
MySQL语句执行原理
count(*) 的实现方式
在不同的MySQL引擎中,count(*)有不同的实现方式。
- MyISAM引擎把一个表的总行数存在了磁盘上,因此执行count(*)的时候会直接返回这个数,效率很高;
- 而InnoDB引擎就麻烦了,它执行count(*)的时候,需要把数据一行一行地从引擎里面读出来,然后累积计数。
这篇文章里讨论的是没有过滤条件的count(*),如果加了where 条件的话,MyISAM表也是不能返回得这么快的。
为什么InnoDB不跟MyISAM一样,也把数字存起来呢?
由于多版本并发控制(MVCC)的原因,InnoDB表“应该返回多少行”也是不确定的。每一行记录都要判断自己是否对这个会话可见,因此对于count(*)请求来说,InnoDB只好把数据一行一行地读出依次判断,可见的行才能够用于计算“基于这个查询”的表的总行数。
用缓存系统保存计数
一般会想到使用 Redis 缓存总数,但是即使 Redis 正常工作,这个值还是逻辑上不精确的。
因为使用 Redis 存储会存在数据不一致的情况,无论是先往数据表里插入一行,然后 Redis 计数 + 1; 还是先 Redis 计数 + 1,再往数据表里插入一行。
Redis 和 MySQL 是不同的存储构成的系统,不支持分布式事务,无法拿到精确一致的视图。
在数据库保存计数
| 时刻 | 会话A | 会话B |
|---|---|---|
| T1 | ||
| T2 | begin; 表C中计数加1 |
|
| T3 | begin; 读表C计数值; 查询最近100条记录; commit; |
|
| T4 | 插入一行数据R; commit; |
虽然会话B的读操作仍然是在T3执行的,但是因为这时候更新事务还没有提交,所以计数值加1这个操作对会话B还不可见。
因此,会话B看到的结果里, 查计数值和“最近100条记录”看到的结果,逻辑上就是一致的。
不同的 count 用法
count()是一个聚合函数,对于返回的结果集,一行行地判断,如果count函数的参数不是NULL,累计值就加1,否则不加。最后返回累计值。
count(*)、count(主键id)和count(1) 都表示返回满足条件的结果集的总行数;而count(字段),则表示返回满足条件的数据行里面,参数“字段”不为NULL的总个数。
对于count(主键id)来说,InnoDB引擎会遍历整张表,把每一行的id值都取出来,返回给server层。server层拿到id后,判断是不可能为空的,就按行累加。
对于count(1)来说,InnoDB引擎遍历整张表,但不取值。server层对于返回的每一行,放一个数字“1”进去,判断是不可能为空的,按行累加。
单看这两个用法的差别的话,你能对比出来,count(1)执行得要比count(主键id)快。因为从引擎返回id会涉及到解析数据行,以及拷贝字段值的操作。
对于count(字段)来说:
- 如果这个“字段”是定义为not null的话,一行行地从记录里面读出这个字段,判断不能为null,按行累加;
- 如果这个“字段”定义允许为null,那么执行的时候,判断到有可能是null,还要把值取出来再判断一下,不是null才累加。
也就是前面的第一条原则,server层要什么字段,InnoDB就返回什么字段。
但是count(*)是例外,并不会把全部字段取出来,而是专门做了优化,不取值。count(*)肯定不是null,按行累加。
由于事务可以保证中间结果不被别的事务读到,因此修改计数值和插入新记录的顺序是不影响逻辑结果的。但是,从并发系统性能的角度考虑,你觉得在这个事务序列里,应该先插入操作记录,还是应该先更新计数表呢?
并发系统性能的角度考虑,应该先插入操作记录,再更新计数表。
因为更新计数表涉及到行锁的竞争,先插入再更新能最大程度地减少事务之间的锁等待,提升并发度。
如果把update计数表放到事务的第一个语句,多个业务表同时插入数据的话,等待时间会更长吗?
答案是不会。即使我们用一个计数表记录多个业务表的行数,也肯定会给表名字段加唯一索引。在更新计数表的时候,一定会传入where table_name=$table_name,使用主键索引,更新加行锁只会锁在一行上。而在不同业务表插入数据,是更新不同的行,不会有行锁。
查询一行数据怎么那么慢
构造一个表,插入10万行数据
1 | mysql> CREATE TABLE `t` ( |
第一类:查询长时间不返回
在表t执行下面的SQL语句:
1 | mysql> select * from t where id=1; |
大概率是表t被锁住了,执行一下show processlist命令,看看当前语句处于什么状态。
等MDL锁
如图2所示,就是使用show processlist命令查看Waiting for table metadata lock的示意图。

session A 通过lock table命令持有表t的MDL写锁,而session B的查询需要获取MDL读锁。所以,session B进入等待状态。
通过查询sys.schema_table_lock_waits这张表,我们就可以直接找出造成阻塞的process id,把这个连接用kill 命令断开即可。

等flush
在表t上,执行下面的SQL语句:
1 | mysql> select * from information_schema.processlist where id=1; |
查出来这个线程的状态是Waiting for table flush,这个状态表示的是,现在有一个线程正要对表t做flush操作。
如果指定表t的话,代表的是只关闭表t;如果没有指定具体的表名,则表示关闭MySQL里所有打开的表。但是正常这两个语句执行起来都很快,除非它们也被别的线程堵住了。
所以,出现Waiting for table flush状态的可能情况是:有一个flush tables命令被别的语句堵住了,然后它又堵住了我们的select语句。
同样使用show processlist命令,找到并kill掉阻塞的线程。
等行锁
1 | mysql> select * from t where id=1 lock in share mode; |
由于访问id=1这个记录时要加读锁,如果这时候已经有一个事务在这行记录上持有一个写锁,我们的select语句就会被堵住。
如果你用的是MySQL 5.7版本,可以通过sys.innodb_lock_waits 表查到谁在占用这个写锁。
查询方法是:
1 | mysql> select * from t sys.innodb_lock_waits where locked_table=`'test'.'t'`\G |
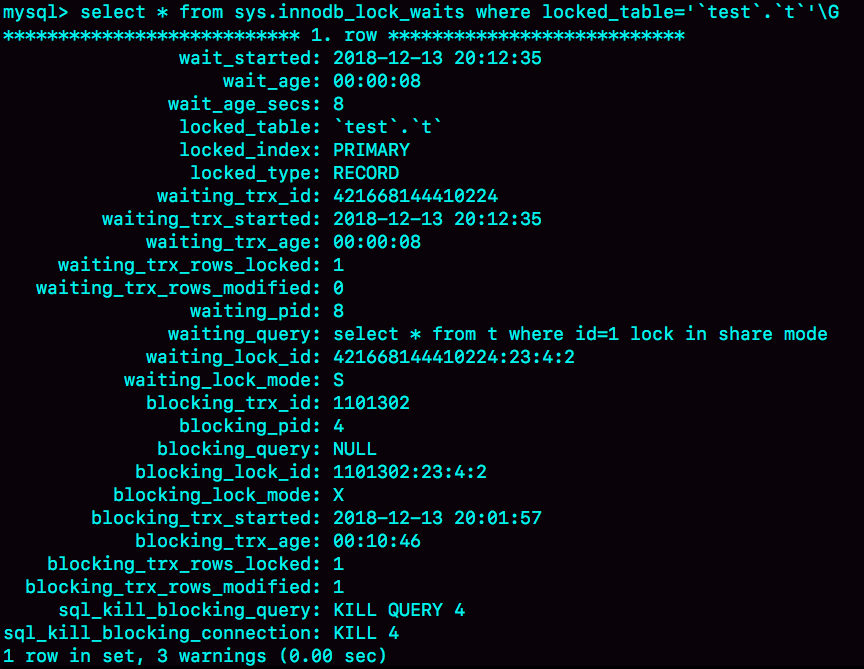
可以看到,这个信息很全,4号线程是造成堵塞的罪魁祸首。而干掉这个罪魁祸首的方式,就是KILL QUERY 4或KILL 4。
不过,这里不应该显示“KILL QUERY 4”。这个命令表示停止4号线程当前正在执行的语句,而这个方法其实是没有用的。因为占有行锁的是update语句,这个语句已经是之前执行完成了的,现在执行KILL QUERY,无法让这个事务去掉id=1上的行锁。
实际上,KILL 4才有效,也就是说直接断开这个连接。这里隐含的一个逻辑就是,连接被断开的时候,会自动回滚这个连接里面正在执行的线程,也就释放了id=1上的行锁。
