookie的方法。代码含义都详细注释了,读者可以自行查阅,这里简单说明一下登录进行的操作就是:
调用xxl-job登录接口
成功后获取cookie
将cookie缓存到map中
而获取cookie的方式也很简单,从map中取出来返回出去就好了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 @Service public class JobLoginServiceImpl implements JobLoginService { @Value("${xxl.job.admin.addresses}") private String adminAddresses; @Value("${xxl.job.admin.username}") private String username; @Value("${xxl.job.admin.password}") private String password; private final Map<String, String> loginCookie = new HashMap <>(); @Override public void login () { String url = adminAddresses + "/login" ; HttpResponse response = HttpRequest.post(url) .form("userName" , username) .form("password" , password) .execute(); List<HttpCookie> cookies = response.getCookies(); Optional<HttpCookie> cookieOpt = cookies.stream() .filter(cookie -> cookie.getName().equals("XXL_JOB_LOGIN_IDENTITY" )) .findFirst(); if (!cookieOpt.isPresent()) { throw new RuntimeException ("get xxl-job cookie error!" ); } String value = cookieOpt.get().getValue(); loginCookie.put("XXL_JOB_LOGIN_IDENTITY" , value); } @Override public String getCookie () { for (int i = 0 ; i < 3 ; i++) { String cookieStr = loginCookie.get("XXL_JOB_LOGIN_IDENTITY" ); if (cookieStr != null ) { return "XXL_JOB_LOGIN_IDENTITY=" + cookieStr; } login(); } throw new RuntimeException ("get xxl-job cookie error!" ); } }
然后就是执行器注册的逻辑了,整体来说有两个方法,分别是精确查询执行器和注册执行器的方法,含义都详尽注释在代码上,读者可自行参阅。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 @Service public class JobGroupServiceImpl implements JobGroupService { @Value("${xxl.job.admin.addresses}") private String adminAddresses; @Value("${xxl.job.executor.appname}") private String appName; @Value("${xxl.job.executor.title}") private String title; @Value("${xxl.job.executor.addressType:0}") private Integer addressType; @Value("${xxl.job.executor.addressList:}") private String addressList; @Autowired private JobLoginService jobLoginService; @Override public boolean preciselyCheck () { List<XxlJobGroup> jobGroup = getJobGroup(); Optional<XxlJobGroup> has = jobGroup.stream() .filter(xxlJobGroup -> xxlJobGroup.getAppname().equals(appName) && xxlJobGroup.getTitle().equals(title)) .findAny(); return has.isPresent(); } @Override public List<XxlJobGroup> getJobGroup () { String url = adminAddresses + "/jobgroup/pageList" ; HttpResponse response = HttpRequest.post(url) .form("appname" , appName) .form("title" , title) .cookie(jobLoginService.getCookie()) .execute(); String body = response.body(); JSONArray array = JSONUtil.parse(body).getByPath("data" , JSONArray.class); List<XxlJobGroup> list = array.stream() .map(o -> JSONUtil.toBean((JSONObject) o, XxlJobGroup.class)) .collect(Collectors.toList()); return list; } @Override public boolean autoRegisterGroup () { String url = adminAddresses + "/jobgroup/save" ; HttpRequest httpRequest = HttpRequest.post(url) .form("appname" , appName) .form("title" , title); httpRequest.form("addressType" , addressType); if (addressType.equals(1 )) { if (Strings.isBlank(addressList)) { throw new RuntimeException ("手动录入模式下,执行器地址列表不能为空" ); } httpRequest.form("addressList" , addressList); } HttpResponse response = httpRequest.cookie(jobLoginService.getCookie()) .execute(); Object code = JSONUtil.parse(response.body()).getByPath("code" ); return code.equals(200 ); } }
