
浅谈RocketMQ负载均衡策略
消息队列存在生产者和消费者,其中RocketMQ的生产者和消费者都有分组。
生产者负载均衡
生产者发送消息到RocketMQ时,RocketMQ将根据生产者负载均衡将消息均匀存储在多个队列中。
- 同步刷盘,只有在消息真正持久化至磁盘后RocketMQ的Broker端才会真正返回给Producer端一个成功的ACK响应。同步刷盘对MQ消息可靠性来说是一种不错的保障,但是性能上会有较大影响,一般适用于金融业务应用该模式比较多。
- 异步刷盘:能够充分利用OS的PageCache的优势,只要消息写入PageCache即可成功的将ACK返回给Producer端。消息刷盘采用后台异步线程提交的方式进行,降低了读写延迟,提高了MQ的性能和吞吐量。
RoundRobin模式
对于非顺序消息(普通消息、定时/延时消息、事务消息),默认且只能使用RoundRobin模式。
生产者发送消息时,以消息为粒度,按照轮询方式将消息发送到指定主题中的所有可写目标队列中,保证消息尽可能均衡分布到所有队列。
故障规避策略
当生产者某条消息发送失败时,RocketMQ会决定在接下来一段事件内,跳过本地失败队列所在节点,实现自适应的故障转移。
该参数由 sendLatencyFaultEnable 控制,用户可干预,表示是否开启延迟规避机制,默认为不开启。
- sendLatencyFaultEnable 设置为 false:默认值,不开启,延迟规避策略只在重试时生效,例如在一次消息发送过程中如果遇到消息发送失败,规避 broekr-a,但是在下一次消息发送时,即再次调用 DefaultMQProducer 的 send 方法发送消息时,还是会选择 broker-a 的消息进行发送,只要继续发送失败后,重试时再次规避 broker-a。
- sendLatencyFaultEnable 设置为 true:开启延迟规避机制,一旦消息发送失败会将 broker-a “悲观”地认为在接下来的一段时间内该 Broker 不可用,在为未来某一段时间内所有的客户端不会向该 Broker 发送消息。这个延迟时间就是通过 notAvailableDuration、latencyMax 共同计算的,就首先先计算本次消息发送失败所耗的时延,然后对应 latencyMax 中哪个区间,即计算在 latencyMax 的下标,然后返回 notAvailableDuration 同一个下标对应的延迟值。
按照笔者的实践经验,RocketMQ Broker 的繁忙基本都是瞬时的,而且通常与系统 PageCache 内核的管理相关,很快就能恢复,故不建议开启延迟机制。因为一旦开启延迟机制,例如 5 分钟内不会向一个 Broker 发送消息,这样会导致消息在其他 Broker 激增,从而会导致部分消费端无法消费到消息,增大其他消费者的处理压力,导致整体消费性能的下降。
MessageGroupHash模式
对于顺序消息场景,默认且只能使用MessageGroupHash模式的负载均衡策略。
生产者发送消息时,以消息组为粒度,按照内置的Hash算法,将相同消息组的消息分配到同一队列中,保证同消息组的消息按照发送的先后顺序存储。
使用建议
- 避免出现热点队列:如果业务侧将消息集中在少量或唯一的的消息组,则服务端存储消息时,也会集中存储在少量或唯一的队列中。不利于水平扩展。建议在设计消息组时,尽量将消息分散开。例如采用较离散的订单ID、用户名作为消息组的关键字,既能保证消息被分散到多个消息组中,又能保证统一终端用户的消息按顺序处理。
- 避免绑定单队列发送:单队列容易产生性能瓶颈和容灾风险。
消费者负载均衡
消费者消费RocketMQ上的消息时,可通过消费者负载均衡策略,将主题内的消息分配给指定消费者分组中多个消费者共同分担。
广播消费
每个消费者分组只初始化唯一一个消费者,每个消费者可消费到消费者分组内所有的消息,各消费者分组都订阅相同的消息,以此实现单客户端级别的广播一对多推送效果。
通俗点讲,就是消费者分组内唯一的消费者消费了分组内所有的消息。这个场景下其实不涉及消费者的负载均衡,因为只有一个消费者在消费。
该方式一般可用于网关推送、配置推送等场景。
共享消费
每个消费者分组下初始化了多个消费者,这些消费者共同分担消费者分组内的所有消息,实现消费者分组内流量的水平拆分和均衡负载。
通俗点讲,就是消费者分组内所有消费者共同消费了分组内所有的消息。
该方式一般可用于微服务解耦场景。
消息粒度负载均衡
对于PushConsumer和SimpleConsumer类型的消费者,默认且仅使用消息粒度负载均衡策略。
同一个队列中的消息,可被平均分配给多个消费者共同消费。
那消息粒度负载均衡性是怎么保证消息不被重复消费的呢?