第二类:查询慢
| sessionA | sessionB |
|---|---|
| start transaction with consistent snapshot; | update t set c=c+1 where id=1; 执行100万次 |
| select * from t where id = 1; | |
| select * from t where id=1 lock in share mode; |
session A先用start transaction with consistent snapshot命令启动了一个事务,之后session B才开始执行update 语句。
session B更新完100万次,生成了100万个回滚日志(undo log)。
带lock in share mode的SQL语句,是当前读,因此会直接读到1000001这个结果,所以速度很快;而select * from t where id=1这个语句,是一致性读,因此需要从1000001开始,依次执行undo log,执行了100万次以后,才将1这个结果返回。
Order by的排序原理
现给出一个使用 order by 的查询语句,通过这个语句了解其执行流程。
1 | select city,name,age from t where city='杭州' order by name limit 1000 ; |
全字段排序
为避免全表扫描,我们需要在city字段加上索引。
在city字段上创建索引之后,我们用explain命令来看看这个语句的执行情况。
Extra这个字段中的“Using filesort”表示的就是需要排序,MySQL会给每个线程分配一块内存用于排序,称为sort_buffer。
假设满足city=’杭州’条件的行,是从ID_X到ID_Y的这些记录。
通常情况下,这个语句执行流程如下所示 :
- 初始化sort_buffer,确定放入name、city、age这三个字段;
- 从索引city找到第一个满足city=’杭州’条件的主键id,也就是ID_X;
- 到主键id索引取出整行,取name、city、age三个字段的值,存入sort_buffer中;
- 从索引city取下一个记录的主键id;
- 重复步骤3、4直到city的值不满足查询条件为止,对应的主键id也就是ID_Y;
- 对sort_buffer中的数据按照字段name做快速排序;
- 按照排序结果取前1000行返回给客户端。
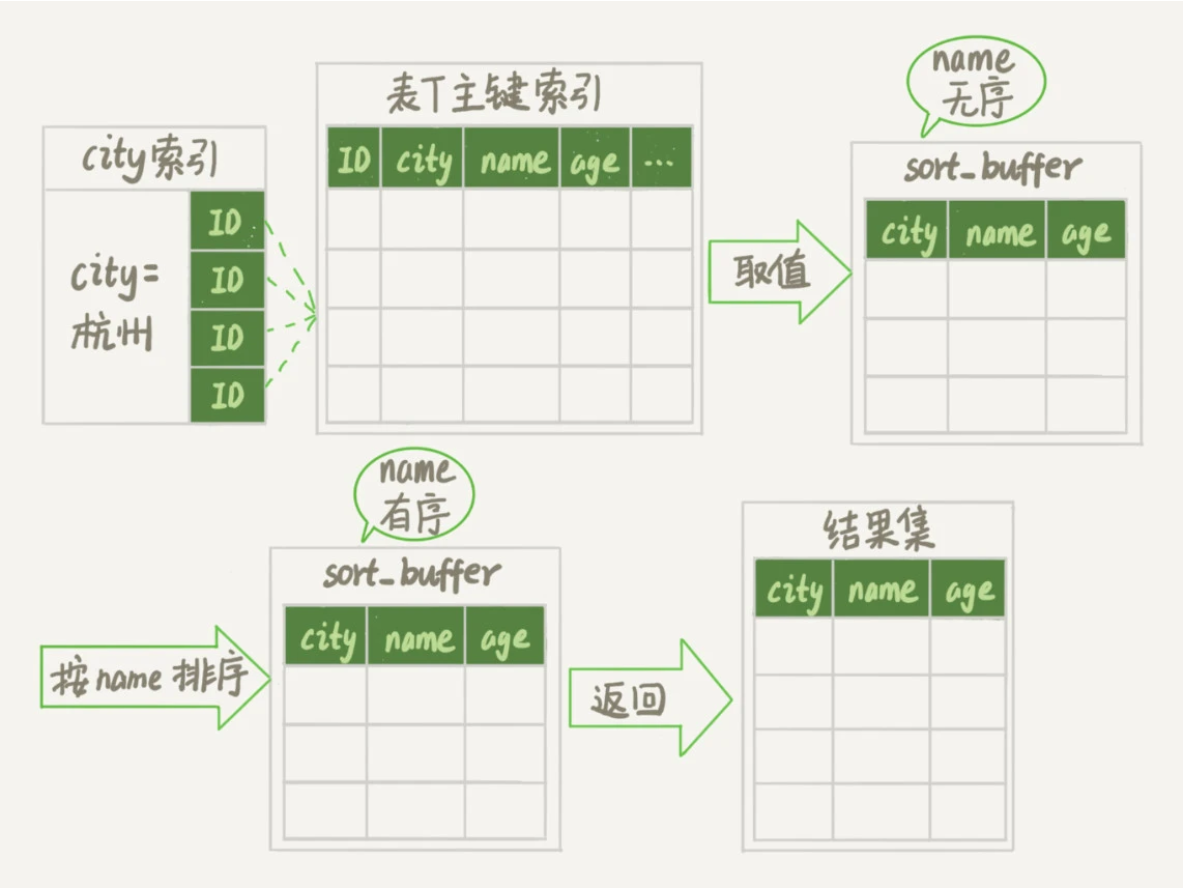
可以看到,排序操作是再 sort_buffer 内完成的,也有可能会使用到外部排序,取决于排序所需的内存和参数 sort_buffer_size。
sort_buffer_size:是MySQL为排序开辟的内存(sort_buffer)的大小。如果要排序的数据量小于sort_buffer_size,排序就在内存中完成。但如果排序数据量太大,内存放不下,则不得不利用磁盘临时文件辅助排序。
你可以用下面介绍的方法,来确定一个排序语句是否使用了临时文件。
1 | /* 打开optimizer_trace,只对本线程有效 */ |
这个方法是通过查看 OPTIMIZER_TRACE 的结果来确认的,你可以从 number_of_tmp_files中看到是否使用了临时文件。
1 | "filesort_summary":{ |
number_of_tmp_files表示的是,排序过程中使用的临时文件数。当number_of_tmp_files的值大于0,表示内存放不下了,就需要使用外部排序,外部排序一般使用归并排序算法。可以这么简单理解,MySQL将需要排序的数据分成n份,每一份单独排序后存在这些临时文件中。然后把这n个有序文件再合并成一个有序的大文件。
如果sort_buffer_size超过了需要排序的数据量的大小,number_of_tmp_files就是0,表示排序可以直接在内存中完成。
表中有4000条满足city=’杭州’的记录,所以你可以看到 examined_rows=4000,表示参与排序的行数是4000行。
sort_mode 里面的packed_additional_fields的意思是,排序过程对字符串做了“紧凑”处理。即使name字段的定义是varchar(16),在排序过程中还是要按照实际长度来分配空间的。
同时,最后一个查询语句select @b-@a 的返回结果是4000,表示整个执行过程只扫描了4000行。
这里需要注意的是,为了避免对结论造成干扰,我把internal_tmp_disk_storage_engine设置成MyISAM。否则,select @b-@a的结果会显示为4001。
这是因为查询OPTIMIZER_TRACE这个表时,需要用到临时表,而internal_tmp_disk_storage_engine的默认值是InnoDB。如果使用的是InnoDB引擎的话,把数据从临时表取出来的时候,会让Innodb_rows_read的值加1。
rowid排序
如果查询要返回的字段很多的话,那么sort_buffer里面要放的字段数太多,这样内存里能够同时放下的行数很少,要分成很多个临时文件,排序的性能会很差。
针对于排序的单行长度太大的问题,可以通过修改 max_length_for_sort_dat 的值来解决。
1 | SET max_length_for_sort_data = 16; |
max_length_for_sort_data 是如果单行的长度超过这个值,MySQL 就认为单行太大,需要换一个算法。
假设 city、name、age 这三个字段的定义总长度是36,新的算法放入sort_buffer的字段,只有要排序的列(即name字段)和主键id。
因此会比全字段排序多一个步骤,遍历排序结果,按照 id 值回到原表中取出 city,name,age 三个字段返回给客户端。
examined_rows的值还是4000,表示用于排序的数据是4000行。但是select @b-@a这个语句的值变成5000了。
因为这时候除了排序过程外,在排序完成后,还要根据id去原表取值。由于语句是limit 1000,因此会多读1000行。
1 | "filesort_summary":{ |
从OPTIMIZER_TRACE的结果中,还能看到另外两个信息也变了。
- sort_mode变成了<sort_key, rowid>,表示参与排序的只有name和id这两个字段。
- number_of_tmp_files变成10了,是因为这时候参与排序的行数虽然仍然是4000行,但是每一行都变小了,因此需要排序的总数据量就变小了,需要的临时文件也相应地变少了。
更佳实践:
- 建一个(city,name)的联合索引,就可以避免使用order by 排序时生成临时表并在临时表上排序了。原因是索引保证了从city这个索引取出来的行,天然按照name递增排序。
- 建一个(city,name,age)的覆盖索引,不但能避免多余的排序操作,还能避免回到主键索引上取数据的操作
随机数据的显示
有个英语学习App首页有一个随机显示单词的功能,也就是根据每个用户的级别有一个单词表,然后这个用户每次访问首页的时候,都会随机滚动显示三个单词。他们发现随着单词表变大,选单词这个逻辑变得越来越慢,甚至影响到了首页的打开速度。
现在,如果让你来设计这个SQL语句,你会怎么写呢?
