jdbc流程
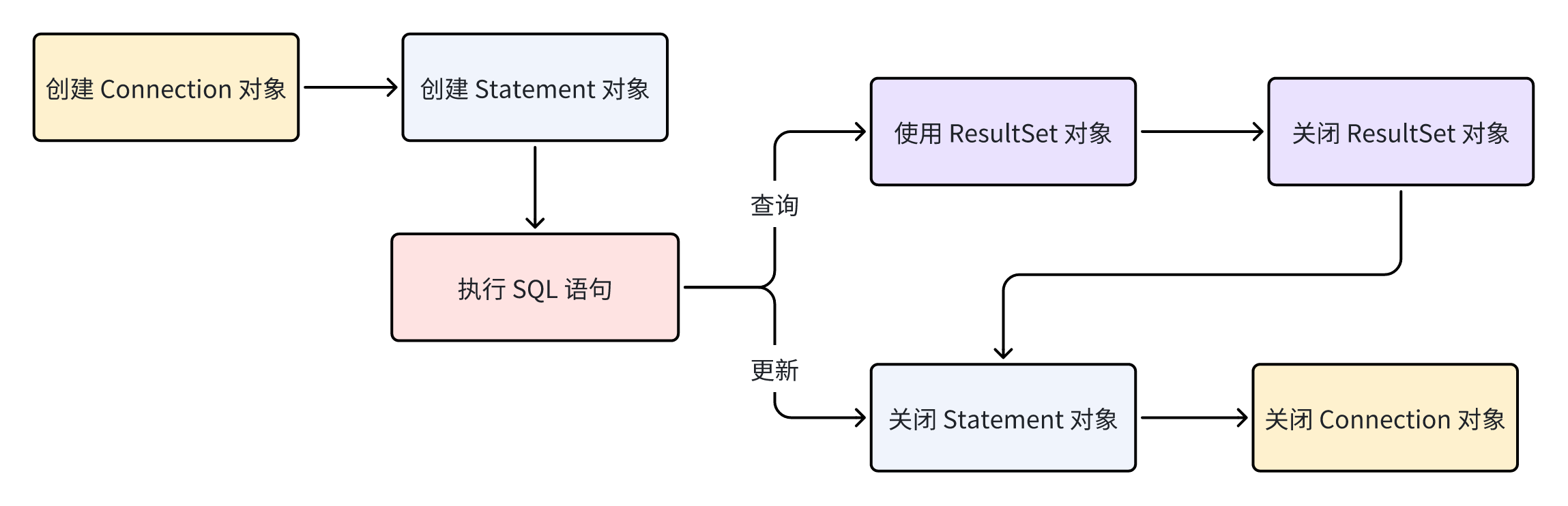
jdbc操作
jdbc连接
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| @Test
public void testConnection5() throws Exception {
InputStream is =
ConnectionTest.class.getClassLoader().getResourceAsStream("jdbc.properties");
Properties pros = new Properties();
pros.load(is);
String user = pros.getProperty("user");
String password = pros.getProperty("password");
String url = pros.getProperty("url");
String driverClass = pros.getProperty("driverClass");
Class.forName(driverClass);
Connection conn = DriverManager.getConnection(url,user,password);
System.out.println(conn);
}
|
其中,配置文件声明在工程的src目录下:【jdbc.properties】
1
2
3
4
| user=root
password=abc123
url=jdbc:mysql://localhost:3306/test
driverClass=com.mysql.jdbc.Driver
|
使用PreparedStatement实现增删改操作
可以通过调用 Connection 对象的 preparedStatement(String sql) 方法获取 PreparedStatement 对象 PreparedStatement 接口是 Statement 的子接口,它表示一条预编译过的 SQL 语句 PreparedStatement 对象所代表的 SQL 语句中的参数用问号(?)来表示,调用 PreparedStatement 对象的 setXxx() 方法来设置这些参数. setXxx() 方法有两个参数,第一个参数是要设置的 SQL 语句中的参数的索引(从 1 开始),第二个是设置的 SQL 语句中的参数的值
PreparedStatement vs Statement
代码的可读性和可维护性。
PreparedStatement 能最大可能提高性能: DBServer会对预编译语句提供性能优化。因为预编译语句有可能被重复调用,所以语句在被DBServer的 编译器编译后的执行代码被缓存下来,那么下次调用时只要是相同的预编译语句就不需要编译,只要将参数直接传入编译过的语句执行代码中就会得到执行。 在statement语句中,即使是相同操作但因为数据内容不一样,所以整个语句本身不能匹配,没有缓存语句的意义.事实是没有数据库会对普通语句编译后的执行代码缓存。这样每执行一次都要对传入的语句编译一次。 (语法检查,语义检查,翻译成二进制命令,缓存)
PreparedStatement 可以防止 SQL 注入
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
public void update(String sql,Object ... args){
Connection conn = null;
PreparedStatement ps = null;
try {
conn = JDBCUtils.getConnection();
ps = conn.prepareStatement(sql);
for(int i = 0;i < args.length;i++){
ps.setObject(i + 1, args[i]);
}
ps.execute();
} catch (Exception e) {
e.printStackTrace();
}finally{
JDBCUtils.closeResource(conn, ps);
}
}
|
使用PreparedStatement实现查询操作
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
|
public <T> T getInstance(Class<T> clazz, String sql, Object... args) {
Connection conn = null;
PreparedStatement ps = null;
ResultSet rs = null;
try {
conn = JDBCUtils.getConnection();
ps = conn.prepareStatement(sql);
for (int i = 0; i < args.length; i++) {
ps.setObject(i + 1, args[i]);
}
rs = ps.executeQuery();
ResultSetMetaData rsmd = rs.getMetaData();
int columnCount = rsmd.getColumnCount();
if (rs.next()) {
T t = clazz.newInstance();
for (int i = 0; i < columnCount; i++) {
Object columnVal = rs.getObject(i + 1);
String columnLabel = rsmd.getColumnLabel(i + 1);
Field field = clazz.getDeclaredField(columnLabel);
field.setAccessible(true);
field.set(t, columnVal);
}
return t;
}
} catch (Exception e) {
e.printStackTrace();
} finally {