消息粒度的负载均衡机制,是基于内部的单条消息确认语义实现的。消费者获取某条消息后,服务端会将该消息加锁,保证这条消息对其他消费者不可见,直到该消息消费成功或消费超时。因此,即使多个消费者同时消费同一队列的消息,服务端也可保证消息不会被多个消费者重复消费。
队列粒度负载均衡
对于历史版本(服务端4.x/3.x版本)的消费者,包括PullConsumer、DefaultPushConsumer、DefaultPullConsumer、LitePullConsumer等,默认且仅能使用队列粒度负载均衡策略。
在该策略下,同一消费者分组内的多个消费者讲按照队列粒度消费消息,即每个队列仅被一个消费者消费。
适用场景
队列粒度负载均衡策略适用于流式计算、数据聚合等需要明确对消息进行聚合、批处理的场景。
消息消费队列负载算法
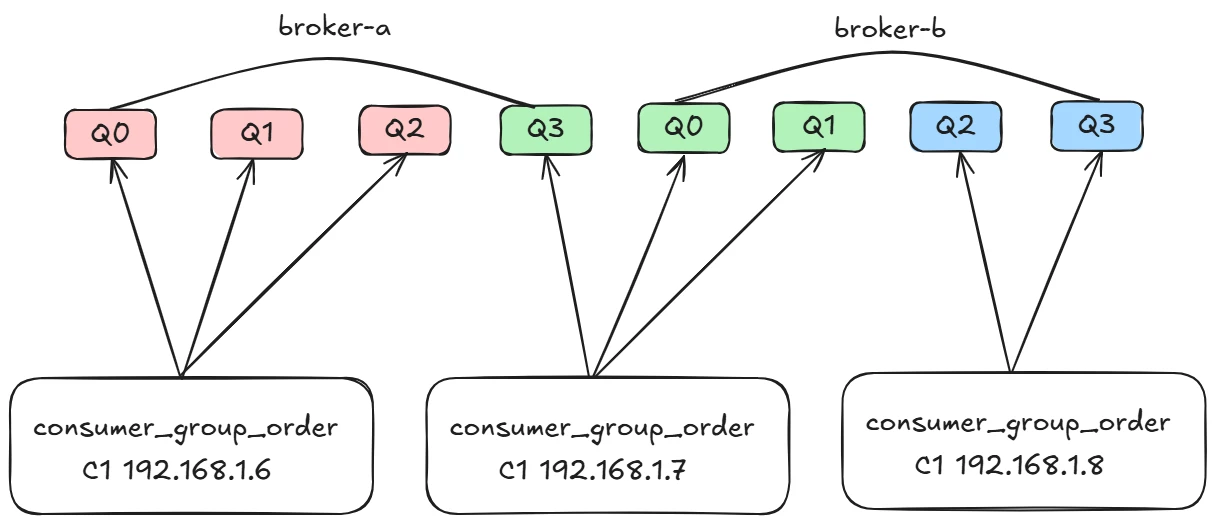
AllocateMessageQueueAveragely
平均连续分配算法。主要的特点是一个消费者分配的消息队列是连续的。