为了便于理解,我对这个例子进行了简化:去掉每个级别的用户都有一个对应的单词表这个逻辑,直接就是从一个单词表中随机选出三个单词。
建表语句和初始化数据如下:
1 | mysql> CREATE TABLE `words` ( |
内存临时表
1 | mysql> select word from words order by rand() limit 3; |
我们先用explain命令来看看这个语句的执行情况。

图1 使用explain命令查看语句的执行情况
Extra字段显示Using temporary,表示的是需要使用临时表;Using filesort,表示的是需要执行排序操作。
因此这个Extra的意思就是,需要临时表,并且需要在临时表上排序。
对于InnoDB表来说,执行全字段排序会减少磁盘访问,因此会被优先选择。
对于内存表,回表过程只是简单地根据数据行的位置,直接访问内存得到数据,根本不会导致多访问磁盘。优化器会优先考虑的,就是用于排序的行越少越好了,所以,MySQL这时就会选择rowid排序。
这条语句的执行流程是这样的:
- 创建一个临时表。这个临时表使用的是memory引擎,表里有两个字段,第一个字段是double类型,为了后面描述方便,记为字段R,第二个字段是varchar(64)类型,记为字段W。并且,这个表没有建索引。
- 从words表中,按主键顺序取出所有的word值。对于每一个word值,调用rand()函数生成一个大于0小于1的随机小数,并把这个随机小数和word分别存入临时表的R和W字段中,到此,扫描行数是10000。
- 现在临时表有10000行数据了,接下来你要在这个没有索引的内存临时表上,按照字段R排序。
- 初始化 sort_buffer。sort_buffer中有两个字段,一个是double类型,另一个是整型。
- 从内存临时表中一行一行地取出R值和位置信息(我后面会和你解释这里为什么是“位置信息”),分别存入sort_buffer中的两个字段里。这个过程要对内存临时表做全表扫描,此时扫描行数增加10000,变成了20000。
- 在sort_buffer中根据R的值进行排序。注意,这个过程没有涉及到表操作,所以不会增加扫描行数。
- 排序完成后,取出前三个结果的位置信息,依次到内存临时表中取出word值,返回给客户端。这个过程中,访问了表的三行数据,总扫描行数变成了20003。
接下来,我们通过慢查询日志(slow log)来验证一下我们分析得到的扫描行数是否正确。
1 | # Query_time: 0.900376 Lock_time: 0.000347 Rows_sent: 3 Rows_examined: 20003 |
其中,Rows_examined:20003就表示这个语句执行过程中扫描了20003行,也就验证了我们分析得出的结论。
如果你创建的表没有主键,或者把一个表的主键删掉了,那么InnoDB会自己生成一个长度为6字节的rowid来作为主键。
这也就是排序模式里面,rowid名字的来历。实际上它表示的是:每个引擎用来唯一标识数据行的信息。
- 对于有主键的InnoDB表来说,这个rowid就是主键ID;
- 对于没有主键的InnoDB表来说,这个rowid就是由系统生成的;
- MEMORY引擎不是索引组织表。在这个例子里面,你可以认为它就是一个数组。因此,这个rowid其实就是数组的下标。
到这里,我来稍微小结一下:order by rand()使用了内存临时表,内存临时表排序的时候使用了rowid排序方法。
磁盘临时表
tmp_table_size这个配置限制了内存临时表的大小,默认值是16M。如果临时表大小超过了tmp_table_size,那么内存临时表就会转成磁盘临时表。
磁盘临时表使用的引擎默认是InnoDB,是由参数internal_tmp_disk_storage_engine控制的。
为了复现这个过程,把tmp_table_size设置成1024,把sort_buffer_size设置成 32768, 把 max_length_for_sort_data 设置成16。
1 | set tmp_table_size=1024; |
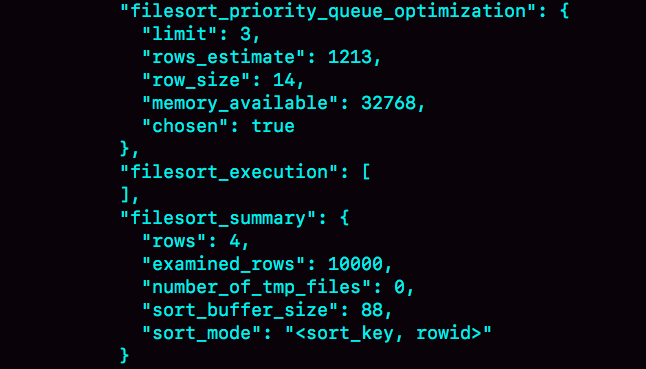
R字段存放的随机值就8个字节,rowid是6个字节,数据总行数是10000,这样算出来就有140000字节,超过了sort_buffer_size 定义的 32768字节了。但是,number_of_tmp_files的值居然是0。
此时采用是MySQL 5.6版本引入的一个新的排序算法,即:优先队列排序算法。filesort_priority_queue_optimization这个部分的chosen=true,就表示使用了优先队列排序算法
为什么不使用归并排序算法呢?
原因是我们的 sql 语句只需要取R值最小的3个rowid,使用归并排序需要将10000行数据排好,浪费很多计算量。
而优先队列算法,就可以精确地只得到三个最小值,执行流程如下:
- 对于这10000个准备排序的(R,rowid),先取前三行,构造成一个堆;
(对数据结构印象模糊的同学,可以先设想成这是一个由三个元素组成的数组)
取下一个行(R’,rowid’),跟当前堆里面最大的R比较,如果R’小于R,把这个(R,rowid)从堆中去掉,换成(R’,rowid’);
重复第2步,直到第10000个(R’,rowid’)完成比较。
整个排序过程中,为了最快地拿到当前堆的最大值,总是保持最大值在堆顶,因此这是一个最大堆。
随机排序算法
要随机取3个word值,你可以这么做:
- 取得整个表的行数,记为C;
- 根据相同的随机方法得到Y1、Y2、Y3;
- 再执行三个limit Y, 1语句得到三行数据。
下面这段代码,就是上面流程的执行语句的序列。
1 | mysql> select count(*) into @C from t; |
为什么这个算法比order by rand()的代价小很多?
因为进行limit获取数据的时候是根据主键排序获取的,主键天然索引排序。获取到第9999条的数据也远比order by rand()方法的组成临时表R字段排序再获取rowid代价小的多。
上面的随机算法3的总扫描行数是 C+(Y1+1)+(Y2+1)+(Y3+1),实际上它还是可以继续优化,来进一步减少扫描行数的。
我的问题是,如果你是这个需求的开发人员,你会怎么做,来减少扫描行数呢?说说你的方案,并说明你的方案需要的扫描行数。
取Y1、Y2和Y3里面最大的一个数,记为M,最小的一个数记为N,然后执行下面这条SQL语句:
1 | mysql> select * from t limit N, M-N+1; |
再加上取整个表总行数的C行,这个方案的扫描行数总共只需要C+M+1行。
当然也可以先取回id值,在应用中确定了三个id值以后,再执行三次where id=X的语句也是可以的。
Kill 线程
实现上,当用户执行kill query thread_id_B时,MySQL里处理kill命令的线程做了两件事:
- 把session B的运行状态改成THD::KILL_QUERY(将变量killed赋值为THD::KILL_QUERY);
- 给session B的执行线程发一个信号。让session B退出等待,来处理这个THD::KILL_QUERY状态。
语句的执行终止过程:
- 一个语句执行过程中有多处“埋点”,在这些“埋点”的地方判断线程状态,如果发现线程状态是THD::KILL_QUERY,才开始进入语句终止逻辑;
- 如果处于等待状态,必须是一个可以被唤醒的等待,否则根本不会执行到“埋点”处;
- 语句从开始进入终止逻辑,到终止逻辑完全完成,是有一个过程的。
为什么在执行kill query命令时,这条语句不像第一个例子的update语句一样退出呢?
第一类线程没有执行到判断线程状态的逻辑。跟这种情况相同的,还有由于IO压力过大,读写IO的函数一直无法返回,导致不能及时判断线程的状态。
另一类情况是,终止逻辑耗时较长。这时候,从show processlist结果上看也是Command=Killed,需要等到终止逻辑完成,语句才算真正完成。这类情况,比较常见的场景有以下几种:
- 超大事务执行期间被kill。这时候,回滚操作需要对事务执行期间生成的所有新数据版本做回收操作,耗时很长。
- 大查询回滚。如果查询过程中生成了比较大的临时文件,加上此时文件系统压力大,删除临时文件可能需要等待IO资源,导致耗时较长。
- DDL命令执行到最后阶段,如果被kill,需要删除中间过程的临时文件,也可能受IO资源影响耗时较久。
如果直接在客户端通过Ctrl+C命令,是不是就可以直接终止线程呢?
答案是,不可以。
这里有一个误解,其实在客户端的操作只能操作到客户端的线程,客户端和服务端只能通过网络交互,是不可能直接操作服务端线程的。
而由于MySQL是停等协议,所以这个线程执行的语句还没有返回的时候,再往这个连接里面继续发命令也是没有用的。实际上,执行Ctrl+C的时候,是MySQL客户端另外启动一个连接,然后发送一个kill query 命令。
如果库里面的表特别多,连接就会很慢。这是什么原因?
每个客户端在和服务端建立连接的时候,需要做的事情就是TCP握手、用户校验、获取权限。但这几个操作,显然跟库里面表的个数无关。
当使用默认参数连接的时候,MySQL客户端会提供一个本地库名和表名补全的功能。为了实现这个功能,客户端在连接成功后,需要多做一些操作:
- 执行show databases;
- 切到db1库,执行show tables;
- 把这两个命令的结果用于构建一个本地的哈希表。
在这些操作中,最花时间的就是第三步在本地构建哈希表的操作。所以,当一个库中的表个数非常多的时候,这一步就会花比较长的时间。
如果在连接命令中加上-A,就可以关掉这个自动补全的功能,然后客户端就可以快速返回了。
这里自动补全的效果就是,你在输入库名或者表名的时候,输入前缀,可以使用Tab键自动补全表名或者显示提示。
实际使用中,如果你自动补全功能用得并不多,我建议你每次使用的时候都默认加-A。
如果你碰到一个被killed的事务一直处于回滚状态,你认为是应该直接把MySQL进程强行重启,还是应该让它自己执行完成呢?为什么呢?