JDBCUtils.closeResource(conn, ps, rs);
}
return null;
}
|
jdbc事务处理
调用 Connection 对象的 setAutoCommit(false);
以取消自动提交事务在所有的 SQL 语句都成功执行后,调用 commit();
方法提交事务在出现异常时,调用 rollback(); 方法回滚事务
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
| public void testJDBCTransaction() {
Connection conn = null;
try {
conn = JDBCUtils.getConnection();
conn.setAutoCommit(false);
String sql1 = "update user_table set balance = balance - 100 where user = ?";
update(conn, sql1, "AA");
String sql2 = "update user_table set balance = balance + 100 where user = ?";
update(conn, sql2, "BB");
conn.commit();
} catch (Exception e) {
e.printStackTrace();
try {
conn.rollback();
} catch (SQLException e1) {
e1.printStackTrace();
}
} finally {
try {
conn.setAutoCommit(true);
} catch (SQLException e) {
e.printStackTrace();
}
JDBCUtils.closeResource(conn, null, null);
}
}
|
涉及到的 update 方法代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
public void update(Connection conn ,String sql, Object... args) {
PreparedStatement ps = null;
try {
ps = conn.prepareStatement(sql);
for (int i = 0; i < args.length; i++) {
ps.setObject(i + 1, args[i]);
}
ps.execute();
} catch (Exception e) {
e.printStackTrace();
} finally {
JDBCUtils.closeResource(null, ps);
}
}
|
Druid数据库连接池
如果使用传统的jdbc连接方式,可能会出现以下问题:
- 普通的JDBC数据库连接使用 DriverManager 来获取,每次向数据库建立连接的时候都要将 Connection 加载到内存中,再验证用户名和密码(得花费0.05s~1s的时间)。需要数据库连接的时候,就向数据库要求 一个,执行完成后再断开连接。这样的方式将会消耗大量的资源和时间。数据库的连接资源并没有得到很好的重复利用。若同时有几百人甚至几千人在线,频繁的进行数据库连接操作将占用很多的系统资源,严 重的甚至会造成服务器的崩溃。
- 对于每一次数据库连接,使用完后都得断开。否则,如果程序出现异常而未能关闭,将会导致数据库系统 中的内存泄漏,最终将导致重启数据库。(回忆:何为Java的内存泄漏?)
- 这种开发不能控制被创建的连接对象数,系统资源会被毫无顾及的分配出去,如连接过多,也可能导致内 存泄漏,服务器崩溃。
数据库连接池的基本思想:就是为数据库连接建立一个“缓冲池”。预先在缓冲池中放入一定数量的连接,当需要建立数据库连接时,只需从“缓冲池”中取出一个,使用完毕之后再放回去。
数据库连接池负责分配、管理和释放数据库连接,它允许应用程序重复使用一个现有的数据库连接,而不是重新建立一个。
Druid是阿里巴巴开源平台上一个数据库连接池实现,它结合了C3P0、DBCP、Proxool等DB池的优点,同时加入了 日志监控,可以很好的监控DB池连接和SQL的执行情况,可以说是针对监控而生的DB连接池,可以说是目前最好的连接池之一。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| package com.atguigu.druid;
import java.sql.Connection;
import java.util.Properties;
import javax.sql.DataSource;
import com.alibaba.druid.pool.DruidDataSourceFactory;
public class TestDruid {
public static void main(String[] args) throws Exception {
Properties pro = new Properties();
pro.load(TestDruid.class.getClassLoader().getResourceAsStream("druid.properties"));
DataSource ds = DruidDataSourceFactory.createDataSource(pro);
Connection conn = ds.getConnection();
System.out.println(conn);
}
}
|
其中,src下的配置文件为:【druid.properties】
1
2
3
4
5
6
7
8
| url=jdbc:mysql://localhost:3306/test?rewriteBatchedStatements=true
username=root
password=123456
driverClassName=com.mysql.jdbc.Driver
initialSize=10
maxActive=20
maxWait=1000
filters=wall
|