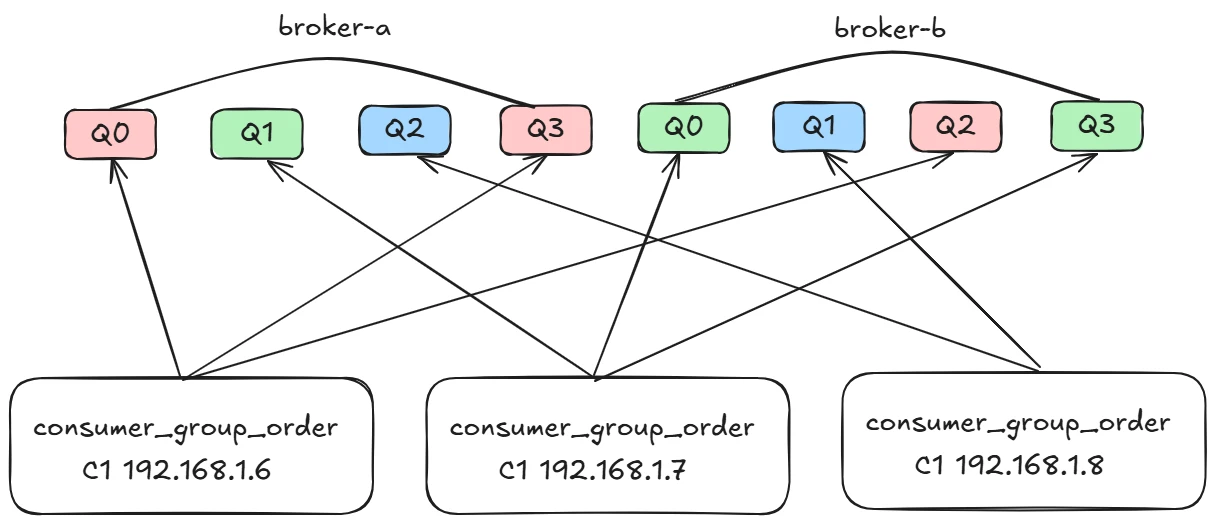
AllocateMessageQueueAveragelyByCircle
平均轮流分配算法,其分配示例图如下:
AllocateMachineRoomNearby
机房内优先就近分配。其分配示例图如下:
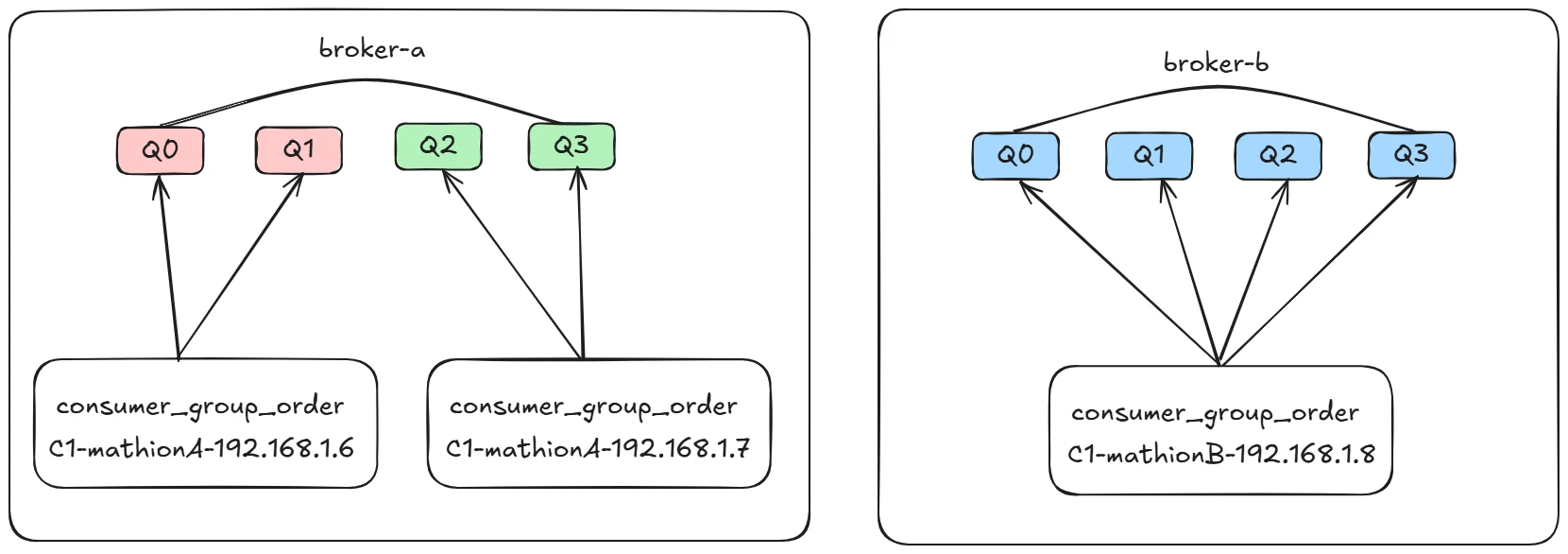
上述的背景是一个 MQ 集群的两台 Broker 分别部署在两个不同的机房,每一个机房中都部署了一些消费者,其队列的负载情况是同机房中的消费队列优先被同机房的消费者进行分配,其分配算法可以指定其他的算法,例如示例中的平均分配,但如果机房 B 中的消费者宕机,B 机房中没有存活的消费者,那该机房中的队列会被其他机房中的消费者获取进行消费。
AllocateMessageQueueByConfig
