
MyBatis源码
MyBatis 执行流程
首先回顾一下jdbc的执行流程。
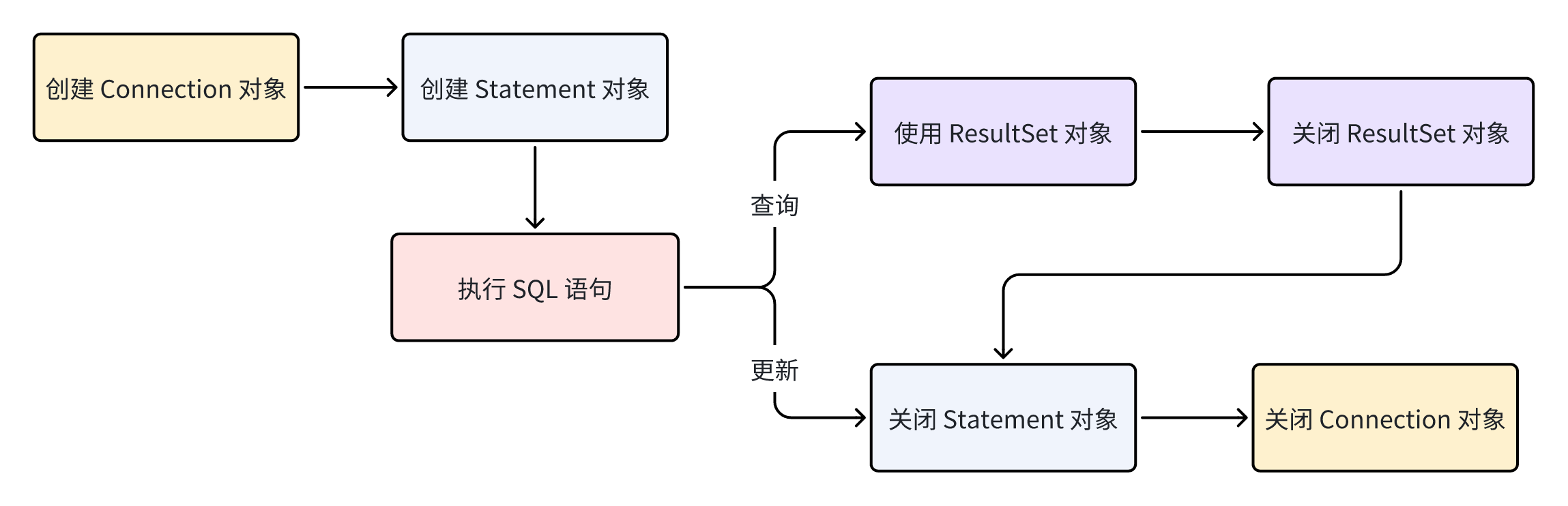
MyBatis的执行流程也包含jdbc的执行流程,但是会做一些前置处理。

方法代理(MapperMethod)
使用动态代理调用,可以看到非常熟悉的 invoke 方法,这个invoke方法就是动态代理的逻辑,method.invoke()方法就是实现代理类对原始方法的调用。
1 | public class MapperProxy<T> implements InvocationHandler, Serializable { |
会话(SqlSession)
SqlSession 是myBatis的门面(采用门面模式设计),核心作用是为用户提供API。API包括增、删、改、查以及提交、关闭等。其自身是没有能力处理这些请求的,所以内部会包含一个唯一的执行器 Executor,所有请求都会交给执行器来处理。
SqlSession 是SqlSessionFactory会话工厂创建出来的一个会话的对象,这个SqlSession对象用于执行具体的SQL语句并返回给用户请求的结果。
执行器(Executor)
Executor是一个大管家,核心功能包括:缓存维护、获取动态SQL、获取连接、以及最终的JDBC调用等。在图中所有蓝色节点全部都是在Executor中完成。
这么多事情无法全部亲力亲为,就需要把任务分派下去。所以Executor内部还会包含若干个组件:
- 缓存维护:cache
- 获取连接:Transaction
- 获取动态sql:SqlSource
- 调用jdbc:StatementHandler
上述组件中前三个和Executor是1对1关系,只有StatementHandler是1对多。每执行一次SQL 就会构造一个新的StatementHandler。StatementHandler的作用就是专门和JDBC打交道,执行SQL的。
SQL处理器(StatementHandler)
在JDBC中执行一次sql的步骤包括。预编译SQL、设置参数然后执行。StatementHandler就是用来处理这三步。
用于获取预处理器,共有三种类型。通过statementType="STATEMENT|PREPARED|CALLABLE" 可分别进行指定。
- PreparedStatementHandler:带预处理的执行器
- CallableStatementHandler:存储过程执行器
- SimpleStatementHandler:基于Sql执行器
同样它也需要两个助手分别是:
- 设置参数:ParameterHandler
- 读取结果:ResultSetHandler,可在SqlSession中查询时自行定义ResultSetHandler
另外的执行是由它自己完成。
主键生成
在平时开发的时候经常会有这样的需求,插入数据返回主键,或者插入数据之前需要获取主键,这样的需求在 mybatis 中也是支持的。只需要在 xml 里配置 useGenerateKey = true 就好了。
其中主要的逻辑部分就在 KeyGenerator 中,其接口方法如下:
processBefore 是在生成 StatementHandler 的时候执行,processAfter 则是在完成插入返回结果之前执行。
1 | public interface KeyGenerator { |
如代码所见 KeyGenerator 非常的简单,主要是通过两个拦截方法实现的:
- Jdbc3KeyGenerator:主要基于 java.sql.Statement.getGeneratedKeys 的主键返回接口实现的,所以他不需要 processBefore 方法,只需要在获取到结果后使用 processAfter 拦截,然后用反射将主键设置到参数中即可;
- SelectKeyGenerator:主要是通过 XML 配置或者注解设置 selectKey ,然后单独发出查询语句,在返回拦截方法中使用反射设置主键,其中两个拦截方法只能使用其一,在 selectKey.order 属性中设置
AFTER|BEFORE来确定;
MyBatis 缓存