因为重启之后该做的回滚动作还是不能少的,所以从恢复速度的角度来说,应该让它自己结束。
当然,如果这个语句可能会占用别的锁,或者由于占用IO资源过多,从而影响到了别的语句执行的话,就需要先做主备切换,切到新主库提供服务。
切换之后别的线程都断开了连接,自动停止执行。接下来还是等它自己执行完成。
全表扫描
对 server 层影响
假设,我们现在要对一个200G的InnoDB表db1. t,执行一个全表扫描。要把扫描结果保存在客户端,会使用类似这样的命令:
1 | mysql -h$host -P$port -u$user -p$pwd -e "select * from db1.t" > $target_file |
InnoDB的数据是保存在主键索引上的,所以全表扫描实际上是直接扫描表t的主键索引。这条查询语句由于没有其他的判断条件,所以查到的每一行都可以直接放到结果集里面,然后返回给客户端。
取数据和发数据的流程是这样的:
- 获取一行,写到net_buffer中。这块内存的大小是由参数net_buffer_length定义的,默认是16k。
- 重复获取行,直到net_buffer写满,调用网络接口发出去。
- 如果发送成功,就清空net_buffer,然后继续取下一行,并写入net_buffer。
- 如果发送函数返回EAGAIN或WSAEWOULDBLOCK,就表示本地网络栈(socket send buffer)写满了,进入等待。直到网络栈重新可写,再继续发送。
MySQL是“边读边发的”,如果客户端接收得慢,会导致MySQL服务端由于结果发不出去,这个事务的执行时间变长。
如果客户端使用–quick参数,会使用mysql_use_result方法。这个方法是读一行处理一行。你可以想象一下,假设有一个业务的逻辑比较复杂,每读一行数据以后要处理的逻辑如果很慢,就会导致客户端要过很久才会去取下一行数据,就很有可能看到State的值一直处于“Sending to client”。
对于正常的线上业务来说,如果一个查询的返回结果不会很多的话,我都建议你使用mysql_store_result这个接口,直接把查询结果保存到本地内存。
如果你在自己负责维护的MySQL里看到很多个线程都处于“Sending to client”这个状态,就意味着你要让业务开发同学优化查询结果,并评估这么多的返回结果是否合理。
而如果要快速减少处于这个状态的线程的话,将net_buffer_length参数设置为一个更大的值是一个可选方案。
仅当一个线程处于“等待客户端接收结果”的状态,才会显示”Sending to client”;而如果显示成“Sending data”,它的意思只是“正在执行”。
对 InnoDB 的影响
Buffer Pool对查询的加速效果,依赖于一个重要的指标,即:内存命中率 Buffer pool hit rate。InnoDB Buffer Pool的大小是由参数 innodb_buffer_pool_size确定的,一般建议设置成可用物理内存的60%~80%。
在大约十年前,单机的数据量是上百个G,而物理内存是几个G;现在虽然很多服务器都能有128G甚至更高的内存,但是单机的数据量却达到了T级别。
所以,innodb_buffer_pool_size小于磁盘的数据量是很常见的。如果一个 Buffer Pool满了,而又要从磁盘读入一个数据页,那肯定是要淘汰一个旧数据页的。
InnoDB内存管理用的是最近最少使用 (Least Recently Used, LRU)算法,这个算法的核心就是淘汰最久未使用的数据。但是实际上,InnoDB不是直接使用 LRU 算法的,因为如果完全按照这个算法,当业务上需要扫描一个200G的历史数据表(平时没有业务访问),就会使得当前 Buffer Pool 里的数据全部淘汰掉,Buffer Pool 的内存命中率下降,磁盘压力增加,SQL语句响应变慢。
实际上,InnoDB对LRU算法做了改进。在InnoDB实现上,按照5:3的比例把整个LRU链表分成了young区域和old区域。
图中状态1,要访问数据页P3,由于P3在young区域,因此和优化前的LRU算法一样,将其移到链表头部,变成状态2。
之后要访问一个新的不存在于当前链表的数据页,这时候依然是淘汰掉数据页Pm,但是新插入的数据页Px,是放在LRU_old处。
处于old区域的数据页,每次被访问的时候都要做下面这个判断:
- 若这个数据页在LRU链表中存在的时间超过了1秒,就把它移动到链表头部;
- 如果这个数据页在LRU链表中存在的时间短于1秒,位置保持不变。1秒这个时间,是由参数innodb_old_blocks_time控制的。其默认值是1000,单位毫秒。
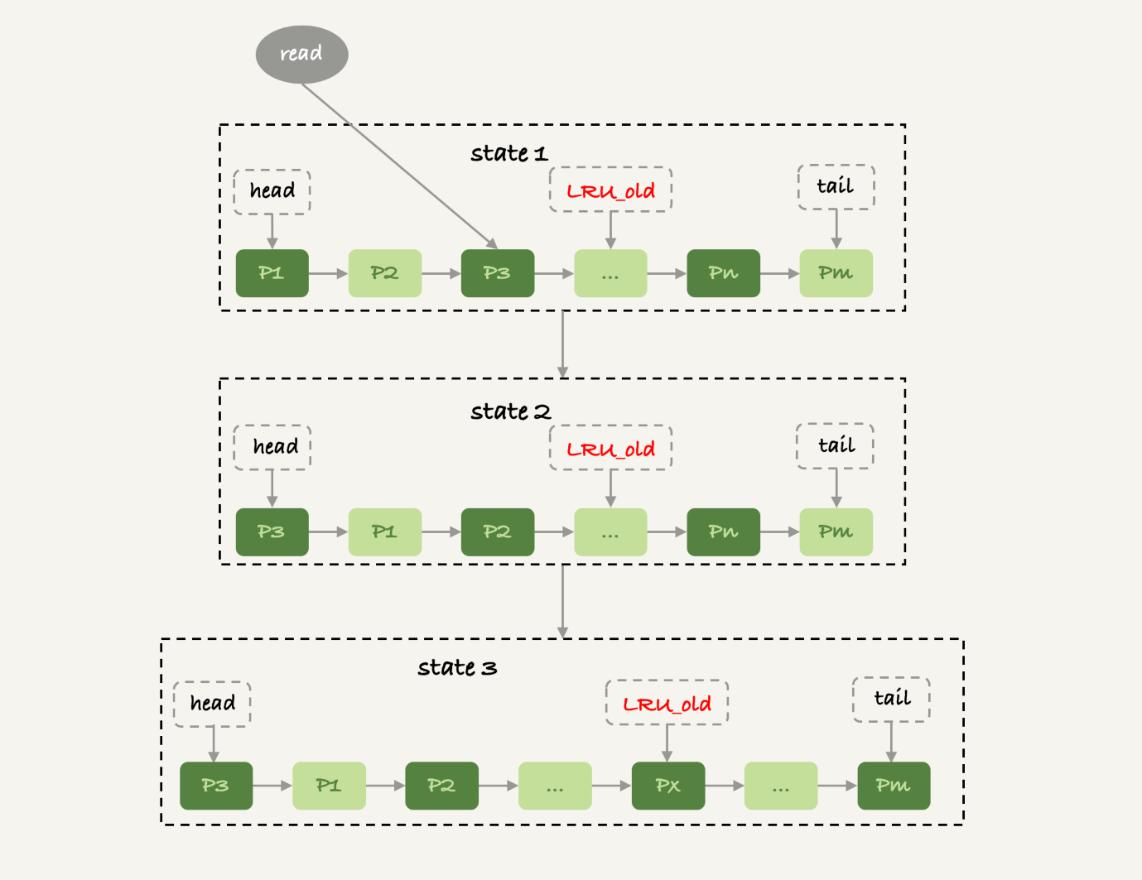
扫描过程中,需要新插入的数据页,都被放到old区域;
一个数据页里面有多条记录,这个数据页会被多次访问到,但由于是顺序扫描,这个数据页第一次被访问和最后一次被访问的时间间隔不会超过1秒,因此还是会被保留在old区域;
再继续扫描后续的数据,之前的这个数据页之后也不会再被访问到,于是始终没有机会移到链表头部(也就是young区域),很快就会被淘汰出去
Join 执行原理
1 | CREATE TABLE `t2` ( |
可以看到,这两个表都有一个主键索引id和一个索引a,字段b上无索引。存储过程idata()往表t2里插入了1000行数据,在表t1里插入的是100行数据。
Index Nested-Loop Join
我们来看一下这个语句:
1 | select * from t1 straight_join t2 on (t1.a=t2.a); |
可以看到,在这条语句里,被驱动表t2的字段a上有索引,join过程用上了这个索引,因此这个语句的执行流程是这样的:先遍历表t1,然后根据从表t1中取出的每行数据中的a值,去表t2中查找满足条件的记录。
在这个流程里:
- 对驱动表t1做了全表扫描,这个过程需要扫描100行;
- 而对于每一行R,根据a字段去表t2查找,走的是树搜索过程。由于我们构造的数据都是一一对应的,因此每次的搜索过程都只扫描一行,也是总共扫描100行;
- 所以,整个执行流程,总扫描行数是200。
在这个join语句执行过程中,驱动表是走全表扫描,而被驱动表是走树搜索。
假设被驱动表的行数是M。每次在被驱动表查一行数据,要先搜索索引a,再搜索主键索引。每次搜索一棵树近似复杂度是以2为底的M的对数,记为log2M,所以在被驱动表上查一行的时间复杂度是 2*log2M。
假设驱动表的行数是N,执行过程就要扫描驱动表N行,然后对于每一行,到被驱动表上匹配一次。
因此整个执行过程,近似复杂度是 N + N2log2M。显然,N对扫描行数的影响更大,因此应该让小表来做驱动表。
Block Nested-Loop Join
这时候,被驱动表上没有可用的索引,算法的流程是这样的:
- 把表t1的数据读入线程内存join_buffer中,由于我们这个语句中写的是select *,因此是把整个表t1放入了内存;
- 扫描表t2,把表t2中的每一行取出来,跟join_buffer中的数据做对比,满足join条件的,作为结果集的一部分返回。
可以看到,在这个过程中,对表t1和t2都做了一次全表扫描,因此总的扫描行数是1100。由于join_buffer是以无序数组的方式组织的,因此对表t2中的每一行,都要做100次判断,总共需要在内存中做的判断次数是:100*1000=10万次。
假设小表的行数是N,大表的行数是M,那么在这个算法里:
- 两个表都做一次全表扫描,所以总的扫描行数是M+N;
- 内存中的判断次数是M*N。
如果表t1是一张大表,join_buffer的 join_buffer_size 不够怎么办?
分段放。
- 扫描表t1,顺序读取数据行放入join_buffer中,放完第88行join_buffer满了,继续第2步;
- 扫描表t2,把t2中的每一行取出来,跟join_buffer中的数据做对比,满足join条件的,作为结果集的一部分返回;
- 清空join_buffer;
- 继续扫描表t1,顺序读取最后的12行数据放入join_buffer中,继续执行第2步。
假设,驱动表的数据行数是N,需要分K段才能完成算法流程,被驱动表的数据行数是M。
注意,这里的K不是常数,N越大K就会越大,因此把K表示为λ*N,显然λ的取值范围是(0,1)。
所以,在这个算法的执行过程中:
- 扫描行数是 N+λNM;
- 内存判断 N*M次。
考虑到扫描行数,在M和N大小确定的情况下,N小一些,整个算式的结果会更小。那么,N固定的时候,什么参数会影响K的大小呢?(也就是λ的大小)答案是join_buffer_size。join_buffer_size越大,一次可以放入的行越多,分成的段数也就越少,对被驱动表的全表扫描次数就越少。
能不能使用join语句?