最后就是任务注册的接口实现了,核心方法也是模糊查询任务列表和注册任务两个方法,读者参阅注释即可理解,这里不多赘述。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 @Service public class JobInfoServiceImpl implements JobInfoService { @Value("${xxl.job.admin.addresses}") private String adminAddresses; @Autowired private JobLoginService jobLoginService; @Override public List<XxlJobInfo> getJobInfo (Integer jobGroupId, String executorHandler) { String url = adminAddresses + "/jobinfo/pageList" ; HttpResponse response = HttpRequest.post(url) .form("jobGroup" , jobGroupId) .form("executorHandler" , executorHandler) .form("triggerStatus" , -1 ) .cookie(jobLoginService.getCookie()) .execute(); String body = response.body(); JSONArray array = JSONUtil.parse(body).getByPath("data" , JSONArray.class); List<XxlJobInfo> list = array.stream() .map(o -> JSONUtil.toBean((JSONObject) o, XxlJobInfo.class)) .collect(Collectors.toList()); return list; } @Override public Integer addJobInfo (XxlJobInfo xxlJobInfo) { String url = adminAddresses + "/jobinfo/add" ; Map<String, Object> paramMap = BeanUtil.beanToMap(xxlJobInfo); HttpResponse response = HttpRequest.post(url) .form(paramMap) .cookie(jobLoginService.getCookie()) .execute(); JSON json = JSONUtil.parse(response.body()); Object code = json.getByPath("code" ); if (code.equals(200 )) { return Convert.toInt(json.getByPath("content" )); } throw new RuntimeException ("add jobInfo error!" ); } }
自此所有核心工作方法都完成了。我们就可以基于spring-boot的自动装配自动调用这些方法完成执行器和任务的注册。
首先我们定义一个注解,用于要注册到xxl-job的任务的信息。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 @Target({ElementType.METHOD}) @Retention(RetentionPolicy.RUNTIME) public @interface XxlRegister { String cron () ; String jobDesc () default "default jobDesc" ; String author () default "default Author" ; String executorRouteStrategy () default "ROUND" ; int triggerStatus () default 0 ; }
现在我们要编写一个XxlJobAutoRegister扫描容器中带有XxlJob、XxlRegister的方法,并通过xxl-job-admin的api将其注册上去。
代码逻辑很简单,通过ApplicationContextAware获取容器中的bean,然后基于ApplicationListener监听容器加载情况,在容器准备好提供服务时,做下面这几件事:
通过ApplicationContextAware找到所有的bean
遍历bean,找到带有XxlJob的方法。
查看带有XxlJob的方法是否有XxlRegister,如果有则将其注册到xxl-job-admin
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 @Component public class XxlJobAutoRegister implements ApplicationListener <ApplicationReadyEvent>, ApplicationContextAware { private static final Log log = LogFactory.get(); private ApplicationContext applicationContext; @Autowired private JobGroupService jobGroupService; @Autowired private JobInfoService jobInfoService; @Override public void setApplicationContext (ApplicationContext applicationContext) throws BeansException { this .applicationContext = applicationContext; } @Override public void onApplicationEvent (ApplicationReadyEvent event) { addJobGroup(); addJobInfo(); } private void addJobGroup () { if (jobGroupService.preciselyCheck()) return ; if (jobGroupService.autoRegisterGroup()) log.info("auto register xxl-job group success!" ); } private void addJobInfo () { List<XxlJobGroup> jobGroups = jobGroupService.getJobGroup(); XxlJobGroup xxlJobGroup = jobGroups.get(0 ); String[] beanDefinitionNames = applicationContext.getBeanNamesForType(Object.class, false , true ); for (String beanDefinitionName : beanDefinitionNames) { Object bean = applicationContext.getBean(beanDefinitionName); Map<Method, XxlJob> methodWithXxlJob = MethodIntrospector.selectMethods(bean.getClass(), (MethodIntrospector.MetadataLookup<XxlJob>) method -> AnnotatedElementUtils.findMergedAnnotation(method, XxlJob.class)); for (Map.Entry<Method, XxlJob> methodXxlJobEntry : methodWithXxlJob.entrySet()) { Method executeMethod = methodXxlJobEntry.getKey(); XxlJob xxlJob = methodXxlJobEntry.getValue(); if (executeMethod.isAnnotationPresent(XxlRegister.class)) { List<XxlJobInfo> jobInfo = jobInfoService.getJobInfo(xxlJobGroup.getId(), xxlJob.value()); if (!jobInfo.isEmpty()) { Optional<XxlJobInfo> first = jobInfo.stream() .filter(xxlJobInfo -> xxlJobInfo.getExecutorHandler().equals(xxlJob.value())) .findFirst(); if (first.isPresent()) continue ; } XxlRegister xxlRegister = executeMethod.getAnnotation(XxlRegister.class); XxlJobInfo xxlJobInfo = createXxlJobInfo(xxlJobGroup, xxlJob, xxlRegister); Integer jobInfoId = jobInfoService.addJobInfo(xxlJobInfo); } } } } private XxlJobInfo createXxlJobInfo (XxlJobGroup xxlJobGroup, XxlJob xxlJob, XxlRegister xxlRegister) { XxlJobInfo xxlJobInfo = new XxlJobInfo (); xxlJobInfo.setJobGroup(xxlJobGroup.getId()); xxlJobInfo.setJobDesc(xxlRegister.jobDesc()); xxlJobInfo.setAuthor(xxlRegister.author()); xxlJobInfo.setScheduleType("CRON" ); xxlJobInfo.setScheduleConf(xxlRegister.cron()); xxlJobInfo.setGlueType("BEAN" ); xxlJobInfo.setExecutorHandler(xxlJob.value()); xxlJobInfo.setExecutorRouteStrategy(xxlRegister.executorRouteStrategy()); xxlJobInfo.setMisfireStrategy("DO_NOTHING" ); xxlJobInfo.setExecutorBlockStrategy("SERIAL_EXECUTION" ); xxlJobInfo.setExecutorTimeout(0 ); xxlJobInfo.setExecutorFailRetryCount(0 ); xxlJobInfo.setGlueRemark("GLUE代码初始化" ); xxlJobInfo.setTriggerStatus(xxlRegister.triggerStatus()); return xxlJobInfo; } }
自此我们的组件开发完成了,为了让上面的XxlJobAutoRegister,我们需要编写一个配置类XxlJobPlusConfig,他会扫描XxlJobAutoRegister的包。
1 2 3 4 @Configuration @ComponentScan(basePackages = "com.xxl.job.plus.executor") public class XxlJobPlusConfig {}
然后编写一个spring.factories,将XxlJobPlusConfig路径写入,确保其他引入该组件时会自动装配XxlJobAutoRegister将指定的xxl-job注册上去。
1 2 org.springframework.boot.autoconfigure.EnableAutoConfiguration=\ com.xxl.job.plus.executor.config.XxlJobPlusConfig
引入组件并进行测试 首先将上述组件打包,然后在需要使用这个组件的应用中引入
1 2 3 4 5 <dependency> <groupId>com.cn.hydra</groupId> <artifactId>xxljob-autoregister-spring-boot-starter</artifactId> <version>0.0.1</version> </dependency>
这里直接使用xxl源码自带的spring-boot项目。
编写一个自定义的bean
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 @Service public class TestService { private static Logger logger = LoggerFactory.getLogger(TestService.class); @XxlJob(value = "testJob") @XxlRegister(cron = "0 0 0 * * ? *", author = "shark-chili", jobDesc = "测试job") public void testJob () { logger.info("testJob" ); } @XxlJob(value = "hello") @XxlRegister(cron = "0 0 0 * * ? *", triggerStatus = 1) public void hello () { logger.info("hello this is shark-chili" ); } }
最后新增如下配置
1 2 3 4 5 6 7 8 9 10 11 12 13 xxl.job.admin.username=admin xxl.job.admin.password=123456 xxl.job.executor.title=shark-chili xxl.job.executor.addressType=0 xxl.job.executor.addressList=http://127.0.0.1:9999
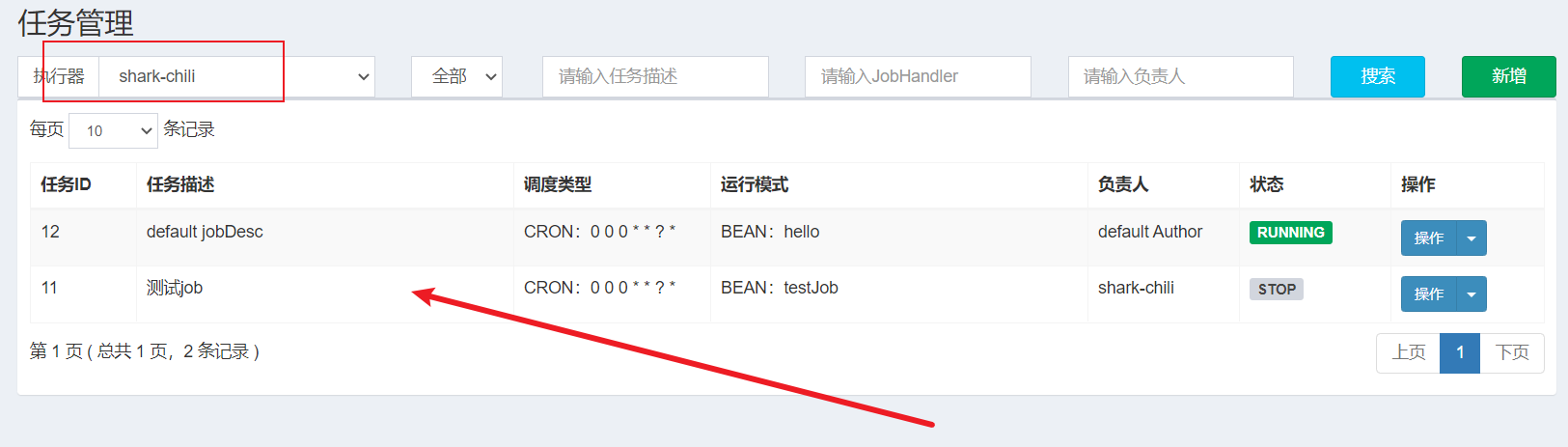
最后将xxl-job-admin和xxl-job启动,打开xxl-job的管理页面,可以看到我们的任务都注册进来了。