myBatis中存在两个缓存,一级缓存和二级缓存。
- 一级缓存:也叫做会话级缓存,生命周期仅存在于当前会话,不可以直接关关闭。但可以通过flushCache和localCacheScope对其做相应控制。
- 二级缓存:也叫应用级性缓存,缓存对象存在于整个应用周期,而且可以跨线程使用。
一级缓存
一级缓存的命中场景
关于一级缓存的命中可大致分为两个场景,满足特定命中参数,第二不触发清空方法。
缓存命中参数:
- SQL与参数相同:
- 同一个会话:
- 相同的MapperStatement ID:
- RowBounds行范围相同:
触发清空缓存
- 手动调用clearCache
- 执行提交回滚
- 执行update
- 配置flushCache=true
- 缓存作用域为Statement
一级缓存源码解析
一级缓存逻辑就存在于 BaseExecutor (基础执行器)里面。当会话接收到查询请求之后,会交给执行器的Query方法,在这里会通过 Sql、参数、分页条件等参数创建一个缓存key,在基于这个key去 PerpetualCache中查找对应的缓存值,如果有命中直接返回。没有就会查询数据库,然后在填充缓存。最终缓存的实现非常简单,就是一个HashMap。
一级缓存的清空
缓存的清空对应BaseExecutor中的 clearLocalCache.方法。只要找到调用该方法地方,就知道哪些场景中会清空缓存了。
- update: 执行任意增删改
- select:查询又分为两种情况清空,一前置清空,即配置了flushCache=true。二后置清空,配置了缓存作用域为statement 查询结束合会清空缓存。
- commit:提交前清空
- Rolback:回滚前清空
注意:clearLocalCache 不是清空某条具体数据,而清当前会话下所有一级缓存数据。
MyBatis集成Spring后一级缓存失效的问题?
很多人发现,集成一级缓存后会话失效了,以为是spring Bug ,真正原因是Spring 对SqlSession进行了封装,通过SqlSessionTemplae ,使得每次调用Sql,都会重新构建一个SqlSession,具体参见SqlSessionInterceptor。而根据前面所学,一级缓存必须是同一会话才能命中,所以在这些场景当中不能命中。
怎么解决呢?给Spring 添加事物 即可。添加事物之后,SqlSessionInterceptor(会话拦截器)就会去判断两次请求是否在同一事物当中,如果是就会共用同一个SqlSession会话来解决。
二级缓存
二级缓存也称作是应用级缓存,与一级缓存不同的,是它的作用范围是整个应用,而且可以跨线程使用。所以二级缓存有更高的命中率,适合缓存一些修改较少的数据。在流程上是先访问二级缓存,再访问一级缓存。
MyBatis抽象出Cache接口,其只定义了缓存中最基本的功能方法:
- 设置缓存
- 获取缓存
- 清除缓存
- 获取缓存数量
然后上述中每一个功能都会对应一个组件类,并基于装饰者加责任链的模式,将各个组件进行串联。在执行缓存的基本功能时,其它的缓存逻辑会沿着这个责任链依次往下传递。
这样设计有以下优点:
- 职责单一:各个节点只负责自己的逻辑,不需要关心其它节点。
- 扩展性强:可根据需要扩展节点、删除节点,还可以调换顺序保证灵活性。
- 松耦合:各节点之间不没强制依赖其它节点。而是通过顶层的Cache接口进行间接依赖。
缓存空间声明
二级默认缓存默认是不开启的,需要为其声明缓存空间才可以使用,通过@CacheNamespace 或 为指定的MappedStatement声明。声明之后该缓存为该Mapper所独有,其它Mapper不能访问。如需要多个Mapper共享一个缓存空间可通过@CacheNamespaceRef 或进行引用同一个缓存空间。
二级缓存的命中条件
二级缓存的命中场景与一级缓存类似,不同在于二级可以跨会放使用,还有就是二级缓存的更新,为了保证数据一至性,二级缓存必须是会话提交之才会真正填充,包括对缓存的清空,也必须是会话正常提交之后才生效。
二级缓存结构
为了实现会话提交之后才变更二级缓存,MyBatis为每个会话设立了若干个暂存区,当前会话对指定缓存空间的变更,都存放在对应的暂存区,当会话提交之后才会提交到每个暂存区对应的缓存空间。为了统一管理这些暂存区,每个会话都一个唯一的事物缓存管理器。所以这里暂存区也可叫做事物缓存。