- 如果可以使用Index Nested-Loop Join算法,也就是说可以用上被驱动表上的索引,其实是没问题的;
- 如果使用Block Nested-Loop Join算法,扫描行数就会过多。尤其是在大表上的join操作,这样可能要扫描被驱动表很多次,会占用大量的系统资源。所以这种join尽量不要用。
如果要使用join,应该选择大表做驱动表还是选择小表做驱动表?
- 如果是Index Nested-Loop Join算法,应该选择小表做驱动表;
- 如果是Block Nested-Loop Join算法:
- 在join_buffer_size足够大的时候,是一样的;
- 在join_buffer_size不够大的时候(这种情况更常见),应该选择小表做驱动表。
在决定哪个表做驱动表的时候,应该是两个表按照各自的条件过滤,过滤完成之后,计算参与join的各个字段的总数据量,数据量小的那个表,就是“小表”,应该作为驱动表。
Simple Nested Loop Join
Simple Nested Loop Join算法的执行逻辑是:顺序取出驱动表中的每一行数据,到被驱动表去做全表扫描匹配,匹配成功则作为结果集的一部分返回。
为什么Simple Nested Loop Join算法和BNL算法性能差距那么大?
- 在对被驱动表做全表扫描的时候,如果数据没有在Buffer Pool中,就需要等待这部分数据从磁盘读入;
从磁盘读入数据到内存中,会影响正常业务的Buffer Pool命中率,而且这个算法天然会对被驱动表的数据做多次访问,更容易将这些数据页放到Buffer Pool的头部 - 即使被驱动表数据都在内存中,每次查找“下一个记录的操作”,都是类似指针操作。而join_buffer中是数组,遍历的成本更低。
Join 优化方法
Multi-Range Read 优化
因为大多数的数据都是按照主键递增顺序插入得到的,所以我们可以认为,如果按照主键的递增顺序查询的话,对磁盘的读比较接近顺序读,能够提升读性能。
这,就是MRR优化的设计思路。此时,语句的执行流程变成了这样:
- 根据索引a,定位到满足条件的记录,将id值放入read_rnd_buffer中;
- 将read_rnd_buffer中的id进行递增排序;
- 排序后的id数组,依次到主键id索引中查记录,并作为结果返回。
read_rnd_buffer的大小是由read_rnd_buffer_size参数控制的。如果步骤1中,read_rnd_buffer放满了,就会先执行完步骤2和3,然后清空read_rnd_buffer。之后继续找索引a的下个记录,并继续循环。
如果你想要稳定地使用MRR优化的话,需要设置set optimizer_switch="mrr_cost_based=off"。
Batched Key Access
从驱动表t1,一次性多拿些行写入到 join_buffer,再到被驱动表t2去做join。
如果要使用BKA优化算法的话,你需要在执行SQL语句之前,先设置
1 | set optimizer_switch='mrr=on,mrr_cost_based=off,batched_key_access=on'; |
其中,前两个参数的作用是要启用MRR。这么做的原因是,BKA算法的优化要依赖于MRR。
BNL算法性能问题
如果被驱动表是一个大表,并且是一个冷数据表,除了查询过程中可能会导致IO压力大以外,你觉得对这个MySQL服务还有什么更严重的影响吗?
如果一个使用BNL算法的join语句,多次扫描一个冷表,而且这个语句执行时间超过1秒,就会在再次扫描冷表的时候,把冷表的数据页移到LRU链表头部。
这种情况对应的,是冷表的数据量小于整个Buffer Pool的3/8,能够完全放入old区域的情况。
如果这个冷表很大,就会出现另外一种情况:业务正常访问的数据页,没有机会进入young区域。
BNL算法对系统的影响主要包括三个方面:
- 可能会多次扫描被驱动表,占用磁盘IO资源;
- 判断join条件需要执行M*N次对比(M、N分别是两张表的行数),如果是大表就会占用非常多的CPU资源;
- 可能会导致Buffer Pool的热数据被淘汰,影响内存命中率。
BNL算法转BKA
一些情况下,我们可以直接在被驱动表上建索引,这时就可以直接转成BKA算法了。
但是,有时候你确实会碰到一些不适合在被驱动表上建索引的情况。比如下面这个语句:
1 | select * from t1 join t2 on (t1.b=t2.b) where t2.b>=1 and t2.b<=2000; |
表t2中插入了100万行数据,但是经过where条件过滤后,需要参与join的只有2000行数据。如果这条语句同时是一个低频的SQL语句,那么再为这个语句在表t2的字段b上创建一个索引就很浪费了。
如果使用BNL算法来join的话,这个语句的执行流程是这样的:
- 把表t1的所有字段取出来,存入join_buffer中。这个表只有1000行,join_buffer_size默认值是256k,可以完全存入。
- 扫描表t2,取出每一行数据跟join_buffer中的数据进行对比,
- 如果不满足t1.b=t2.b,则跳过;
- 如果满足t1.b=t2.b, 再判断其他条件,也就是是否满足t2.b处于[1,2000]的条件,如果是,就作为结果集的一部分返回,否则跳过。
对于表t2的每一行,判断join是否满足的时候,都需要遍历join_buffer中的所有行。因此判断等值条件的次数是1000*100万=10亿次,这个判断的工作量很大。
这时候,我们可以考虑使用临时表。使用临时表的大致思路是:
- 把表t2中满足条件的数据放在临时表tmp_t中;
- 为了让join使用BKA算法,给临时表tmp_t的字段b加上索引;
- 让表t1和tmp_t做join操作。
此时,对应的SQL语句的写法如下:
1 | create temporary table temp_t(id int primary key, a int, b int, index(b))engine=innodb; |
接下来,我们一起看一下这个过程的消耗:
- 执行insert语句构造temp_t表并插入数据的过程中,对表t2做了全表扫描,这里扫描行数是100万。
- 之后的join语句,扫描表t1,这里的扫描行数是1000;join比较过程中,做了1000次带索引的查询。相比于优化前的join语句需要做10亿次条件判断来说,这个优化效果还是很明显的。
其实这里使用内存临时表的效果更好,原因有三个:
- 相比于InnoDB表,使用内存表不需要写磁盘,往表temp_t的写数据的速度更快;
- 索引b使用hash索引,查找的速度比B-Tree索引快;
- 临时表数据只有2000行,占用的内存有限。
将临时表t1改成内存临时表,并且在字段b上创建一个hash索引。
1 | create temporary table temp_t(id int primary key, a int, b int, index (b))engine=memory; |
扩展-hash join
如果join_buffer里面维护的不是一个无序数组,而是一个哈希表的话,那么就不是10亿次判断,而是100万次hash查找。这样的话,整条语句的执行速度就快多了。
这个优化思路,我们可以自己实现在业务端。实现流程大致如下:
select * from t1;取得表t1的全部1000行数据,在业务端存入一个hash结构,比如C++里的set、PHP的dict这样的数据结构。select * from t2 where b>=1 and b<=2000;获取表t2中满足条件的2000行数据。- 把这2000行数据,一行一行地取到业务端,到hash结构的数据表中寻找匹配的数据。满足匹配的条件的这行数据,就作为结果集的一行。
现在有一个三个表join的需求,假设这三个表的表结构如下:
1 | CREATE TABLE `t1` ( |
语句的需求实现如下的join逻辑:
1 | select * from t1 join t2 on(t1.a=t2.a) join t3 on (t2.b=t3.b) where t1.c>=X and t2.c>=Y and t3.c>=Z; |
现在为了得到最快的执行速度,如果让你来设计表t1、t2、t3上的索引,来支持这个join语句,你会加哪些索引呢?
同时,如果我希望你用straight_join来重写这个语句,配合你创建的索引,你就需要安排连接顺序,你主要考虑的因素是什么呢?