手动指定,这个通常需要配合配置中心,在消费者启动时,首先先创建 AllocateMessageQueueByConfig 对象,然后根据配置中心的配置,再根据当前的队列信息,进行分配,即该方法不具备队列的自动负载,在 Broker 端进行队列扩容时,无法自动感知,需要手动变更配置。
AllocateMessageQueueByMachineRoom
消费指定机房中的队列,该分配算法首先需要调用该策略的 setConsumeridcs(Set<String> consumerIdCs) 方法,用于设置需要消费的机房,将刷选出来的消息按平均连续分配算法进行队列负载,其分配示例图如下所示:
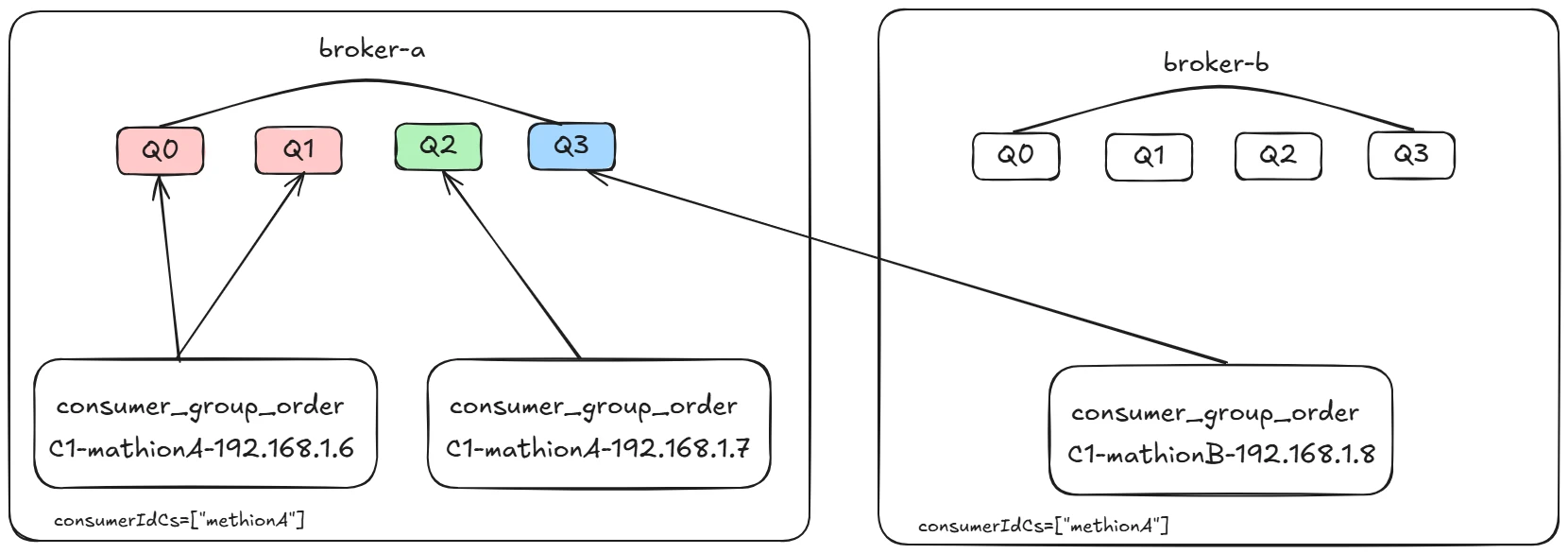
由于设置 consumerIdCs 为 A 机房,故 B 机房中的队列并不会消息。
AllocateMessageQueueConsistentHash
一致性 Hash 算法,讲真,在消息队列负载这里使用一致性算法,没有任何实际好处,一致性 Hash 算法最佳的使用场景用在 Redis 缓存的分布式领域最适宜。