二级缓存的执行流程
原本会话是通过Executor实现SQL调用,这里基于装饰器模式使用CachingExecutor对SQL调用逻辑进行拦截。以嵌入二级缓存相关逻辑。
查询操作query
当会话调用query() 时,会基于查询语句、参数等数据组成缓存Key,然后尝试从二级缓存中读取数据。读到就直接返回,没有就调用被装饰的Executor去查询数据库,然后在填充至对应的暂存区。
请注意,这里的查询是实时从缓存空间读取的,而变更,只会记录在暂存区
更新操作update
当执行update操作时,同样会基于查询的语句和参数组成缓存KEY,然后在执行update之前清空缓存。这里清空只针对暂存区,同时记录清空的标记,以便当会话提交之时,依据该标记去清空二级缓存空间。
如果在查询操作中配置了flushCache=true ,也会执行相同的操作。
提交操作commit
当会话执行commit操作后,会将该会话下所有暂存区的变更,更新到对应二级缓存空间去。
Hibernate和MyBatis的区别
相同点
Hibernate与MyBatis都可以是通过SessionFactoryBuider由XML配置文件生成SessionFactory,然后由SessionFactory 生成Session,最后由Session来开启执行事务和SQL语句。
其中SessionFactoryBuider,SessionFactory,Session的生命周期都是差不多的。Hibernate和MyBatis都支持 JDBC 和 JTA 事务处理。
不同点
hibernate是全自动,而mybatis是半自动
hibernate完全可以通过对象关系模型实现对数据库的操作,拥有完整的JavaBean对象与数据库的映射结构来自动生成sql。而mybatis仅有基本的字段映射,对象数据以及对象实际关系仍然需要通过手写sql来实现和管理。
hibernate数据库移植性远大于mybatis
hibernate通过它强大的映射结构和hql语言,大大降低了对象与数据库(Oracle、MySQL等)的耦合性,而mybatis由于需要手写sql,因此与数据库的耦合性直接取决于程序员写sql的方法,如果sql不具通用性而用了很多某数据库特性的sql语句的话,移植性也会随之降低很多,成本很高。
hibernate拥有完整的日志系统
hibernate日志系统非常健全,涉及广泛,包括:sql记录、关系异常、优化警告、缓存提示、脏数据警告等;而mybatis则除了基本记录功能外,功能薄弱很多。
mybatis相比hibernate需要关心很多细节
hibernate配置要比mybatis复杂的多,学习成本也比mybatis高。但也正因为mybatis使用简单,才导致它要比hibernate关心很多技术细节。mybatis由于不用考虑很多细节,开发模式上与传统jdbc区别很小,因此很容易上手并开发项目,但忽略细节会导致项目前期bug较多,因而开发出相对稳定的软件很慢,而开发出软件却很快。hibernate则正好与之相反。但是如果使用hibernate很熟练的话,实际上开发效率丝毫不差于甚至超越mybatis。
sql直接优化上,mybatis要比hibernate方便很多
由于mybatis的sql都是写在xml里,因此优化sql比hibernate方便很多。而hibernate的sql很多都是自动生成的,无法直接维护sql;虽有hql,但功能还是不及sql强大,见到报表等变态需求时,hql也歇菜,也就是说hql是有局限的;hibernate虽然也支持原生sql,但开发模式上却与orm不同,需要转换思维,因此使用上不是非常方便。总之写sql的灵活度上hibernate不及mybatis。
缓存机制上,hibernate要比mybatis更好一些
MyBatis的二级缓存配置都是在每个具体的表-对象映射中进行详细配置,这样针对不同的表可以自定义不同的缓存机制。并且Mybatis可以在命名空间中共享相同的缓存配置和实例,通过Cache-ref来实现。
而Hibernate对查询对象有着良好的管理机制,用户无需关心SQL。所以在使用二级缓存时如果出现脏数据,系统会报出错误并提示。