答:第一原则是要尽量使用BKA算法。需要注意的是,使用BKA算法的时候,并不是“先计算两个表join的结果,再跟第三个表join”,而是直接嵌套查询的。
具体实现是:在t1.c>=X、t2.c>=Y、t3.c>=Z这三个条件里,选择一个经过过滤以后,数据最少的那个表,作为第一个驱动表。此时,可能会出现如下两种情况。
第一种情况,如果选出来是表t1或者t3,那剩下的部分就固定了。
- 如果驱动表是t1,则连接顺序是t1->t2->t3,要在被驱动表字段创建上索引,也就是t2.a 和 t3.b上创建索引;
- 如果驱动表是t3,则连接顺序是t3->t2->t1,需要在t2.b 和 t1.a上创建索引。
同时,我们还需要在第一个驱动表的字段c上创建索引。
第二种情况是,如果选出来的第一个驱动表是表t2的话,则需要评估另外两个条件的过滤效果。
总之,整体的思路就是,尽量让每一次参与join的驱动表的数据集,越小越好,因为这样我们的驱动表就会越小。
临时表
临时表和内存表的区别:
- 内存表,指的是使用Memory引擎的表,建表语法是create table … engine=memory。这种表的数据都保存在内存里,系统重启的时候会被清空,但是表结构还在。除了这两个特性看上去比较“奇怪”外,从其他的特征上看,它就是一个正常的表。
- 而临时表,可以使用各种引擎类型 。如果是使用InnoDB引擎或者MyISAM引擎的临时表,写数据的时候是写到磁盘上的。当然,临时表也可以使用Memory引擎。
为什么临时表可以重名
1 | create temporary table temp_t(id int primary key)engine=innodb; |
MySQL要给这个InnoDB表创建一个frm文件保存表结构定义,这个frm文件放在临时文件目录下,文件名的后缀是.frm,前缀是“#sql{进程id}_{线程id}_序列号”。你可以使用select @@tmpdir命令,来显示实例的临时文件目录。
而关于表中数据的存放方式,在不同的MySQL版本中有着不同的处理方式:
- 在5.6以及之前的版本里,MySQL会在临时文件目录下创建一个相同前缀、以.ibd为后缀的文件,用来存放数据文件;
- 而从 5.7版本开始,MySQL引入了一个临时文件表空间,专门用来存放临时文件的数据。因此,我们就不需要再创建ibd文件了。
MySQL维护数据表,除了物理上要有文件外,内存里面也有一套机制区别不同的表,每个表都对应一个table_def_key。一个普通表的table_def_key的值是由“库名+表名”得到的,而临时表的 table_def_key 是由 “server_id+thread_id+库名+表名”。
每个线程都维护了自己的临时表链表。这样每次session内操作表的时候,先遍历链表,检查是否有这个名字的临时表,如果有就优先操作临时表,如果没有再操作普通表;在session结束的时候,对链表里的每个临时表,执行 “DROP TEMPORARY TABLE +表名”操作。
临时表和主备复制
在主库上执行下面这个语句序列:
1 | create table t_normal(id int primary key, c int)engine=innodb;/*Q1*/ |
如果关于临时表的操作都不记录,那么在备库就只有create table t_normal表和insert into t_normal select * from temp_t这两个语句的binlog日志,备库在执行到insert into t_normal的时候,就会报错“表temp_t不存在”。
如果把binlog设置为row格式,在记录insert into t_normal的binlog时,记录的是这个操作的数据,即:write_row event里面记录的逻辑是“插入一行数据(1,1)”。也就是说,只在binlog_format=statment/mixed 的时候,binlog中才会记录临时表的操作。
这种情况下,创建临时表的语句会传到备库执行,因此备库的同步线程就会创建这个临时表。主库在线程退出的时候,会自动删除临时表,但是备库同步线程是持续在运行的。所以,这时候我们就需要在主库上再写一个DROP TEMPORARY TABLE传给备库执行。
MySQL在记录binlog的时候,会把主库执行这个语句的线程id写到binlog中。这样,在备库的应用线程就能够知道执行每个语句的主库线程id,并利用这个线程id来构造临时表的table_def_key:
- session A的临时表t1,在备库的table_def_key就是:库名+t1+“M的serverid”+“session A的thread_id”;
- session B的临时表t1,在备库的table_def_key就是 :库名+t1+“M的serverid”+“session B的thread_id”。
由于table_def_key不同,所以这两个表在备库的应用线程里面是不会冲突的。
我们可以使用alter table语法修改临时表的表名,而不能使用rename语法。你知道这是什么原因吗?
在实现上,执行rename table语句的时候,要求按照“库名/表名.frm”的规则去磁盘找文件,但是临时表在磁盘上的frm文件是放在tmpdir目录下的,并且文件名的规则是“#sql{进程id}_{线程id}_序列号.frm”,因此会报“找不到文件名”的错误。
假设你刚刚接手的一个数据库上,真的发现了一个内存表。备库重启之后肯定是会导致备库的内存表数据被清空,进而导致主备同步停止。这时,最好的做法是将它修改成InnoDB引擎表。
假设当时的业务场景暂时不允许你修改引擎,你可以加上什么自动化逻辑,来避免主备同步停止呢?
那么就把备库的内存表引擎先都改成InnoDB。对于每个内存表,执行
1 | set sql_log_bin=off; |
这样就能避免备库重启的时候,数据丢失的问题。
由于主库重启后,会往binlog里面写“delete from tbl_name”,这个命令传到备库,备库的同名的表数据也会被清空。
因此,就不会出现主备同步停止的问题。
如果由于主库异常重启,触发了HA,这时候我们之前修改过引擎的备库变成了主库。而原来的主库变成了新备库,在新备库上把所有的内存表(这时候表里没数据)都改成InnoDB表。
所以,如果我们不能直接修改主库上的表引擎,可以配置一个自动巡检的工具,在备库上发现内存表就把引擎改了。
Union执行流程
1 | reate table t1(id int primary key, a int, b int, index(a)); |
然后,我们执行下面这条语句:
1 | (select 1000 as f) union (select id from t1 order by id desc limit 2); |
这条语句用到了union,它的语义是,取这两个子查询结果的并集。并集的意思就是这两个集合加起来,重复的行只保留一行。
这个语句的执行流程是这样的:
- 创建一个内存临时表,这个临时表只有一个整型字段f,并且f是主键字段。
- 执行第一个子查询,得到1000这个值,并存入临时表中。
- 执行第二个子查询:
- 拿到第一行id=1000,试图插入临时表中。但由于1000这个值已经存在于临时表了,违反了唯一性约束,所以插入失败,然后继续执行;
- 取到第二行id=999,插入临时表成功。
- 从临时表中按行取出数据,返回结果,并删除临时表,结果中包含两行数据分别是1000和999。
这里的内存临时表起到了暂存数据的作用,而且计算过程还用上了临时表主键id的唯一性约束,实现了union的语义。
Group by 执行流程
1 | select id%10 as m, count(*) as c from t1 group by m; |
这个语句的逻辑是把表t1里的数据,按照 id%10 进行分组统计,并按照m的结果排序后输出。
这个语句的执行流程是这样的:
- 创建内存临时表,表里有两个字段m和c,主键是m;
- 扫描表t1的索引a,依次取出叶子节点上的id值,计算id%10的结果,记为x;
- 如果临时表中没有主键为x的行,就插入一个记录(x,1);
- 如果表中有主键为x的行,就将x这一行的c值加1;
- 遍历完成后,再根据字段m做排序,得到结果集返回给客户端。
如果你的需求并不需要对结果进行排序,那你可以在SQL语句末尾增加order by null,也就是改成:
1 | select id%10 as m, count(*) as c from t1 group by m order by null; |
这个例子里由于临时表只有10行,内存可以放得下,因此全程只使用了内存临时表。但是,内存临时表的大小是有限制的,参数tmp_table_size就是控制这个内存大小的,默认是16M。
如果我执行下面这个语句序列:
1 | set tmp_table_size=1024; |
把内存临时表的大小限制为最大1024字节,并把语句改成id % 100,这样返回结果里有100行数据。但是,这时的内存临时表大小不够存下这100行数据,也就是说,执行过程中会发现内存临时表大小到达了上限(1024字节)。
那么,这时候就会把内存临时表转成磁盘临时表,磁盘临时表默认使用的引擎是InnoDB。
Group by 优化方法
索引
不论是使用内存临时表还是磁盘临时表,group by逻辑都需要构造一个带唯一索引的表,执行代价都是比较高的。
group by的语义逻辑,是统计不同的值出现的个数。但是,由于每一行的id%100的结果是无序的,所以我们就需要有一个临时表,来记录并统计结果。
InnoDB的索引,就可以满足这个输入有序的条件。
在MySQL 5.7版本支持了generated column机制,用来实现列数据的关联更新。你可以用下面的方法创建一个列z,然后在z列上创建一个索引(如果是MySQL 5.6及之前的版本,你也可以创建普通列和索引,来解决这个问题)。
1 | alter table t1 add column z int generated always as(id % 100), add index(z); |
直接排序
在group by语句中加入SQL_BIG_RESULT这个提示(hint),就可以告诉优化器:这个语句涉及的数据量很大,请直接用磁盘临时表。
因此,下面这个语句
1 | select SQL_BIG_RESULT id%100 as m, count(*) as c from t1 group by m; |
的执行流程就是这样的:
- 初始化sort_buffer,确定放入一个整型字段,记为m;
- 扫描表t1的索引a,依次取出里面的id值, 将 id%100的值存入sort_buffer中;
- 扫描完成后,对sort_buffer的字段m做排序(如果sort_buffer内存不够用,就会利用磁盘临时文件辅助排序);
- 排序完成后,就得到了一个有序数组。
根据有序数组,得到数组里面的不同值,以及每个值的出现次数。
MySQL什么时候会使用内部临时表?
- 如果语句执行过程可以一边读数据,一边直接得到结果,是不需要额外内存的,否则就需要额外的内存,来保存中间结果;
- join_buffer是无序数组,sort_buffer是有序数组,临时表是二维表结构;
- 如果执行逻辑需要用到二维表特性,就会优先考虑使用临时表。比如我们的例子中,union需要用到唯一索引约束, group by还需要用到另外一个字段来存累积计数。
group by 优化方法总结:
- 如果对group by语句的结果没有排序要求,要在语句后面加 order by null;
- 尽量让group by过程用上表的索引,确认方法是explain结果里没有Using temporary 和 Using filesort;
- 如果group by需要统计的数据量不大,尽量只使用内存临时表;也可以通过适当调大tmp_table_size参数,来避免用到磁盘临时表;
- 如果数据量实在太大,使用SQL_BIG_RESULT这个提示,来告诉优化器直接使用排序算法得到group by的结果。
自增主键
自增主键存储位置
实际上,表的结构定义存放在后缀名为.frm的文件中,但是并不会保存自增值。
不同的引擎对于自增值的保存策略不同。
- MyISAM引擎的自增值保存在数据文件中。
- InnoDB引擎的自增值,其实是保存在了内存里,并且到了MySQL 8.0版本后,才有了“自增值持久化”的能力,也就是才实现了“如果发生重启,表的自增值可以恢复为MySQL重启前的值”,具体情况是:
- 在MySQL 5.7及之前的版本,自增值保存在内存里,并没有持久化。每次重启后,第一次打开表的时候,都会去找自增值的最大值max(id),然后将max(id)+1作为这个表当前的自增值。
也就是说,MySQL重启可能会修改一个表的AUTO_INCREMENT的值。 - 在MySQL 8.0版本,将自增值的变更记录在了redo log中,重启的时候依靠redo log恢复重启之前的值。
- 在MySQL 5.7及之前的版本,自增值保存在内存里,并没有持久化。每次重启后,第一次打开表的时候,都会去找自增值的最大值max(id),然后将max(id)+1作为这个表当前的自增值。
自增值修改机制
在插入一行数据的时候,自增值的行为如下:
- 如果插入数据时id字段指定为0、null 或未指定值,那么就把这个表当前的 AUTO_INCREMENT值填到自增字段;
- 如果插入数据时id字段指定了具体的值,就直接使用语句里指定的值。
根据要插入的值和当前自增值的大小关系,自增值的变更结果也会有所不同。假设,某次要插入的值是X,当前的自增值是Y。
- 如果X<Y,那么这个表的自增值不变;
- 如果X≥Y,就需要把当前自增值修改为新的自增值 + 1。
auto_increment_offset 和 auto_increment_increment是两个系统参数,分别用来表示自增的初始值和步长,默认值都是1。
备注:在一些场景下,使用的就不全是默认值。比如,双M的主备结构里要求双写的时候,我们就可能会设置成auto_increment_increment=2,让一个库的自增id都是奇数,另一个库的自增id都是偶数,避免两个库生成的主键发生冲突。
自增值修改时机
唯一键冲突
表t里面已经有了(1,1,1)这条记录,这时我再执行一条插入数据命令:
1 | insert into t values(null, 1, 1); |
- 执行器调用InnoDB引擎接口写入一行,传入的这一行的值是(0,1,1);
- InnoDB发现用户没有指定自增id的值,获取表t当前的自增值2;
- 将传入的行的值改成(2,1,1);
- 将表的自增值改成3;
- 继续执行插入数据操作,由于已经存在c=1的记录,所以报Duplicate key error,语句返回。
在这之后,再插入新的数据行时,拿到的自增id就是3。
事务回滚
1 | insert into t values(null,1,1); |
事务回滚后,自增值为什么不能回退?
假设有两个并行执行的事务,在申请自增值的时候,为了避免两个事务申请到相同的自增id,肯定要加锁,然后顺序申请。
- 每次申请id之前,先判断表里面是否已经存在这个id。如果存在,就跳过这个id。但是,这个方法的成本很高。因为,本来申请id是一个很快的操作,现在还要再去主键索引树上判断id是否存在。
- 把自增id的锁范围扩大,必须等到一个事务执行完成并提交,下一个事务才能再申请自增id。这个方法的问题,就是锁的粒度太大,系统并发能力大大下降。
这两个方法都会导致性能问题。InnoDB放弃了这个设计,语句执行失败也不回退自增id。
自增锁的优化
MySQL 5.0版本的时候,自增锁的范围是语句级别。也就是说,如果一个语句申请了一个表自增锁,这个锁会等语句执行结束以后才释放。
MySQL 5.1.22版本引入了一个新策略,新增参数innodb_autoinc_lock_mode,默认值是1。
- 这个参数的值被设置为0时,表示采用之前MySQL 5.0版本的策略,即语句执行结束后才释放锁;
- 这个参数的值被设置为1时:
- 普通insert语句,自增锁在申请之后就马上释放;
- 类似insert … select这样的批量插入数据的语句,自增锁还是要等语句结束后才被释放;
- 这个参数的值被设置为2时,所有的申请自增主键的动作都是申请后就释放锁。
为什么参数innodb_autoinc_lock_mode要设置为2?
如果有两个事务在批量新增,而批量插入过程中没有加自增锁,在binlog_format=statement的情况下,binlog里面对表t的更新日志只有两种情况:要么先记session A的,要么先记session B的。但不论是哪一种,这个binlog拿去从库执行,或者用来恢复临时实例,备库和临时实例里面,session B这个语句执行出来,生成的结果里面,id都是连续的。这时,这个库就发生了数据不一致。
因此,在生产上,尤其是有insert … select这种批量插入数据的场景时,从并发插入数据性能的角度考虑,我建议你这样设置:innodb_autoinc_lock_mode=2 ,并且 binlog_format=row.这样做,既能提升并发性,又不会出现数据一致性问题。
对于批量插入数据的语句,MySQL有一个批量申请自增id的策略:
语句执行过程中,第一次申请自增id,会分配1个;
1个用完以后,这个语句第二次申请自增id,会分配2个;
2个用完以后,还是这个语句,第三次申请自增id,会分配4个;
依此类推,同一个语句去申请自增id,每次申请到的自增id个数都是上一次的两倍。
1
2
3
4
5
6
7insert into t values(null, 1,1);
insert into t values(null, 2,2);
insert into t values(null, 3,3);
insert into t values(null, 4,4);
create table t2 like t;
insert into t2(c,d) select c,d from t;
insert into t2 values(null, 5,5);insert…select,实际上往表t2中插入了4行数据。但是,这四行数据是分三次申请的自增id,第一次申请到了id=1,第二次被分配了id=2和id=3, 第三次被分配到id=4到id=7。
由于这条语句实际只用上了4个id,所以id=5到id=7就被浪费掉了。之后,再执行insert into t2 values(null, 5,5),实际上插入的数据就是(8,5,5)。
Insert 加锁
表t和t2的表结构、初始化数据语句如下。
1 | CREATE TABLE `t` ( |
为什么在可重复读隔离级别下,binlog_format=statement时执行:
1 | insert into t2(c,d) select c,d from t; |
这个语句时,需要对表t的所有行和间隙加锁呢?
| session A | session B |
|---|---|
| insert into t values(-1,-1,-1); | insert into t2(c,d) select c,d from t; |
如果session B先执行,由于这个语句对表t主键索引加了(-∞,1]这个next-key lock,会在语句执行完成后,才允许session A的insert语句执行。
但如果没有锁的话,就可能出现session B的insert语句先执行,但是后写入binlog的情况。于是,在binlog_format=statement的情况下,binlog里面就记录了这样的语句序列:
1 | insert into t values(-1,-1,-1); |
这个语句到了备库执行,就会把id=-1这一行也写到表t2中,出现主备不一致。
insert 循环写入
执行insert … select 的时候,对目标表也不是锁全表,而是只锁住需要访问的资源。
如果现在有这么一个需求:要往表t2中插入一行数据,这一行的c值是表t中c值的最大值加1。
此时,我们可以这么写这条SQL语句 :
1 | insert into t2(c,d) (select c+1, d from t force index(c) order by c desc limit 1); |
这个语句的加锁范围,就是表t索引c上的(4,supremum]这个next-key lock和主键索引上id=4这一行。
insert 唯一键冲突
| session A | session B |
|---|---|
| insert into t values(10,10,10); | |
| begin; insert into t values(11,10,10); (Duplicate entry ‘10’ for key ‘c’) |
|
| insert into t values(12,9,9); (blocked) |
session A执行的insert语句,发生主键冲突的时候,并不只是简单地报错返回,还在冲突的索引上加了锁。这时候,session A持有索引c上的(5,10]共享next-key lock(读锁)。从作用上来看,这样做可以避免这一行被别的事务删掉。
拷贝数据
mysqldump方法
使用mysqldump命令将数据导出成一组INSERT语句。你可以使用下面的命令:
1 | mysqldump -h$host -P$port -u$user --add-locks --no-create-info --single-transaction --set-gtid-purged=OFF db1 t --where="a>900" --result-file=/client_tmp/t.sql |
- –single-transaction的作用是,在导出数据的时候不需要对表db1.t加表锁,而是使用START TRANSACTION WITH CONSISTENT SNAPSHOT的方法;
- –add-locks设置为0,表示在输出的文件结果里,不增加” LOCK TABLES
tWRITE;” ; - –no-create-info的意思是,不需要导出表结构;
- –set-gtid-purged=off表示的是,不输出跟GTID相关的信息;
- –result-file指定了输出文件的路径,其中client表示生成的文件是在客户端机器上的。
如果你希望生成的文件中一条INSERT语句只插入一行数据的话,可以在执行mysqldump命令时,加上参数–skip-extended-insert。
然后,将这些INSERT语句放到db2库里去执行。
1 | mysql -h127.0.0.1 -P13000 -uroot db2 -e "source /client_tmp/t.sql" |
需要说明的是,source并不是一条SQL语句,而是一个客户端命令。mysql客户端执行这个命令的流程是这样的:
- 打开文件,默认以分号为结尾读取一条条的SQL语句;
- 将SQL语句发送到服务端执行。
导出CSV文件
MySQL提供了下面的语法,用来将查询结果导出到服务端本地目录:
1 | select * from db1.t where a>900 into outfile '/server_tmp/t.csv'; |
我们在使用这条语句时,需要注意如下几点。
- 这条语句会将结果保存在服务端。如果你执行命令的客户端和MySQL服务端不在同一个机器上,客户端机器的临时目录下是不会生成t.csv文件的。
- into outfile指定了文件的生成位置(/server_tmp/),这个位置必须受参数secure_file_priv的限制。参数secure_file_priv的可选值和作用分别是:
- 如果设置为empty,表示不限制文件生成的位置,这是不安全的设置;
- 如果设置为一个表示路径的字符串,就要求生成的文件只能放在这个指定的目录,或者它的子目录;
- 如果设置为NULL,就表示禁止在这个MySQL实例上执行select … into outfile 操作。
- 这条命令不会帮你覆盖文件,因此你需要确保/server_tmp/t.csv这个文件不存在,否则执行语句时就会因为有同名文件的存在而报错。
- 这条命令生成的文本文件中,原则上一个数据行对应文本文件的一行。但是,如果字段中包含换行符,在生成的文本中也会有换行符。不过类似换行符、制表符这类符号,前面都会跟上“\”这个转义符,这样就可以跟字段之间、数据行之间的分隔符区分开。
select …into outfile方法不会生成表结构文件, 所以我们导数据时还需要单独的命令得到表结构定义。mysqldump提供了一个–tab参数,可以同时导出表结构定义文件和csv数据文件。这条命令的使用方法如下:
1 | mysqldump -h$host -P$port -u$user ---single-transaction --set-gtid-purged=OFF db1 t --where="a>900" --tab=$secure_file_priv |
这条命令会在$secure_file_priv定义的目录下,创建一个t.sql文件保存建表语句,同时创建一个t.txt文件保存CSV数据。
得到.csv导出文件后,你就可以用下面的load data命令将数据导入到目标表db2.t中。
1 | load data infile '/server_tmp/t.csv' into table db2.t; |
这条语句的执行流程如下所示。
- 主库执行完成后,将/server_tmp/t.csv文件的内容直接写到binlog文件中。
- 往binlog文件中写入语句load data local infile ‘/tmp/SQL_LOAD_MB-1-0’ INTO TABLE
db2.t。 - 把这个binlog日志传到备库。
- 备库的apply线程在执行这个事务日志时:
a. 先将binlog中t.csv文件的内容读出来,写入到本地临时目录/tmp/SQL_LOAD_MB-1-0 中;
b. 再执行load data语句,往备库的db2.t表中插入跟主库相同的数据
load data命令有两种用法:
- 不加“local”,是读取服务端的文件,这个文件必须在secure_file_priv指定的目录或子目录下;
- 加上“local”,读取的是客户端的文件,只要mysql客户端有访问这个文件的权限即可。这时候,MySQL客户端会先把本地文件传给服务端,然后执行上述的load data流程。
binlog_format=statement的时候,binlog记录的load data命令是带local的。既然这条命令是发送到备库去执行的,那么备库执行的时候也是本地执行,为什么需要这个local呢?如果写到binlog中的命令不带local,又会出现什么问题呢?
这样做的一个原因是,为了确保备库应用binlog正常。因为备库可能配置了secure_file_priv=null,所以如果不用local的话,可能会导入失败,造成主备同步延迟。
另一种应用场景是使用mysqlbinlog工具解析binlog文件,并应用到目标库的情况。你可以使用下面这条命令 :
1 | mysqlbinlog $binlog_file | mysql -h$host -P$port -u$user -p$pwd |
把日志直接解析出来发给目标库执行。增加local,就能让这个方法支持非本地的$host。
物理拷贝方法
在MySQL 5.6版本引入了可传输表空间(transportable tablespace)的方法,可以通过导出+导入表空间的方式,实现物理拷贝表的功能。
假设我们现在的目标是在db1库下,复制一个跟表t相同的表r,具体的执行步骤如下:
- 执行 create table r like t,创建一个相同表结构的空表;
- 执行alter table r discard tablespace,这时候r.ibd文件会被删除;
- 执行flush table t for export,这时候db1目录下会生成一个t.cfg文件;
- 在db1目录下执行cp t.cfg r.cfg; cp t.ibd r.ibd;这两个命令;
- 执行unlock tables,这时候t.cfg文件会被删除;
- 执行alter table r import tablespace,将这个r.ibd文件作为表r的新的表空间,由于这个文件的数据内容和t.ibd是相同的,所以表r中就有了和表t相同的数据。
关于拷贝表的这个流程,有以下几个注意点:
- 在第3步执行完flsuh table命令之后,db1.t整个表处于只读状态,直到执行unlock tables命令后才释放读锁;
- 在执行import tablespace的时候,为了让文件里的表空间id和数据字典中的一致,会修改t.ibd的表空间id。而这个表空间id存在于每一个数据页中。因此,如果是一个很大的文件(比如TB级别),每个数据页都需要修改,所以你会看到这个import语句的执行是需要一些时间的。当然,如果是相比于逻辑导入的方法,import语句的耗时是非常短的。
MySQL权限
1 | create user 'ua'@'%' identified by 'pa'; |
这条语句的逻辑是创建一个用户’ua’@’%’,密码是pa。注意,在MySQL里面,用户名(user)+地址(host)才表示一个用户,因此 ua@ip1 和 ua@ip2代表的是两个不同的用户。
这条命令做了两个动作:
- 磁盘上,往mysql.user表里插入一行,由于没有指定权限,所以这行数据上所有表示权限的字段的值都是N;
- 内存里,往数组acl_users里插入一个acl_user对象,这个对象的access字段值为0。
全局权限
如果我要给用户ua赋一个最高权限的话,语句是这么写的:
1 | grant all privileges on *.* to 'ua'@'%' with grant option; |
这个grant命令做了两个动作:
- 磁盘上,将mysql.user表里,用户’ua’@’%’这一行的所有表示权限的字段的值都修改为‘Y’;
- 内存里,从数组acl_users中找到这个用户对应的对象,将access值(权限位)修改为二进制的“全1”。
grant 命令对于全局权限,同时更新了磁盘和内存。命令完成后即时生效,接下来新创建的连接会使用新的权限。对于一个已经存在的连接,它的全局权限不受 grant 命令影响。
如果要回收上面的grant语句赋予的权限,你可以使用下面这条命令:
1 | revoke all privileges on *.* from 'ua'@'%'; |
db权限
如果要让用户ua拥有库db1的所有权限,可以执行下面这条命令:
1 | grant all privileges on db1.* to 'ua'@'%' with grant option; |
基于库的权限记录保存在mysql.db表中,在内存里则保存在数组acl_dbs中。这条grant命令做了如下两个动作:
- 磁盘上,往mysql.db表中插入了一行记录,所有权限位字段设置为“Y”;
- 内存里,增加一个对象到数组acl_dbs中,这个对象的权限位为“全1”。
每次需要判断一个用户对一个数据库读写权限的时候,都需要遍历一次acl_dbs数组,根据user、host和db找到匹配的对象,然后根据对象的权限位来判断。
也就是说,grant修改db权限的时候,是同时对磁盘和内存生效的。
super是全局权限,这个权限信息在线程对象中,而revoke操作影响不到这个线程对象。
表权限和列权限
表权限定义存放在表mysql.tables_priv中,列权限定义存放在表mysql.columns_priv中。这两类权限,组合起来存放在内存的hash结构column_priv_hash中。
这两类权限的赋权命令如下:
1 | create table db1.t1(id int, a int); |
flush privileges命令会清空acl_users数组,然后从mysql.user表中读取数据重新加载,重新构造一个acl_users数组。也就是说,以数据表中的数据为准,会将全局权限内存数组重新加载一遍。
正常情况下,grant命令之后,没有必要跟着执行flush privileges命令。
flush privileges使用场景:当数据表中的权限数据跟内存中的权限数据不一致的时候,flush privileges语句可以用来重建内存数据,达到一致状态。而这种不一致往往是由于直接用DML语句操作系统权限表导致的,所以我们尽量不要使用这类语句。
分区表
先创建一个表t:
1 | CREATE TABLE `t` ( |
我在表t中初始化插入了两行记录,按照定义的分区规则,这两行记录分别落在p_2018和p_2019这两个分区上。
可以看到,这个表包含了一个.frm文件和4个.ibd文件,每个分区对应一个.ibd文件。也就是说:
- 对于引擎层来说,这是4个表;
- 对于Server层来说,这是1个表。
分区表的引擎层行为
初始化表t的时候,只插入了两行数据, ftime的值分别是,‘2017-4-1’ 和’2018-4-1’ 。
| session A | session B | |
|---|---|---|
| T1 | begin; select * from t where ftime=’2017-5-1’ for update; |
|
| T2 | insert into t values(‘2018-2-1’,1); (Query OK) insert into t values(‘2017-12-1’,1); (blocked) |
session A的select语句对索引ftime上这两个记录之间的间隙加了锁,(‘2017-4-1’,’2018-4-1’),sesion B的两条插入语句应该都要进入锁等待状态。
但实际上,session B的第一个insert语句是可以执行成功的。这是因为,对于引擎来说,p_2018和p_2019是两个不同的表,也就是说2017-4-1的下一个记录并不是2018-4-1,而是p_2018分区的supremum。
所以T1时刻,在表t的ftime索引上,间隙和加锁的状态是 p_2018 表上的 (2017-4-1,supremum),session B要写入一行ftime是2018-2-1的时候是可以成功的,而要写入2017-12-1这个记录,就要等session A的间隙锁。
分区策略
使用MyISAM引擎时,每当第一次访问一个分区表的时候,MySQL需要把所有的分区都访问一遍。一个典型的报错情况是这样的:如果一个分区表的分区很多,比如超过了1000个,而MySQL启动的时候,open_files_limit参数使用的是默认值1024,那么就会在访问这个表的时候,由于需要打开所有的文件,导致打开表文件的个数超过了上限而报错。
MyISAM分区表使用的分区策略,我们称为通用分区策略(generic partitioning),每次访问分区都由server层控制。通用分区策略,是MySQL一开始支持分区表的时候就存在的代码,在文件管理、表管理的实现上很粗糙,因此有比较严重的性能问题。
从MySQL 5.7.9开始,InnoDB引擎引入了本地分区策略(native partitioning)。这个策略是在InnoDB内部自己管理打开分区的行为。
从MySQL 8.0版本开始,就不允许创建MyISAM分区表了,只允许创建已经实现了本地分区策略的引擎。目前来看,只有InnoDB和NDB这两个引擎支持了本地分区策略。
分区表的server层行为
- MySQL在第一次打开分区表的时候,需要访问所有的分区;
- 在server层,认为这是同一张表,因此所有分区共用同一个MDL锁;
- 在引擎层,认为这是不同的表,因此MDL锁之后的执行过程,会根据分区表规则,只访问必要的分区。
分区表的应用场景
如果一项业务跑的时间足够长,往往就会有根据时间删除历史数据的需求。这时候,按照时间分区的分区表,就可以直接通过alter table t drop partition …这个语法删掉分区,从而删掉过期的历史数据。
这个alter table t drop partition …操作是直接删除分区文件,效果跟drop普通表类似。与使用delete语句删除数据相比,优势是速度快、对系统影响小。
假设现在要创建一个自增字段id。MySQL要求分区表中的主键必须包含分区字段。如果要在表t的基础上做修改,你会怎么定义这个表的主键呢?为什么这么定义呢?
由于MySQL要求主键包含所有的分区字段,所以肯定是要创建联合主键的。
两种方案:一种是(ftime, id),另一种是(id, ftime)。
如果从利用率上来看,应该使用(ftime, id)这种模式。因为用ftime做分区key,说明大多数语句都是包含ftime的,使用这种模式,可以利用前缀索引的规则,减少一个索引。




